
The 2026 Structural Shift: Agents Over Autocomplete
AI coding agents in 2026 are no longer autocomplete engines with broader context windows. The defining change is scope: agents now plan, write, debug, and deploy across full development cycles — handling task decomposition, implementation, test execution, and pull request creation — rather than suggesting the next token in an active file. This is an architectural shift, not an incremental one. Developers delegate work to agents and review outputs; they no longer just accept or reject inline suggestions at the cursor position. Three simultaneous forces define the year: multi-agent platform consolidation inside GitHub's workflow, aggressive valuation growth for pure-play coding-agent startups, and a benchmark credibility collapse that forced the field to retire its primary evaluation standard in favor of a harder successor.
Quick Answer: AI coding agents in 2026 handle full development cycles, not just autocomplete. Three converging forces define the market: GitHub's Agent HQ consolidating Claude, Codex, and future agents onto one platform; Cognition's Devin reaching a $26B valuation and $492M ARR; and SWE-bench Verified's retirement after top agents hit 80%+ scores, exposing contamination and ceiling effects.
The first shift — multi-agent platform consolidation — is playing out on GitHub. Agent HQ, launched in February 2026, integrates Anthropic's Claude and OpenAI's Codex as first-class task-level agents alongside Copilot, with Google, Cognition, and xAI in discussions to join . GitHub's position in the developer workflow — issue tracking, code review, CI — gives it distribution leverage that standalone agent products lack. Developers do not need to change tools to use Agent HQ; they assign tasks inside the workflow they are already in.
The second shift — valuation surges — is concentrated in two companies. Cognition (Devin) went from a $10.2 billion valuation in September 2025 to $26 billion by May 2026 . Cursor (Anysphere) attracted a reported $60 billion acquisition option from SpaceX in April 2026 . Both figures — unexercised option and freshly closed round — reflect investor conviction that task-level autonomy is a large market, not a speculative one.
Architectural divergence is now legible across three distinct models. Cursor is IDE-first: developers stay in their editor and AI augments the active workflow. Devin is agent-first: developers delegate through a web app and review outputs, not process. GitHub Agent HQ is hosted orchestration: task delegation and monitoring inside GitHub's existing PR and issue workflow. Each architecture encodes a different autonomy tradeoff and serves a different developer profile — and that divergence is the right starting point for any evaluation of these tools.
GitHub Agent HQ: Multi-Agent Orchestration Inside Existing Workflows
GitHub Agent HQ is a multi-agent orchestration layer where developers assign engineering tasks — bugs, features, refactors — to Claude, Codex, or Copilot agents that execute asynchronously in the background. Unlike Copilot's inline autocomplete and chat layer, which operates at the keystroke level during an active editor session, Agent HQ operates at the task level: the developer assigns a scoped objective and the agent returns a completed diff or pull request. GitHub launched Agent HQ in February 2026 with Claude and Codex as the first integrated third-party agents, initially available to Copilot Pro+ and Enterprise subscribers .
Access expanded to Copilot Business and Pro users by late February 2026 . The async execution model has a specific implication that is easy to overlook: a developer can assign the same task to both a Claude agent and a Codex agent simultaneously, then compare their reasoning approaches before merging the preferred result. This parallel-agent comparison pattern is unique to Agent HQ and is not available in Cursor or Devin's current architecture. For teams working through ambiguous problems — where the right implementation approach is not obvious — it is a substantively different capability than single-agent task delegation.
On April 14, 2026, GitHub added model selection for both Claude and Codex agents within Agent HQ . Developers can select specific model versions at task assignment time, trading cost against capability depending on task complexity. The available model roster as of that date:
| Provider | Model Variant | Position |
|---|---|---|
| Anthropic (Claude) | Claude Sonnet 4.5 | Standard |
| Anthropic (Claude) | Claude Sonnet 4.6 | Standard (updated) |
| Anthropic (Claude) | Claude Opus 4.5 | Advanced |
| Anthropic (Claude) | Claude Opus 4.6 | Advanced (updated) |
| OpenAI (Codex) | GPT-5.2-Codex | Standard |
| OpenAI (Codex) | GPT-5.3-Codex | Standard (updated) |
| OpenAI (Codex) | GPT-5.4-Codex | Advanced |
Enterprise controls are the critical differentiator for compliance-heavy engineering teams: audit logging at the task level, fine-grained access policies that restrict which agents can operate on which repositories, and impact dashboards tracking agent activity across a GitHub organization. These controls are built into the platform layer rather than applied externally, which reduces the integration overhead for security-conscious organizations. GitHub has confirmed active discussions with Google, Cognition, and xAI to add their agents to the platform , though no confirmed launch dates exist for any of those integrations.
The open question for Agent HQ is model neutrality at scale. If Azure-hosted or GitHub-native models receive preferential pricing or latency treatment while Anthropic and OpenAI agents carry external API costs, the "agent marketplace" framing becomes a distribution strategy rather than an open ecosystem commitment. How GitHub resolves that incentive structure will determine whether Agent HQ becomes a neutral multi-agent coordination layer or a platform that steers teams toward the Microsoft model stack.
Cognition (Devin): $26B Valuation, $492M ARR, Enterprise Traction
Cognition AI closed a $1 billion funding round in May 2026 at a $26 billion post-money valuation — more than double the $10.2 billion figure from September 2025 . The round was led by Lux Capital, General Catalyst, 8VC, and Founders Fund, bringing total capital raised to $2.5 billion . Devin's annualized recurring revenue reached $492 million, up from $37 million in May 2025 — approximately 13× growth in twelve months — with a stated target of $1 billion ARR by year-end 2026 .
Enterprise adoption numbers add specificity to the revenue figure. Named customers include Goldman Sachs, Mercedes-Benz, NASA, Santander, and undisclosed U.S. government agencies. Enterprise usage grew more than 10× since January 2026, with approximately 50% month-over-month growth sustained across six consecutive months . Goldman Sachs and NASA are not organizations that deploy new developer tooling in pilots — their presence on the customer list is a signal that Devin handles production complexity and compliance requirements at the high end of enterprise demand.
"More than 90% of Cognition's own code is generated by Devin." — Scott Wu, CEO at Cognition AI
That internal adoption disclosure is the most concrete proof-of-use signal in Cognition's announcement. A team building an autonomous coding agent and running more than 90% of its own production codebase through that agent is a credible claim — it goes well beyond customer testimonials and implies the architecture is capable of non-trivial, ongoing software work. It also sets an observable standard: if Devin regresses on Cognition's own codebase, that would surface quickly in engineering velocity.
Architecturally, Devin operates as a web-app-based agent. Developers assign tasks through a natural language interface; Devin plans the implementation, writes code, runs tests, handles debugging loops, and returns a diff or pull request for human review. The developer supervises the output, not the intermediate process. This model suits longer-horizon autonomous tasks — dependency migrations, test suite expansion, cross-service refactors — where waiting for a completed result is preferable to supervising each step. It is less suited for tight exploratory development loops where a developer needs granular control and rapid iteration at each decision point. The $1 billion year-end ARR target has not been independently verified and should be treated as a forward guidance figure, not a confirmed outcome.
Cursor: $2B ARR, Eight-Agent Windows, and a $60B Acquisition Rumor
Cursor, built by Anysphere as a VS Code fork, reached $2 billion in annualized recurring revenue by February 2026 . In April 2026, SpaceX reportedly secured an option to acquire Anysphere at a $60 billion valuation . The option has not been confirmed as exercised, but the reported figure — combined with the $2 billion ARR — positions Cursor among the most valuable pure-play developer tools in the market regardless of whether an acquisition closes.
In late February 2026, Cursor shipped an eight-agent parallel execution window. Developers can now run up to eight concurrent agents inside the IDE simultaneously , each operating on a separate branch or task and surfacing independent diffs from a unified IDE pane. This is meaningfully different from Agent HQ's multi-agent comparison model. In Cursor, the developer retains full local repository context throughout — debuggers, linters, version control integration, and custom VS Code extensions all function as expected. The developer monitors all eight agents from within the editor environment rather than switching to a web dashboard.
Cursor's IDE-first architecture is its primary differentiation. Developers who have invested in customized VS Code setups (extensions, key bindings, language server configurations) find the Cursor transition significantly lower-friction than switching to a web-app agent model. The tradeoff is that Cursor's agents are inherently developer-supervised: even with eight agents running in parallel, the developer remains an active monitor rather than returning hours later to review a completed pull request. This supervision model is a feature for developers who want control; it is a limitation for engineering managers seeking full task delegation at scale.
Cursor's positioning relative to Devin is not incidental — the two products target different autonomy tolerances. Cursor suits developers who want AI acceleration on work they are actively engaged in. Devin suits developers or engineering managers comfortable scoping a task entirely to an agent and reviewing the result. Both are well-funded, both have demonstrated market fit, and both have reached ARR figures that confirm the market is large enough to support differentiated positioning.
Claude Code: Managed Agents, Routines, and Agentic Security Layer
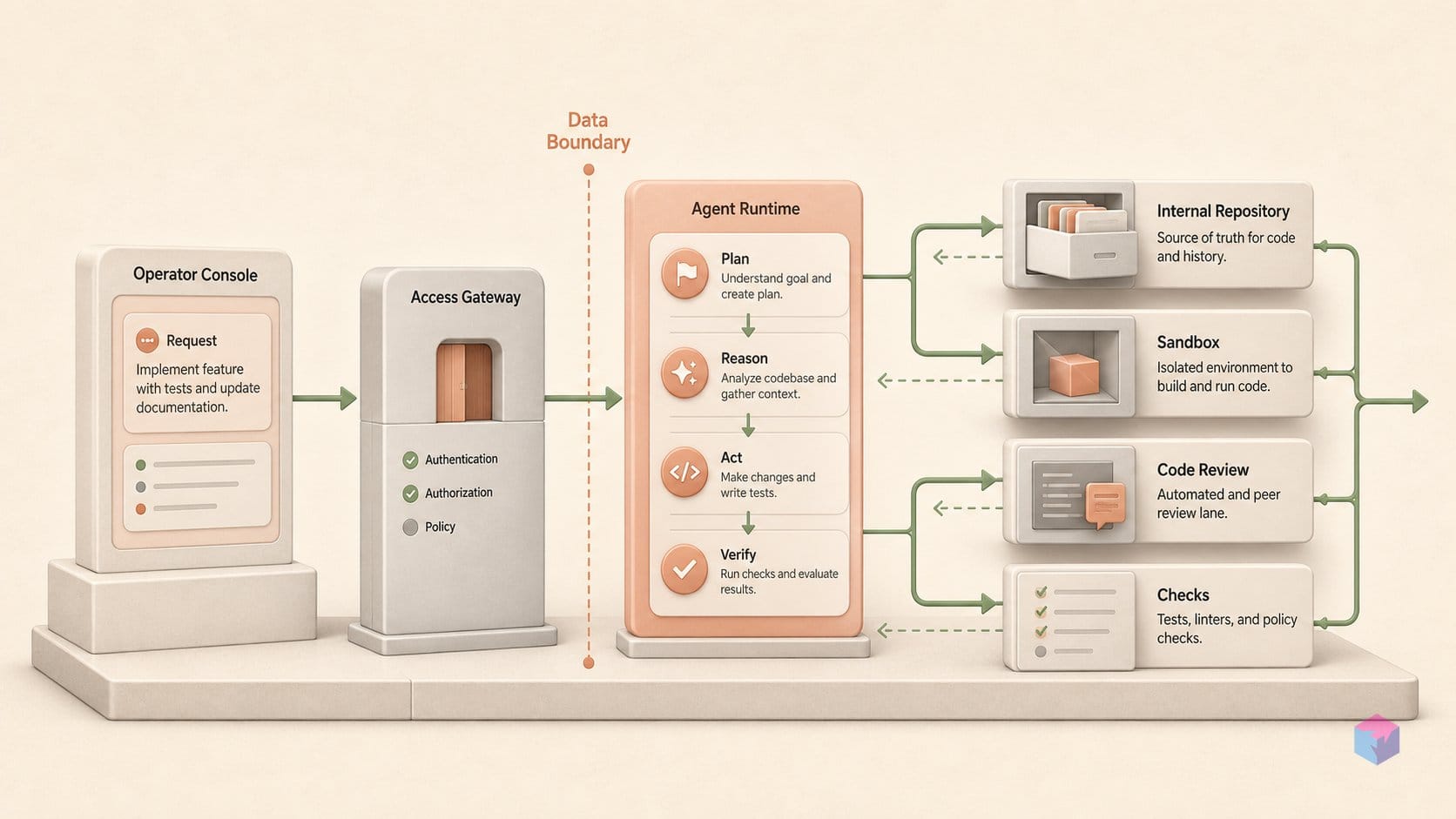
Anthropic's May 2026 Claude Code release introduced Managed Agents as production infrastructure for running Claude in automated engineering pipelines . Managed Agents add three capabilities that were absent from prior Claude Code agentic workflows: sandboxed execution environments that isolate agent processes from host systems; checkpointing, which saves task state at intervals so that long-running operations — a multi-hour dependency migration, for example — can resume after interruption without starting over; and credential scoping, which bounds what external services and secrets an agent can access during a pipeline run. Credential scoping is the security-critical feature: it limits the blast radius if an agent is manipulated via prompt injection or makes an unintended action in a production environment.
"Claude Code is the fastest-growing product in the coding agent category." — Agentic.ai, May 2026
Routines extend the scheduling model beyond interactive sessions. Developers configure recurring prompts triggered either by a schedule (nightly dependency audits, weekly changelog generation, daily security scans) or by webhooks (CI failures, new issue creation, PR merges). Routines are parametric — they accept context injected at trigger time — so a nightly security audit can include the day's commit diff as context without manual intervention. This removes the need to write custom orchestration scripts around the Claude API for standard engineering automation tasks that previously required a dedicated workflow layer.
Auto mode adds a pre-execution classifier that screens agent actions before they run. The classifier flags destructive operations — file deletions, environment variable mutations, network calls to external services — and prompt injection patterns embedded in code comments, test fixtures, or third-party dependency content. Worktree isolation creates independent Git branches per agent task, ensuring that failed or adversarially redirected runs do not corrupt main branch state. The real-time security plugin monitors approximately 25 vulnerability classes during code generation, including SQL injection, cross-site scripting (XSS), hardcoded secrets, and insecure deserialization . The plugin runs inline rather than as a post-generation audit step, meaning vulnerabilities surface during generation rather than in a separate review pass.
Anthropic's Q1 2026 annualized revenue reached $30 billion, reported as 80× growth against a projected 10×, driven largely by enterprise agent deployments . Claude Code reached Opus 4.8 with high-effort defaults by late May 2026 . The Managed Agents release positions Claude Code not just as an interactive coding assistant but as a programmable pipeline component — a different product with a different buyer profile than the session-based agent model.
The SWE-Bench Crisis: Why the Field's Primary Benchmark Broke
SWE-bench Verified, the dominant benchmark for coding agent evaluation through 2025, is effectively retired in 2026. The collapse stems from two compounding problems: a ceiling effect that makes score differentiation meaningless at the top of the leaderboard, and training data contamination from publicly accessible benchmark repositories. OpenAI ceased reporting SWE-bench Verified scores in early 2026, citing contamination concerns . When top agents score 80% or higher on a benchmark, a 2-point spread between competing models falls below the threshold of meaningful differentiation — the difference between 81% and 83% tells a buyer nothing actionable about real-world performance on production code.
"Claude Opus 4.5 scores 80.9% on SWE-bench Verified but only 45.9% on SWE-bench Pro — a 35-point gap attributed to memorization of publicly accessible benchmark training data." — CodeAnt AI, 2026
The 35-point gap between a model's Verified and Pro scores is the clearest evidence that Verified scores reflect benchmark memorization as much as coding capability . SWE-bench Pro was introduced to address both the ceiling and contamination problems. It uses 1,865 tasks across Python, Go, TypeScript, and JavaScript, drawn from private and commercial codebases with structural safeguards against data leakage. Current top performance on Pro stands at approximately 57%, with an average across evaluated models of around 25% — score differentiation is restored, and the gap between leading and average models is meaningful again.
| Model | SWE-bench Verified (%) | SWE-bench Pro (%) | Score Delta |
|---|---|---|---|
| Claude Mythos Preview (unreleased) | 93.9 | N/A | — |
| GPT-5.3 Codex | 85.0 | ~57 (top) | ~28 |
| Claude Opus 4.5 | 80.9 | 45.9 | 35.0 |
| OpenHands (Opus 4.6 backend) | 68.4 | ~25 (avg. range) | ~43 |
| Claude Sonnet 3.7 | 62.0 | ~18 (est.) | ~44 |
The practical implication for engineering teams evaluating coding agents: any vendor performance claim needs to specify four parameters before it is comparable across products. First, the benchmark version — Verified or Pro. Second, the repository commit window — older repos carry higher contamination risk. Third, the evaluation mode — scaffold scores (where the agent has structured scaffolding assistance) are systematically higher than full-agent scores. Fourth, the evaluation date — leaderboard positions shift as new models ship. Without all four, a headline percentage is a marketing number, not a procurement input . Engineering teams building procurement decisions on vendor-reported Verified scores should treat those numbers as upper bounds on real-world performance, not realistic estimates.
Architecture Comparison: IDE-First vs. Agent-First vs. Hosted Orchestration
The three dominant architectural models for AI coding agents encode different assumptions about who controls the development loop and where that control lives. IDE-first tools keep the developer in control: AI augments within the editor, local repository context is rich and immediately accessible, and the developer supervises each agent action without context-switching to a separate interface. Agent-first web apps invert that model: the developer delegates a task description, the agent manages the full development loop independently, and the developer reviews the resulting output. Hosted orchestration platforms embed task delegation inside existing workflow tools — in GitHub's case, issue tracking and pull request review — reducing the integration cost for teams already working within those environments .
| Dimension | Cursor (IDE-First) | Devin (Agent-First) | GitHub Agent HQ (Hosted Orchestration) |
|---|---|---|---|
| Developer Interface | VS Code fork (local editor) | Web application | GitHub Issues / PR workflow |
| Autonomy Level | Low–medium; developer supervises each step | High; delegate task, review output | Medium; async task assignment, agent executes |
| Context Model | Full local repo + IDE tooling context | Task description + repo access via API | GitHub repo + issue and PR context |
| Parallel Agents | Up to 8 concurrent (Feb 2026 update) | Single task per assignment session | Multiple agents on same task for comparison |
| Enterprise Controls | Standard Git and VS Code access controls | Enterprise tier; audit logs available | Built-in audit logging, access policies, dashboards |
| Primary Use Case | Active development augmentation | Autonomous delegation of scoped tasks | GitHub-native team task automation |
| 2026 ARR / Valuation | $2B ARR / $60B reported option | $492M ARR / $26B valuation | Part of Microsoft / GitHub |
The tradeoffs are not symmetric. Control and context richness favor IDE-first architectures for exploratory tasks — early-stage feature development, debugging sessions requiring rapid iteration, work where the right approach is not yet clear. Async scale and autonomy favor agent-first platforms for well-scoped tasks with clearly specified acceptance criteria: dependency upgrades, test suite generation, cross-service boilerplate. Workflow integration and multi-agent comparison favor hosted orchestration for teams that want a single task-management surface across multiple agent providers without managing separate tool chains or switching between interfaces.
A convergence dynamic is already visible across all three categories. Cursor is adding autonomous agent modes that reduce developer supervision requirements, moving toward Devin's delegation model. Devin is releasing IDE plugins to capture developers earlier in the active workflow, moving toward Cursor's model. GitHub Agent HQ is expanding its model roster and adding task-level features that overlap with both. The architectural distinctions that clearly separate these products today may narrow considerably by Q4 2026 as each category copies the capabilities that drive retention in the others.
What Developers Should Watch in H2 2026
Four dynamics will determine the trajectory of the coding agent market through the rest of 2026. The most consequential is GitHub's pending integrations with Google, Cognition, and xAI. If those integrations ship with genuine model neutrality — same pricing, same latency, same feature surface for all agents — Agent HQ becomes a credible neutral marketplace. If Azure-hosted models receive preferential treatment in any of those dimensions, the marketplace framing is a distribution strategy. Watch the pricing structure, not the announcement language, when those integrations go live.
Second, SWE-bench Pro adoption rate matters more than any individual score on the new leaderboard. If major vendors — Anthropic, OpenAI, and Cognition — do not converge on Pro as the standard reporting benchmark by Q3 2026, fragmentation gets worse and buyer comparisons become impossible. The signal to watch: whether the next major model release from each vendor publishes Pro scores alongside or instead of Verified scores. Continued use of Verified scores in marketing materials, without Pro scores, should be treated as a flag.
Third, Anthropic's revenue trajectory is a proxy for where enterprise investment in agentic pipelines is concentrated. Q1 2026 annualized revenue reached $30 billion — an 80× growth figure against a projected 10× — driven primarily by enterprise agent deployments . This implies that agentic coding pipelines are already at production scale in large organizations, not sitting in evaluation stages. Tracking where Anthropic's enterprise deal flow concentrates by industry and geography will indicate which segments are deploying agents at operational scale versus running proofs of concept.
Fourth, consolidation pressure on product differentiation is accelerating. IDE tools are adding autonomous modes. Autonomous agents are releasing IDE plugins. Platforms are hosting both. The distance between Cursor's and Devin's feature sets is smaller in May 2026 than it was in January 2026, and it will be smaller still by October. The durability of each platform's moat — Cursor's IDE context richness, Devin's full task autonomy, Agent HQ's GitHub workflow integration — will be tested as competitors move into each other's positioning. By Q4 2026, the differentiating question may not be which architecture is right, but which platform's execution quality and reliability is highest when all three offer roughly the same surface area of features.
Frequently Asked Questions
What is GitHub Agent HQ and how does it differ from GitHub Copilot?
GitHub Agent HQ is a multi-agent orchestration layer where developers assign engineering tasks — via GitHub issues or PR assignments — to Claude, Codex, or Copilot agents that execute asynchronously in the background. The agents work while the developer continues unrelated work and return a completed diff or pull request for review. GitHub Copilot is the inline autocomplete and chat assistant that operates at the keystroke level during an active editor session — it suggests completions and answers questions while the developer types. The two work at different scopes: Copilot at the keystroke level, Agent HQ at the task level. They are complementary and GitHub positions them as parts of the same platform. Agent HQ launched in February 2026 with Claude (Sonnet 4.5/4.6, Opus 4.5/4.6) and Codex (GPT-5.2 through GPT-5.4-Codex variants) available for selection as of April 2026. Enterprise controls — audit logging, access policies, and activity dashboards — are built into Agent HQ at the task layer.
How is Devin different from Cursor for day-to-day development?
Devin operates as a web-app-based autonomous agent. A developer writes a task description in natural language, Devin plans the implementation, writes code, runs tests, handles debugging, and returns a pull request for review. The developer is not involved in intermediate steps and does not supervise the process — they review the output. Cursor is a VS Code fork where the developer stays active in the editor throughout every step: AI suggests, the developer accepts or redirects, and control remains with the human at each decision point. The autonomy difference is structural. Cursor suits developers who want acceleration on work they are actively directing — exploratory development, debugging sessions, feature work where the approach evolves during implementation. Devin suits delegating well-scoped tasks — test coverage expansion, dependency migrations, boilerplate scaffolding — where the developer is comfortable specifying requirements upfront and reviewing a completed result. Both reached significant ARR by early 2026, confirming market fit for both autonomy models.
Why did the AI coding agent industry move away from SWE-bench Verified?
Two compounding problems made SWE-bench Verified unreliable for product differentiation. First, a ceiling effect: top agents reached 80%+ scores, compressing differences between models to margins too small to interpret — a 2-point spread at the top of the leaderboard is not a decision-relevant signal. Second, training data contamination: SWE-bench Verified's repositories are publicly accessible, meaning models trained after the benchmark's release may have encountered the test cases during training, producing memorization artifacts rather than generalizable coding capability. OpenAI stopped reporting Verified scores in early 2026 for this reason. SWE-bench Pro addresses both problems: it uses newer repositories from private and commercial codebases (lower contamination risk), harder problem selection (top performance ~57%), and cross-language coverage (Python, Go, TypeScript, JavaScript). The contamination evidence is stark: Claude Opus 4.5 scores 80.9% on Verified and only 45.9% on Pro — a 35-point gap on the same model testing the same capability. Any vendor performance claim should now specify which benchmark version was used.
What exactly are Claude Code Managed Agents?
Managed Agents are production infrastructure for running Claude Code in automated engineering pipelines, announced in May 2026. They add three capabilities absent from prior Claude Code agentic workflows. Sandboxed execution: agent processes run in isolated environments that cannot affect the host system or other running agents, containing errors and adversarial actions. Checkpointing: task state is saved at intervals, so a long-running operation — a multi-hour dependency migration or a multi-repo refactor — can resume after an interruption without restarting from the beginning. Credential scoping: each agent task is assigned a bounded set of credentials rather than inheriting the full environment, limiting the damage if an agent is redirected by a prompt injection attack or makes an unintended external call. Managed Agents shipped alongside Routines (scheduled and webhook-triggered recurring workflows) and Auto mode (a pre-execution classifier that flags destructive actions and prompt injection patterns before they execute). Together these features position Claude Code as a programmable pipeline component rather than only an interactive coding assistant.
Which AI coding agent setup makes the most sense for an enterprise engineering team?
The choice depends on workflow structure and autonomy tolerance, not on benchmark scores or valuation figures. GitHub Agent HQ is the lowest-friction option for teams already operating on GitHub Enterprise: audit logging, access policies, and task-level activity dashboards are built in, and agent assignment happens inside the issue and PR workflow without introducing new tooling. The multi-agent comparison capability — assigning the same task to Claude and Codex simultaneously — adds value for teams working through ambiguous implementation problems. Devin is the reference choice for fully delegated autonomous work at scale: Goldman Sachs, NASA, and Mercedes-Benz are named enterprise customers, and the 10× enterprise usage growth since January 2026 indicates the platform handles production complexity and compliance requirements. Claude Code with Managed Agents is the right choice for teams building programmable agentic pipelines where scheduling, credential scoping, and resumability are engineering requirements rather than conveniences — nightly builds, dependency audits, security scans, or any recurring engineering task that currently requires custom orchestration scripts. Teams doing active feature development are likely best served by Cursor for day-to-day work, with one of the task-delegation platforms handling larger scoped projects in parallel.
Convergence, Credibility, and the Autonomy Tradeoff
The 2026 coding agent market is not converging on a single winning architecture — but it is converging on a narrower set of meaningful distinctions. Cursor now runs eight parallel agents. Devin has enterprise customers with strict compliance requirements. Claude Code ships scheduling, sandboxing, and agentic security tooling that previously required custom infrastructure. The product surface area of all three is expanding toward each other faster than the underlying architectures are diverging. Developers choosing between these tools today are making decisions that will need to be revisited by Q4 2026 as the feature parity gap closes.
The SWE-bench situation deserves more attention from buyers than it currently receives. The Verified benchmark's collapse is not an isolated event — it is a pattern: any benchmark that becomes publicly visible and commercially significant faces contamination pressure as vendors optimize toward it. The 35-point gap between Verified and Pro scores on the same model is a clear signal that headline benchmark figures have been overstating agent capability relative to production performance on novel code. Until SWE-bench Pro — or a successor — becomes the universal reporting standard, treat vendor-reported benchmarks as starting points for due diligence rather than as decision inputs.
For engineering teams making tooling decisions now, the most durable evaluation criterion is autonomy tolerance. Define how much of the development loop you want an agent to own before evaluating specific products. If developers need to stay in the loop at every step, start with Cursor. If you want to delegate scoped tasks and review completed results, evaluate Devin. If your team lives in GitHub and needs multi-agent task automation with built-in audit controls, Agent HQ has the lowest integration overhead. If you are building automated engineering pipelines that need scheduling, security boundaries, and resumability, Claude Code Managed Agents are the right layer. These use cases will overlap more by year-end 2026 — but the product-fit differences are still material today.
Last updated: 2026-05-30. This article reflects publicly available product announcements, reported financial figures, and benchmark data as of late May 2026. Unconfirmed claims — including the SpaceX acquisition option on Anysphere and Cognition's year-end $1B ARR target — are noted as such in the relevant sections and should not be treated as verified outcomes.






