
NVIDIA는 2026년 6월 4일 Nemotron 3 Ultra를 출시했습니다 — 자사 최대 오픈 웨이트 모델이자 미국 오픈 릴리스의 새로운 최고 기록입니다. 에이전트 하네스에 연결하기 전에, 실제로 공개된 내용과 리더보드 위치를 정확히 살펴보겠습니다.
6월 4일 NVIDIA가 공개한 내용: 스펙과 리더보드 순위
Nemotron 3 Ultra는 5,500억 파라미터 규모의 하이브리드 Mamba-Transformer 혼합전문가(MoE) 모델로, 토큰당 활성 파라미터는 약 550억(약 90% 희소성)이며 2026년 6월 4일 NVIDIA가 공개했습니다 . Nemotron 3 패밀리(Nano·Super·Ultra) 중 최상위 모델로, 100만 토큰 컨텍스트 윈도우를 지원하며 NVIDIA Blackwell 아키텍처 위에서 NVFP4(4비트 부동소수점)로 학습되었고, 하드웨어 인식 전문가 라우터인 "LatentMoE"를 채택했습니다 . Hermes Agent, LangChain Deep Agents, OpenHands, OpenCode 등 에이전트 하네스에 특화된 후훈련(post-training)이 적용되었습니다 .
Artificial Analysis Intelligence Index에서 Ultra는 48점을 기록해 현재까지 미국 랩의 오픈 모델 중 가장 높은 성능을 보였지만, 중국 주도의 Kimi K2.6과 Anthropic의 Opus 4.8 같은 클로즈드 모델에는 미치지 못합니다 :
| 모델 | 유형 | 인텔리전스 인덱스 |
|---|---|---|
| Opus 4.8 (Anthropic) | 클로즈드 | 61 |
| Kimi K2.6 | 오픈 (중국) | 54 |
| Nemotron 3 Ultra | 오픈 (미국) | 48 |
더 주목할 만한 점은 속도입니다. Artificial Analysis는 NVIDIA와 협력해 BF16 가중치를 평가한 결과, 프리릴리스 DeepInfra 엔드포인트에서 초당 300토큰 이상을 측정했으며, 이는 DeepSeek·Moonshot 등 유사 규모의 중국 오픈 모델 대비 약 50–100 tok/s를 크게 상회하는 수치입니다 .
"Nemotron 3 Ultra는 우리가 '가장 매력적인 지능-속도 사분면'이라 부르는 영역에 안착했습니다." — Artificial Analysis (source: Artificial Analysis).
정식 서비스는 build.nvidia.com(NIM 마이크로서비스), Hugging Face, OpenRouter, ModelScope, 클라우드 파트너사를 통해 제공됩니다 . 이 가이드의 나머지 부분에서는 실제로 동작하는 호출 방법을 다룹니다.
Ultra 호출 전 확인사항: NGC 인증, 최소 컴퓨팅 요건, 체크포인트 선택
첫 Ultra 호출을 위해 세 가지를 갖춰야 합니다: 계정, 적합한 하드웨어, 그리고 올바른 체크포인트. build.nvidia.com을 이용하려면 NVIDIA NGC 계정과 API 키가 필요하며, 무료 티어로 소규모 프로토타이핑이 가능합니다. OpenRouter는 대체 경로로 자체 계정 키를 사용합니다 — 둘 중 하나만 선택하세요.
컴퓨팅 최저 요건에 주의하세요. NVIDIA는 Ultra Base를 GB200 NVL72 기준으로 벤치마킹했으며, 더 작은 Nemotron 3 Super(총 1,200억 / 활성 120억)도 최소 8×H100-80GB를 요구합니다 . 5,500억 Ultra는 그보다 크므로, 데이터센터 하드웨어나 호스티드 엔드포인트를 계획하세요 — 워크스테이션으로는 불가합니다.
마지막으로, Ultra Base가 아닌 후훈련된 instruct 체크포인트를 사용하세요. NVIDIA 공식 Base 사용 가이드에 따르면 베이스 가중치는 인스트럭션 튜닝 및 정렬 과정을 거치지 않았으며, 즉시 사용 가능한 어시스턴트가 아닙니다 . Ultra의 최종 공개 모델 슬러그는 6월 4일 출시 전 Build/NIM API 목록에 없었으므로, 코드를 작성하기 전에 라이브 모델 카드에서 정확한 식별자를 확인하세요.
Hosted NIM 또는 OpenRouter로 Ultra 호출하기
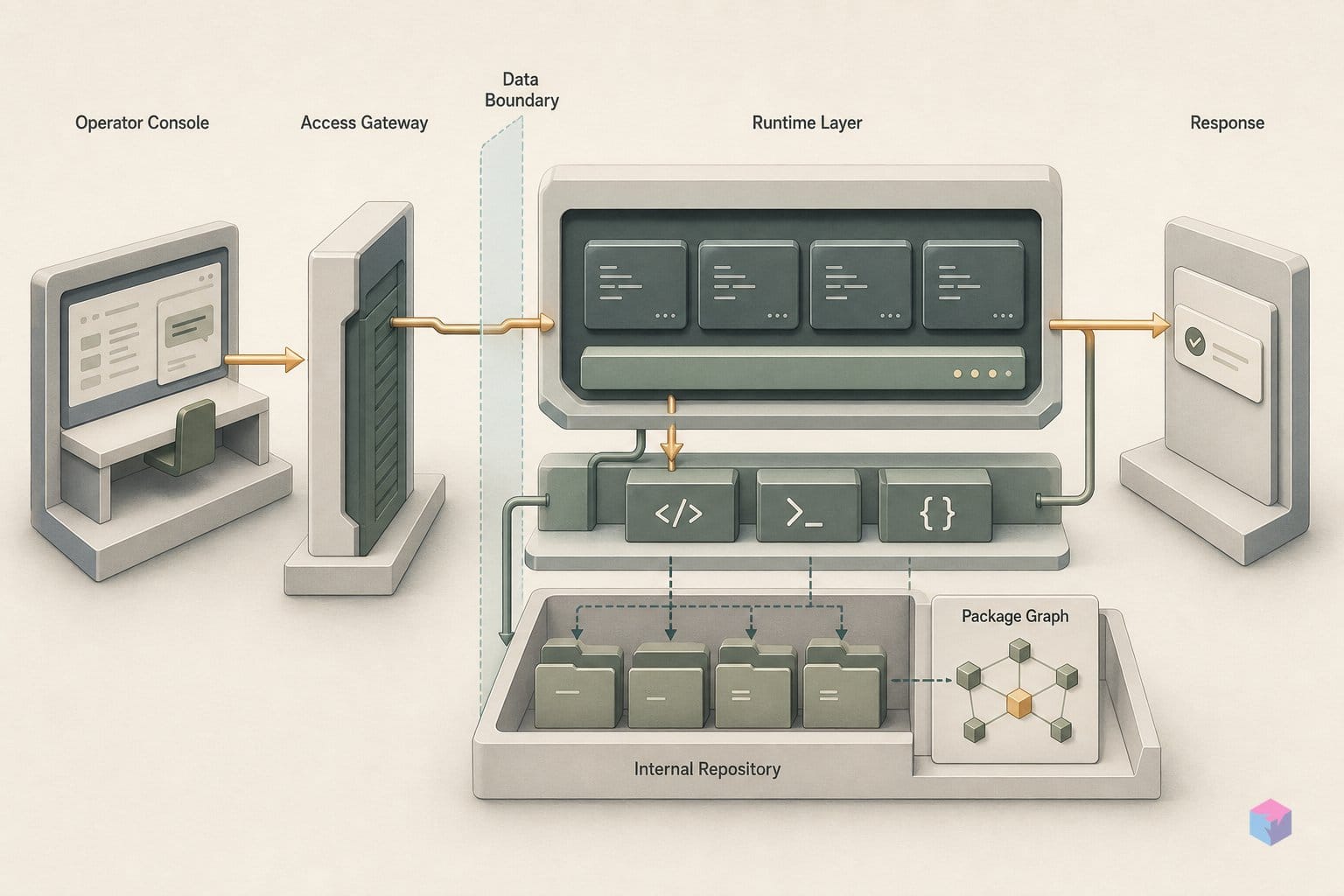
Nemotron 3 Ultra를 가장 빠르게 호출하는 방법은 OpenAI 호환 Chat Completions API입니다. 세 가지 전달 경로 모두 동일한 클라이언트를 사용하며, base_url과 model 슬러그만 바뀝니다. NVIDIA는 2026년 6월 4일 build.nvidia.com NIM 마이크로서비스, OpenRouter, Hugging Face를 통해 Ultra를 출시합니다 . 관리형 추론, NGC 없이 사용할 수 있는 대안, 또는 자체 호스팅 컨테이너 중 무엇이 필요한지에 따라 경로를 선택하세요.
경로 1 — build.nvidia.com (Hosted NIM). NGC API 키를 발급한 뒤, base_url="https://integrate.api.nvidia.com/v1"과 api_key=<NGC key>로 표준 OpenAI Python 클라이언트를 초기화합니다. model=에는 라이브 Ultra 모델 카드에 표시된 정확한 슬러그를 지정하고, 스트리밍을 활성화한 뒤 응답에서 토큰을 읽습니다. Nemotron 3 Super Build 페이지에서 확인된 패턴은 동일한 클라이언트에 nvidia/nemotron-3-super-120b-a12b와 같은 슬러그를 사용하고, 스트리밍된 reasoning_content 청크를 수신합니다 .
아래 예시 코드는 최소한의 HTTP 호출 방식을 보여줍니다(실제 실행에는 유효한 키와 최종 슬러그가 필요합니다):
import json
import os
import urllib.request
api_key = os.environ.get("NVIDIA_API_KEY")
if not api_key:
raise SystemExit("Set NVIDIA_API_KEY")
payload = {
"model": "nvidia/nemotron-3-ultra",
"messages": [{"role": "user", "content": "Say hello in one sentence."}],
"max_tokens": 64,
"stream": False,
}
req = urllib.request.Request(
"https://integrate.api.nvidia.com/v1/chat/completions",
data=json.dumps(payload).encode(),
headers={
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
"Accept": "application/json",
},
)
with urllib.request.urlopen(req, timeout=30) as r:
data = json.load(r)
print(data["choices"][0]["message"]["content"])경로 2 — OpenRouter. 클라이언트 코드는 동일하지만, base_url을 https://openrouter.ai/api/v1로 지정하고 OpenRouter 키를 사용합니다. NGC 자격증명이 필요 없으므로, NIM 슬러그가 전 리전에 전파되는 동안 유용한 대안이 됩니다 .
경로 3 — 자체 호스팅 NIM 컨테이너. NGC 자격증명으로 docker login nvcr.io를 실행한 뒤, docker run --gpus all -p 8000:8000 <NIM image>로 컨테이너를 기동하고 http://0.0.0.0:8000/v1/chat/completions에 표준 메시지 페이로드를 POST합니다 .
추론 기본값은 Ultra 모델 카드에 별도 명시가 없는 한, 공개된 Nemotron 3 Super 모델 카드 값을 그대로 사용하세요. 추론, 툴 호출, 일반 대화 모두 temperature=1.0, top_p=0.95를 권장합니다. 확장 추론은 chat-template kwargs의 enable_thinking=True/False로 전환하며, 추론 토큰은 스트리밍된 각 청크의 reasoning_content 필드로 수신됩니다 .
꼭 알아야 할 함정: Base vs. Instruct 체크포인트, 컴퓨트 한계, 슬러그 지연
놓치면 시간을 크게 낭비하는 함정이 세 가지 있습니다. 첫 번째는 체크포인트 자체입니다. NVIDIA Ultra Base 사용 가이드에 따르면, 총 550B 파라미터 / 최대 55B 활성 파라미터의 하이브리드 Mamba-Transformer MoE 체크포인트는 인스트럭션 튜닝이나 후처리 정렬을 거치지 않았으며, 도메인 파인튜닝 및 RL의 시작점으로 설계된 것이지 즉시 사용 가능한 어시스턴트가 아닙니다 . Base를 챗봇으로 직접 호출하면 일관성 없는 출력이 나옵니다. 파이프라인에 연결하기 전에 후처리된 모델 카드가 나올 때까지 기다리세요.
두 번째는 컴퓨트입니다. NVIDIA가 공개한 모든 처리량 수치는 GB200 NVL72 기준이며, 더 작은 Super(120B/12B 활성)도 최소 8×H100-80GB를 요구하므로, 풀 Ultra는 멀티 GPU 데이터센터급 워크로드입니다 . DGX Spark(GB10 SoC, 128GB 통합 메모리)는 Nano 및 양자화된 Super 티어를 대상으로 하며 Ultra에는 해당되지 않습니다 . Ultra의 비용 절감 경로로 예정된 NVFP4는 Blackwell 클래스 실리콘이 필요합니다. Ampere 또는 Hopper 클러스터에서는 FP4 절감 효과를 누릴 수 없으므로, 실제 토큰당 비용은 NVIDIA의 공식 수치보다 높게 나옵니다 .
세 번째는 슬러그 지연입니다. 출시 전 확인된 일부 페이지에서 Hugging Face의 NVIDIA 프로필은 Ultra를 아직 개발 중으로 표시하고 있었습니다 . 서드파티 블로그에서 모델 슬러그를 복사하지 마세요. 반드시 라이브 모델 카드를 확인하고 정확한 문자열을 그대로 사용하세요.
호출 그 이후: SFT 레시피, 복합 오케스트레이션, 독립 평가
호출이 잘 작동한다면, 더 깊은 가치는 후처리와 오케스트레이션에 있습니다. NVIDIA-NeMo/Nemotron 저장소는 Pretrain → SFT → RL 전체 파이프라인을 제공합니다. 도메인 특화 변형을 만드는 팀이라면 training/ 아래의 SFT 레시피와 usage-cookbook/의 툴 호출 및 RAG 패턴부터 시작하세요. NVIDIA가 권장하는 토폴로지는 비용을 낮추는 방향입니다. 어려운 코딩이나 리서치 단계에서는 Ultra를 플래너/추론기로 활용하고, 인식·라우팅·요약에는 더 저렴한 Nano 또는 Super 서브에이전트를 배치하세요 (source: DataCamp, 2026).
두 가지 벤더 수치는 자체 코퍼스에서 검증이 필요합니다. Nemotron 2 Nano 대비 추론 토큰 60% 감소와 PinchBench 에이전트 생산성 점수 91%가 그것입니다. 6월 4일 가중치와 엔드포인트가 공개되어 직접 측정할 수 있을 때까지 두 수치 모두 가설로 취급하세요. 핵심은 이렇습니다. 호스팅 호출은 지금 바로 시작하되, 비용과 정확도 주장은 직접 평가를 마친 뒤에야 Ultra를 프로덕션에 연결하세요.
자주 묻는 질문
Nemotron 3 Ultra는 2026년 6월 4일에 API로 이용할 수 있나요?
네. NVIDIA는 Ultra가 2026년 6월 4일에 정식 출시된다고 밝혔으며 , build.nvidia.com의 NIM 마이크로서비스, OpenRouter, Hugging Face, 그리고 일부 클라우드 파트너사를 통해 호스팅됩니다 . 가장 빠르게 시작하려면 NGC API 키를 발급받은 뒤, Ultra 공식 페이지에 명시된 정확한 모델 슬러그를 사용해 https://integrate.api.nvidia.com/v1의 OpenAI 호환 Chat Completions 엔드포인트를 호출하면 됩니다.
Ultra Base 체크포인트와 인스트럭트 모델의 차이는 무엇인가요?
Ultra Base는 정렬이 적용되지 않은 사전 학습 체크포인트로, 총 550B 파라미터에 활성 파라미터 최대 55B인 하이브리드 Mamba-Transformer MoE 구조입니다. SFT 및 RL 사후 학습의 출발점으로 설계된 것이며, 즉시 사용 가능한 어시스턴트가 아닙니다. NVIDIA의 공식 사용 가이드는 Base 체크포인트가 인스트럭션 튜닝이나 정렬 사후 학습을 거치지 않았으며 프로덕션 즉시 투입 용도가 아님을 명시하고 있습니다 . 채팅·추론·툴 호출 용도라면 모델 카드가 공개된 이후 사후 학습된 인스트럭트 버전을 사용하세요.
Nemotron 3 Ultra를 DGX Spark나 단일 H100에서 실행할 수 있나요?
아니요. NVIDIA는 Ultra의 처리량을 GB200 NVL72 플랫폼 기준으로 측정했으며, 더 작은 Super(120B/12B 활성)조차 최소 8×H100-80GB를 요구합니다. 따라서 Ultra는 현실적으로 멀티 GPU 또는 데이터센터급 하드웨어가 필요합니다 . DGX Spark(GB10 SoC, 128GB 통합 메모리)는 Nano 및 양자화된 Super 티어를 대상으로 하며, 풀 Ultra는 지원하지 않습니다 . 해당 클러스터 환경이 없다면 호스팅 엔드포인트를 이용하세요.
벤치마크에서 Nemotron 3 Ultra는 비공개 프런티어 모델과 어떻게 비교되나요?
Artificial Analysis는 2026년 6월 기준 Intelligence Index에서 Ultra에 48점을 부여해 미국 오픈 웨이트 모델 중 가장 뛰어난 모델로 평가했으며, Gemma 4 31B(39점)와 Nemotron 3 Super(36점)를 앞섭니다 . 다만 중국 오픈 웨이트 모델인 Kimi K2.6(54점)과 Anthropic의 Opus 4.8(61점) 같은 비공개 모델에는 여전히 뒤처집니다 . Ultra는 미국 오픈 웨이트 분야를 선도하지만, 비공개 모델 프런티어에는 미치지 못합니다.
Nemotron 3 Ultra 호출 시 어떤 추론 기본값을 사용해야 하나요?
Ultra 전용 모델 카드가 확정되기 전까지는 Nemotron 3 Super 카드에 문서화된 기본값이 가장 신뢰할 수 있습니다: 추론·툴 호출·일반 채팅 전 영역에서 temperature=1.0, top_p=0.95를 사용하세요 . 확장 추론은 chat-template kwargs의 enable_thinking=True/False로 전환하며, 추론 토큰은 reasoning_content 필드로 스트리밍됩니다. 6월 4일 가중치가 공개되면 실제 워크로드에 맞게 검증해 보세요.









