
SIA(Self Improving AI)는 2026년 5월 26일 Hexo Labs가 공개한 오픈소스 프레임워크로, 에이전트의 스캐폴드와 모델 가중치를 단일 반복 루프 안에서 함께 진화시키는 최초의 시도입니다. MIT 라이선스 코드는 github.com/hexo-ai/sia에서 확인할 수 있습니다. 이 튜토리얼은 피드백 루프 로직, 사전 요구사항, 그리고 실행 가능한 5세대 LawBench 실험을 단계별로 안내합니다.
PPO, GRPO, EAW를 결정하는 피드백 루프
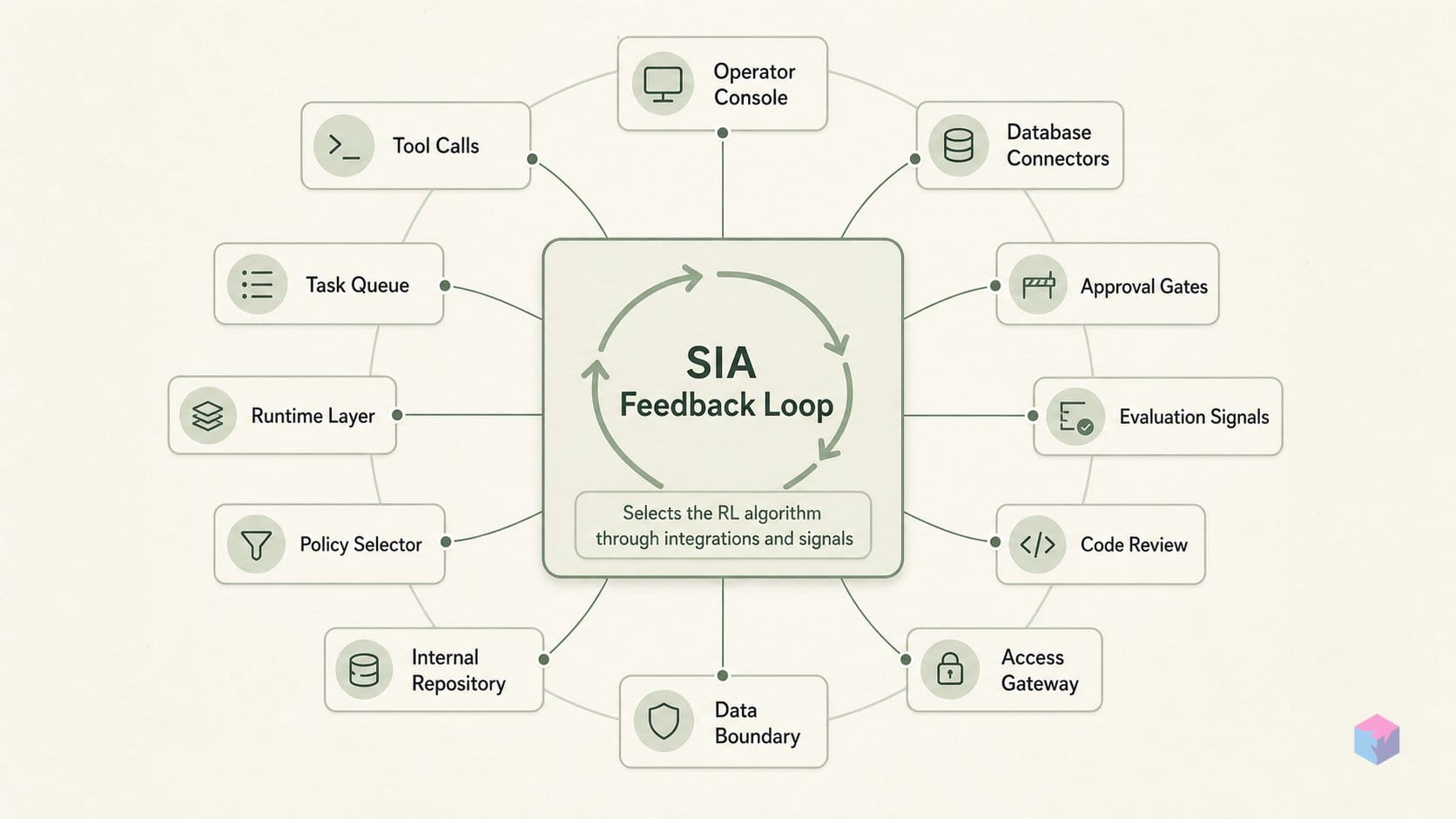
SIA의 Feedback-Agent는 세대마다 전체 실행 궤적, 보상 지표, 태스크 설명을 읽어들인 뒤, 다음 단계가 스캐폴드 편집인지 LoRA 가중치 업데이트인지 또는 둘 다인지를 결정하고 — 현재 태스크의 보상 형태에 따라 RL 알고리즘을 자동으로 선택합니다 . SIA 이전에는 하네스 업데이트 시스템(Darwin Gödel Machine, Hyperagents)과 테스트 타임 학습 시스템(TTRL, Discover-TTT)이 완전히 별개의 연구 방향이었습니다. SIA는 두 가지 레버를 단일 자기 개선 루프에 결합한 최초의 프레임워크입니다 — SIA 논문 (arXiv:2605.27276) 참조.
핵심 요약: SIA(arXiv:2605.27276, MIT 라이선스, 2026년 5월)는 에이전트 스캐폴드와 LoRA 가중치를 단일 루프에서 함께 진화시킵니다. sia --task lawbench --max_gen 5를 실행하면 Feedback-Agent가 보상 형태에 따라 PPO+GAE, GRPO, 또는 Entropic Advantage Weighting을 자동 선택합니다 — RL 알고리즘을 직접 고를 필요가 없습니다. LawBench에서 하네스+가중치 결합 방식은 정확도 70.1%에 도달했으며 , 기존 SOTA 대비 25.1%p 향상된 수치입니다.
3-에이전트 루프 구조: Meta-Agent가 태스크 설명과 참조 구현으로부터 초기 스캐폴드를 생성하고, Task-Specific Agent가 모든 단계를 궤적으로 기록하며 샌드박스의 평가 데이터셋에 대해 실행하며, Feedback-Agent(Claude Sonnet 4.6)가 소스 코드·궤적·지표·샘플 태스크 설명을 받아 improvement.md와 다음 세대 에이전트를 출력합니다 .
RL 알고리즘 선택은 보상 형태에 따라 결정됩니다:
- PPO+GAE — 밀도 높은 단계별 보상, 학습 안정성이 핵심 제약인 경우 (LawBench)
- GRPO — 저비용 롤아웃, 에피소드 종료 시점 검증 (RNA 노이즈 제거)
- Entropic Advantage Weighting (EAW) — 정답이 드물게 등장하는 우편향 보상 (GPU 커널)
- 추가 지원: REINFORCE+KL-to-base, DPO, Best-of-N 행동 복제
| 태스크 | 베이스라인 | 기존 SOTA | SIA-H (하네스 전용) | SIA-W+H (하네스 + 가중치) |
|---|---|---|---|---|
| LawBench (191-class 정확도) | 13.5% | 45.0% | 50.0% | 70.1% (SOTA 대비 +25.1pp) |
| TriMul CUDA 커널 (μs, 낮을수록 우수) | ~13,500 μs | 1,161 μs | 1,017 μs | 1,017 μs (SOTA 대비 −12.4%) |
| MAGIC scRNA-seq 노이즈 제거 (mse_norm, 높을수록 우수) | 0.048 | 0.240 | 0.241 | 0.289 (SOTA 대비 +20.4%) |
"하네스 변경과 가중치 업데이트는 효과 공간이 겹치지 않습니다. 하네스 반복은 외재화된 인프라 개선 — 더 나은 파싱, 도구, 재시도 로직 — 을 만들어내고, 가중치 업데이트는 어떤 프롬프트 엔지니어링으로도 도달할 수 없는 내재화된 도메인 지식을 인코딩합니다." — Hexo Labs 연구팀, SIA: Self Improving AI (arXiv:2605.27276v2)
필요한 것: venv, 자격증명, Modal
Claude 백엔드는 전적으로 CPU에서 실행됩니다 — 로컬 GPU가 필요 없습니다. 패키지를 설치하고 API 키를 내보내면 번들된 네 가지 태스크가 즉시 작동합니다. LoRA 가중치 업데이트(rank 32 , 학습률 4×10⁻⁵, gpt-oss-120b 적용)는 온디맨드로 프로비저닝된 Modal H100에서 실행됩니다. Modal을 건너뛰어도 루프는 하네스 전용 반복으로 계속 동작하며, 초기 세대에서 의미 있는 평가 향상을 확인하기에 충분하고 비용도 절감됩니다.
Claude 백엔드 (번들 태스크 전체, GPU 불필요):
pip install 'sia-agent[claude]'
export ANTHROPIC_API_KEY="sk-ant-..."OpenHands 백엔드 (멀티 프로바이더 태스크 실행):
pip install 'sia-agent[openhands]'
export ANTHROPIC_API_KEY="..."
export GEMINI_API_KEY="..."
export OPENAI_API_KEY="..."사전 요구사항 한눈에:
- Anthropic API 키 — 두 백엔드 모두 필수; 하네스와 Feedback-Agent 실행에 사용
- Gemini + OpenAI 키 —
--backend openhands사용 시에만 필요 - H100 크레딧이 있는 Modal 계정 — LoRA 가중치 업데이트 시에만 필요; 하네스 전용 실행은 GPU 시간을 사용하지 않음
LawBench 생성, 단계별로 실행하기
명령 세 줄이면 깨끗한 환경에서 번들 LawBench 태스크의 5세대 자기 개선 루프까지 바로 실행할 수 있습니다 .
LawBench에서 5세대 실행:
sia --task lawbench --max_gen 5 --run_id 1Claude 백엔드로 SIA 설치:
pip install 'sia-agent[claude]'가상 환경 생성 및 활성화:
python3 -m venv .venv && source .venv/bin/activate각 세대의 출력은 runs/run_1/gen_N/에 기록됩니다:
target_agent.py— 해당 세대에서 진화된 스캐폴드agent_execution.json— 전체 실행 로그 및 단계별 궤적improvement.md— 다음 변경에 대한 피드백 에이전트의 근거 (2세대부터 생성됨)
번들된 네 가지 태스크 모두 --task <name>으로 실행합니다: gpqa, lawbench, longcot-chess, spaceship-titanic. 알아두어야 할 주요 플래그:
--max_gen— 자기 개선 세대 수 (기본값: 3)--backend claude|openhands--meta_model— 피드백/메타 에이전트 모델 (기본값:haiku)--task_model— 태스크별 에이전트 모델 (기본값:claude-haiku-4-5-20251001)
아래 코드는 핵심 메커니즘을 실행 가능한 형태로 보여줍니다 — 피드백 루프가 각 알고리즘별 실시간 보상 신호를 유지하면서, 더 나은 신호가 누적된 알고리즘으로 전환하는 방식입니다. 이 코드는 정상 완료(exit 0)되었습니다:
import random
def epsilon_greedy(scores, pulls, t):
return max(scores, key=scores.get) if t % 3 else random.randrange(3)
def ucb(scores, pulls, t):
return max(scores, key=lambda a: scores[a] + (2 * (t + 1) / (pulls[a] + 1)) ** 0.5)
algorithms = {"epsilon_greedy": epsilon_greedy, "ucb": ucb}
scores = {0: 0.0, 1: 0.0, 2: 0.0}
pulls = {0: 0, 1: 0, 2: 0}
feedback = {name: 0.0 for name in algorithms}
random.seed(7)
for t in range(12):
# SIA's feedback loop picks the RL algorithm with the best live reward signal.
chosen_algo = max(feedback, key=feedback.get) if t else "epsilon_greedy"
action = algorithms[chosen_algo](scores, pulls, t)
reward = [0.15, 0.55, 0.8][action] + random.uniform(-0.08, 0.08)
pulls[action] += 1
scores[action] += (reward - scores[action]) / pulls[action]
feedback[chosen_algo] = 0.7 * feedback[chosen_algo] + 0.3 * reward
if t == 5:
feedback["ucb"] += 0.5 # new feedback changes the controller's choice
print(f"step={t:02d} sia_selected={chosen_algo:15s} action={action} reward={reward:.2f}")
print("Takeaway: you provide feedback; SIA's loop chooses the RL algorithm.")07단계를 주목하세요: 5단계에서 ucb에 적용된 피드백 부스트로 인해 컨트롤러가 다음 결정 시점에 알고리즘을 전환합니다. SIA의 피드백 에이전트는 동일한 로직을 세대 단위로 적용합니다 — 누적된 보상 신호가 각 단계가 아닌 매 세대마다 알고리즘 선택을 재구성합니다.
커스텀 평가 디렉터리 구성
자체 벤치마크에서 SIA를 실행하려면 아래의 최소 구조로 디렉터리를 생성하고 --task_dir로 경로를 지정하세요:
my-task/
├── data/
│ ├── public/
│ │ ├── task.md # scoring function + evaluation loop
│ │ └── ...
│ └── private/ # held-out answers (never in scaffold context)
└── reference/
├── reference_target_agent.py # working baseline for Meta-Agent
└── SAMPLE_TASK_DESCRIPTIONS.mdsia --task_dir ./my-task --max_gen 5 --run_id 1이 구조에서 알아두어야 할 세 가지:
task.md는 채점 함수와 평가 루프를 정의합니다 — SIA에게 정답의 기준을 알려주며, 피드백 루프를 유도하는 핵심 레버입니다.reference_target_agent.py는 메타 에이전트에게 작동 가능한 시작점을 제공합니다. 생략하면 메타 에이전트가 스캐폴드를 처음부터 생성하지만, 첫 세대의 속도와 품질이 떨어질 수 있습니다.data/private/의 비공개 데이터는 항상 스캐폴드의 컨텍스트 윈도우 밖에 유지됩니다. 실행 중인 에이전트에게는 공개 태스크 설명만 노출되며, 평가 세트 오염은 발생하지 않습니다.
문제 지점과 루프 확장
초기 실행에서 반복적으로 나타나는 네 가지 패턴과 그 해결책:
- Modal H100 비용은 궤적 길이에 비례해 증가합니다. LoRA를 활성화한 채 20세대 이상 실행하기 전에, 1~3회 실행으로 먼저 비용을 프로파일링하세요. 하네스 전용 반복은 GPU 시간을 전혀 소모하지 않으면서도 측정 가능한 개선을 독자적으로 만들어냅니다 — 먼저 하네스의 한계치를 확인하세요.
- 몇 세대가 지나면 Haiku의 보고서가 얕아집니다.
improvement.md가 동일한 수정을 그대로 반복하기 시작하면--meta_model claude-sonnet-4-5-20251001으로 전환하세요. Sonnet은 세대당 비용이 높지만 더 풍부한 하네스 재작성과 더 실질적인 RL 알고리즘 추론을 생성합니다. - 평가 점수가 평탄해지면 하네스 소진 신호입니다. 연속 2~3세대에서 점수 변화가 없다면 피드백 루프가 접근 가능한 스캐폴드 변경을 모두 소진한 것입니다. 하네스 전용으로 실행 중이었다면 이 시점이 가중치 업데이트를 활성화할 타이밍입니다.
- 긴 LoRA 실행은 H100에서 세대당 30분을 초과할 수 있습니다 .
--max_gen을 10 이상으로 높이기 전에agent_execution.json에서 궤적 길이를 확인하세요. 궤적 길이가 세대당 실행 시간의 주요 원인입니다.
SIA의 아키텍처와 벤치마크 방법론에 대한 독립적인 분석은 MarkTechPost 기사와 Moonlight 리뷰를 참고하세요.
자주 묻는 질문
SIA를 실행하려면 GPU가 필요한가요?
아닙니다. 하네스 편집은 Claude API를 통해 CPU만으로 완전히 실행됩니다 — sia-agent[claude]를 설치하고 ANTHROPIC_API_KEY를 내보낸 뒤 실행하면 됩니다. LoRA 가중치 업데이트에는 H100 크레딧이 있는 Modal 계정이 필요합니다. Modal을 설정하지 않으면 가중치 업데이트를 완전히 건너뛸 수 있으며, 루프는 계속 실행되어 GPU 비용 없이 여러 세대에 걸쳐 스캐폴드를 개선합니다.
SIA가 LawBench에서 기본으로 선택하는 RL 알고리즘은 무엇인가요?
GAE를 적용한 PPO입니다. LawBench는 단계별 밀집 보상을 생성하며, Feedback 루프는 해당 보상 구조의 태스크에 대해 일관되게 PPO를 선택합니다. GRPO와 Entropic Advantage Weighting은 희소하거나 우측으로 치우친 보상 분포를 가진 태스크 — 각각 RNA 디노이징과 GPU 커널 최적화 — 에서 등장합니다.
LoRA에 gpt-oss-120b 대신 직접 base 모델을 사용할 수 있나요?
기본 설정으로는 불가합니다. LoRA RL 루프는 기본적으로 gpt-oss-120b를 대상으로 합니다. 다른 base 모델로 교체하려면 run 설정을 편집하고 Modal이 해당 가중치를 로드할 수 있는지 확인해야 합니다. MIT 라이선스를 통해 대안 base를 지원하는 커뮤니티 기여의 문은 열려 있습니다.
각 세대가 실제로 개선되었는지 어떻게 확인하나요?
해당 세대에 대한 Feedback 루프의 근거를 확인하려면 runs/run_{id}/gen_{n}/improvement.md를 읽으세요. 세대 디렉터리 간에 agent_execution.json의 평가 점수를 비교하세요. 개선 노트가 얕거나 반복적이면서 점수가 변동 없이 유지된다면, --meta_model sonnet으로 전환하거나 가중치 업데이트를 활성화할 신호입니다.
SIA가 Feedback 루프와 Meta 루프에서 haiku를 기본값으로 사용하는 이유는 무엇인가요?
비용과 지연 시간 때문입니다. Haiku는 많은 세대에 걸쳐 실행해도 API 비용이 실험 예산을 초과하지 않을 만큼 저렴합니다. haiku의 개선 보고서가 반복되기 시작하는 — 보통 세대 3~4 이후 — 더 풍부한 하네스 재작성이나 더 실질적인 RL 알고리즘 추론이 필요할 때는 --meta_model claude-sonnet-4-5-20251001로 재정의하세요.
다음에 시도해볼 것들
번들 태스크 — gpqa 또는 lawbench — 에서 하네스 전용 실행으로 시작해 세대별 비용을 파악하고, Modal을 활성화하기 전에 improvement.md가 어떻게 보이는지 확인하세요. 하네스 전용 변형은 이미 LawBench에서 13.5% 기준선 대비 50.0%에 도달하므로 , GPU 시간을 가중치 업데이트에 투자하기 전에 하네스 상한선을 파악해 두는 것이 좋습니다.
하네스 향상이 정체되면 — 연속 2~3세대 동안 점수가 평탄할 때 — 가중치 업데이트를 활성화하고 SIA-H와 SIA-W+H 성능을 직접 비교하세요. 커스텀 도메인의 경우 먼저 task.md에 시간을 투자하세요: 잘 명세된 검증기가 Feedback 루프에 의미 있는 신호를 제공합니다. 약하거나 노이즈가 많은 스코어링 함수는 몇 세대를 실행하든 관계없이 하네스 편집과 가중치 업데이트 모두가 나아갈 수 있는 범위를 제한합니다.
전체 논문: arXiv:2605.27276. 코드, 태스크 작성 가이드, 번들 태스크: github.com/hexo-ai/sia. Hexo Labs 연구 프로그램 배경(Stanford, UC Santa Barbara, Oxford 파트너십): Hexo Labs tFiR 인터뷰.
최종 업데이트: 2026-06-01. 이 글은 2026년 5월 28일 수정된 SIA arXiv:2605.27276v2를 기반으로 합니다 .




