
b9437에서 달라진 것들
2026년 5월 30일 20:56 UTC에 공개된 빌드 b9437 은 llama-bench의 기본값 두 곳을 수정합니다. 플래시 어텐션(-fa)은 하드코딩된 off에서 auto(LLAMA_FLASH_ATTN_TYPE_AUTO)로 바뀌고, GPU 레이어 수(-ngl)는 기존 센티널 값 99에서 -1로 변경됩니다. 두 값 모두 llama-server와 llama-cli가 이미 사용하던 값과 일치하며, 벤치 도구만 이번 빌드 전까지 해당 값을 반영하지 않고 있었습니다.
한줄 요약: b9437(2026년 5월 30일 공개) 이전의 llama-bench는 -fa off를 하드코딩해, CUDA·Metal·Vulkan 하드웨어에서도 플래시 어텐션을 조용히 건너뛰었습니다. 빌드 b9437부터 기본값이 -fa auto·-ngl -1로 변경되어 llama-server·llama-cli와 일치합니다. FA 지원 하드웨어에서 b9437 이전 기준값을 사용했다면, 유효한 비교를 위해 플래그를 맞춰 재실행해야 합니다.
PR #23714 는 메인테이너 JohannesGaessler와 pwilkin의 검토·병합을 거쳐, 툴체인의 다른 도구들이 이미 지원하던 -fa auto|off|on 3-상태 플래그를 llama-bench에도 추가했습니다. 새로운 기본값인 LLAMA_FLASH_ATTN_TYPE_AUTO를 통해, 런타임이 지원 백엔드(CUDA, Metal, Vulkan)를 감지하면 플래시 어텐션이 자동으로 활성화됩니다. CPU 전용 호스트에서는 오류 없이 꺼진 상태를 유지하며 출력 형식도 변하지 않습니다.
| 파라미터 | b9437 이전 | b9437 이후 | 동작 변화 |
|---|---|---|---|
-fa |
off (하드코딩) |
auto (LLAMA_FLASH_ATTN_TYPE_AUTO) |
GPU 지원 호스트는 기본적으로 FA가 활성화된 상태로 벤치가 실행됩니다. 변경 전후 비교 시 플래그를 명시적으로 맞춰야 합니다. |
-ngl |
99 (전체 오프로드 센티널) |
-1 (런타임이 결정) |
CPU 전용 빌드에서 전체 GPU 오프로드를 시도하지 않으므로, GPU가 없을 때 발생하던 불필요한 CUDA 오류가 사라집니다. |
다음 검증 스크립트(실행 성공, exit 0)는 동작 차이를 구체적으로 보여줍니다. FA 지원 GPU에서 b9437 이전 기본값은 FA 행을 0개 스케줄하지만, b9437 기본값은 1개를 스케줄합니다:
def old_llama_bench(device):
# Before b9437, the default bench matrix used FA=0, so FA rows were skipped.
return [{"device": device["name"], "ngl": 0, "fa": 0}]
def b9437_llama_bench(device):
# b9437: default ngl=-1 and -fa auto, which enables FA on capable GPUs.
fa = 1 if device["kind"] == "gpu" and device["flash_attn"] else 0
return [{"device": device["name"], "ngl": -1, "fa": fa}]
gpu = {"name": "CUDA0", "kind": "gpu", "flash_attn": True}
old = old_llama_bench(gpu)
new = b9437_llama_bench(gpu)
print(f"capable GPU: {gpu['name']} flash_attn={gpu['flash_attn']}")
print(f"pre-b9437 scheduled FA rows: {sum(r['fa'] for r in old)}")
print(f"b9437 scheduled FA rows: {sum(r['fa'] for r in new)}")
assert sum(r["fa"] for r in old) == 0
assert sum(r["fa"] for r in new) == 1사전 준비 사항
컴파일 전, Git, CMake 3.14+, 그리고 C++17 지원 컴파일러(Linux/macOS에서는 GCC 11+ 또는 clang 13+, Windows에서는 MSVC 2022)가 설치되어 있는지 확인하세요 . 이는 현재 프로젝트의 최소 요구 사항이며, 더 최신 버전도 문제없이 동작합니다.
GGUF 모델 파일도 필요합니다. qwen3-8b-q4_k_m.gguf가 실용적인 시작점으로, huggingface-cli download로 내려받거나 llama-server의 --hf 플래그로 시작 시 자동 다운로드할 수 있습니다. 해당 경로는 llama-bench의 -m 인수로 전달합니다.
GPU는 선택 사항이지만 -fa auto로 플래시 어텐션을 활성화하려면 필요합니다. 세 가지 백엔드가 이를 지원합니다: NVIDIA 카드용 CUDA, macOS용 Metal(기본 활성화), AMD·Intel·구형 NVIDIA 하드웨어용 Vulkan. CPU 전용 호스트에서는 -fa auto가 꺼진 상태를 유지하며, 오류 없이 출력 형식도 그대로입니다.
직접 해보기: 수정된 벤치 컴파일 및 실행
아래 단계는 Linux/macOS 기준입니다. Windows에서는 -j$(nproc) 대신 -j%NUMBER_OF_PROCESSORS%를 사용하고, MSVC 빌드라면 Developer Command Prompt에서 실행하세요. 플랫폼별 전체 옵션은 docs/build.md를 참고하세요.
직접 비교를 위해 b9437 이전 동작을 재현하세요.
./build/bin/llama-bench -m ./models/qwen3-8b-q4_k_m.gguf \
-fa off -ngl 99두 플래그를 모두 b9437 이전 기본값으로 되돌려, 과거 수치와 1:1 비교할 수 있는 베이스라인을 만들어 줍니다.
FA가 실제로 활성화되었는지 확인하세요.
./build/bin/llama-bench -m ./models/qwen3-8b-q4_k_m.gguf \
-ngl -1 -fa auto -p 512 -n 128 -r 3 --verbose모델 로드 출력에서 flash_attn = 1을 확인하세요. CUDA 호스트에서 flash_attn = 0이 보인다면 백엔드가 -DGGML_CUDA=ON 없이 컴파일된 것입니다 — 빌드 디렉터리를 삭제하고 해당 플래그를 추가해 다시 컴파일하세요.
b9437 기본값을 명시적으로 지정해 벤치마크를 실행하세요.
./build/bin/llama-bench -m ./models/qwen3-8b-q4_k_m.gguf \
-ngl -1 -fa auto -p 512 -n 128 -r 3-p 512는 프롬프트 토큰(프리필 처리량), -n 128은 생성 토큰(생성 처리량), -r 3은 세 번 반복 후 평균을 냅니다. 이를 명시적으로 지정하면 b9437 이상 빌드뿐만 아니라 어떤 빌드에서도 결과를 재현할 수 있습니다.
사용 중인 백엔드에 맞게 컴파일하세요.CPU 전용:
cmake -B build && cmake --build build --config Release -j$(nproc)CUDA (NVIDIA):
cmake -B build -DGGML_CUDA=ON && cmake --build build --config Release -j$(nproc)macOS에서는 Metal이 기본으로 활성화되므로 별도 플래그가 필요 없습니다. Vulkan (AMD/Intel/NVIDIA 크로스 플랫폼):
cmake -B build -DGGML_VULKAN=ON && cmake --build build --config Release -j$(nproc)저장소를 클론하고 빌드가 b9437 이상인지 확인하세요.
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
git log --oneline -1최상단 커밋이 -fa bench PR을 참조하거나 b9437 이후의 해시를 가리켜야 합니다. 연속 빌드에는 시맨틱 버전 태그가 없으므로, 확실하지 않다면 releases 페이지에서 교차 확인하세요.
기존 비교 데이터가 어긋나는 지점
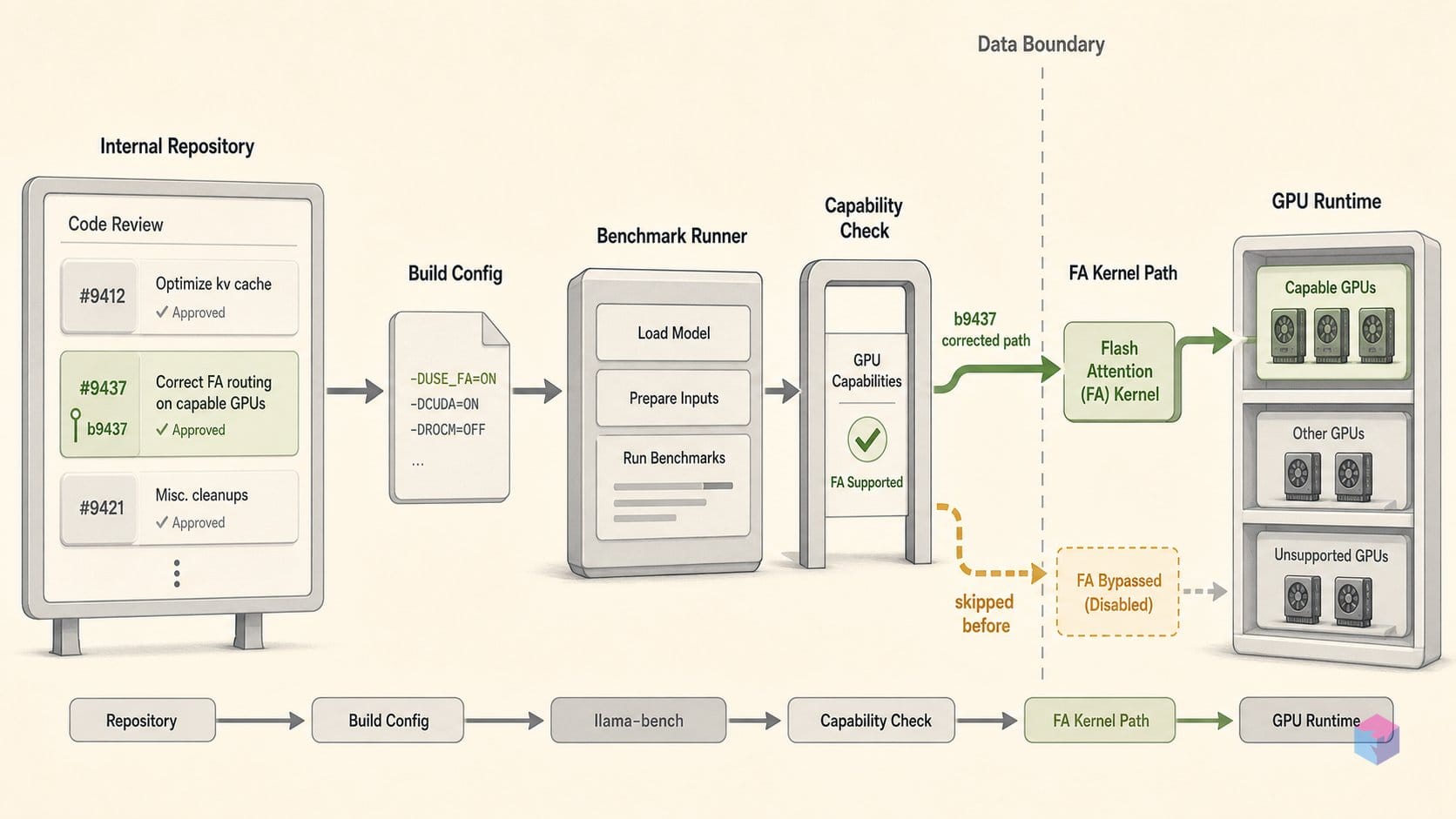
b9437 이전의 모든 llama-bench 실행은 플래시 어텐션을 완전히 지원하는 하드웨어에서조차 -fa off를 암묵적 기본값으로 사용했습니다. 해당 빌드에서 기록된 t/s 수치가 있고 하드웨어가 FA를 지원한다면, 그 수치는 더 느린 어텐션 경로를 캡처한 것임에도 그 사실이 표시되지 않습니다. 과거 결과를 새 기본값과 맞추려면, -fa off -ngl 99로 기존 베이스라인을 재실행하거나(원래 동작 재현) 전체를 -fa auto로 재실행해 앞으로 비교 가능한 수치를 확보하세요. 어느 쪽이든 이후 벤치마크 출력에는 -fa 상태를 명시적인 열로 추가하세요.
-ngl 99 레거시 기본값은 CPU 전용 호스트에서도 조용한 함정이 되었습니다. -ngl 플래그를 지정하지 않으면 런타임이 99개 레이어 전체를 GPU에 로드하려 시도해, GPU가 없는 환경에서도 CUDA 초기화 오류가 발생했습니다. -ngl -1을 사용하면 백엔드가 감지되지 않을 때 GPU 오프로드를 건너뛰어, 로그에서 이 노이즈가 완전히 사라집니다.
RTX 4090에서 Qwen 3.6 27B dense 모델의 Multi-Token Prediction 성능 향상 — 약 77에서 96 t/s , PR #22673을 통한 처리량 24% 증가 — 는 b9437 기본값 변경과는 별개의 맥락에서 측정된 것입니다. 해당 수치를 재현하려면 원래 실행의 -fa 상태를 먼저 확인하세요. 불일치하면 순수 MTP 베이스라인도, MTP+FA 복합 측정값도 아닌 결과가 나올 수 있습니다.
b9437 너머, 살펴볼 것들

b9437과 함께 확인할 만한 인접 빌드 세 가지입니다.
- b9436 (2026년 5월 30일 14:25 UTC) : OpenCL 백엔드에 BF16→FP16 변환 지원이 추가됩니다. OpenCL 또는 Vulkan 경로로 AMD·Intel 하드웨어에서 BF16 포맷 모델을 실행한다면, GPU의 네이티브 BF16 지원 없이도 호환성이 넓어집니다.
- b9439 (2026년 5월 31일 06:57 UTC) : 멀티 GPU 호스트에서 이제 기본적으로 통합 GPU 하나만 사용하도록 바뀌어, 저성능 iGPU가 독립 GPU와 함께 자동 선택되는 상황을 방지합니다. 독립 GPU와 Intel UHD가 함께 있는 노트북 같은 하이브리드 시스템이라면 업데이트 후 디바이스 선택이 여전히 올바른지 확인하세요.
- Qwen 3.6용 Multi-Token Prediction (PR #22673): dense 27B 모델에서 처리량 약 24% 향상 .
--mtp-n-draft로 활성화하고 GGUF 양자화가 호환되는지 확인하세요. MoE 변형(Qwen 3.6 35B-A3B)은 결과가 엇갈립니다 — expert-union 검증기 오버헤드가 컨슈머 하드웨어에서 이득을 상쇄할 수 있습니다.
자주 묻는 질문
b9437 이후 llama-bench에서 -fa auto는 무엇을 의미하나요?
-fa auto는 플래시 어텐션을 LLAMA_FLASH_ATTN_TYPE_AUTO로 설정하며, 백엔드가 지원하는 경우 런타임이 플래시 어텐션을 활성화하도록 지시합니다. b9437 이전에는 llama-bench가 항상 -fa off를 기본값으로 사용했습니다 — 이미 auto|off|on 3단계 플래그를 지원하던 llama-server 및 llama-cli와 달리 말이죠. b9437 이후에는 세 도구 모두 동일한 플래그 의미를 사용합니다.
b9437 이전 llama-bench 수치는 여전히 유효한가요?
단서가 있지만 유효합니다. 원래 실행 시 명시적으로 -fa off를 전달했거나 호스트 하드웨어가 플래시 어텐션을 지원하지 않는다면, 수치는 비교 가능한 상태로 남습니다. 그러나 기본값에 의존하면서 FA를 지원하는 하드웨어 — CUDA, Metal, 또는 Vulkan — 에서 실행했다면, GPU가 지원함에도 불구하고 해당 측정값은 플래시 어텐션 없이 수집된 것입니다. 정확한 사과 대 사과 비교를 위해 동일한 플래그로 재실행하세요.
-ngl 기본값이 -1이 아닌 99였던 이유는 무엇인가요?
99는 "모든 레이어를 GPU로 오프로드"를 의미하는 레거시 센티넬 값이었습니다. 이후 프로젝트는 툴체인 전반에 걸쳐 -1을 런타임이 결정하는 값으로 표준화했습니다. llama-bench는 단순히 b9437이 llama-server 및 llama-cli와 정렬을 맞출 때까지 업데이트되지 않았던 것입니다.
b9437을 사용하려면 소스에서 재컴파일해야 하나요?
로컬 소스 빌드의 경우 그렇습니다. ggml-org/llama.cpp에서 최신 커밋을 pull하고 재컴파일하세요. 태그된 바이너리 릴리스는 연속 빌드보다 늦게 배포됩니다. 컴파일을 건너뛰고 싶다면 GitHub 릴리스 페이지에서 사전 빌드된 아티팩트를 확인하되, 현재 버전으로 취급하기 전에 빌드 번호에 b9437 변경 사항이 포함되어 있는지 반드시 확인하세요.
-fa auto가 이제 llama-bench, llama-cli, llama-server에서 동일하게 작동하나요?
네 — b9437이 그 차이를 해소합니다. llama-cli와 llama-server는 이미 -fa auto|off|on 3단계를 지원하고 있었습니다. b9437은 llama-bench를 동등한 수준으로 끌어올려, 이제 세 도구 모두에서 플래그 의미가 일관됩니다. llama-server에서 검증한 플래그 값은 llama-bench에 전달할 때도 정확히 동일한 의미를 가집니다.
다음 회귀 실행 전에 기준선을 재설정하세요
b9437 이상을 pull한 후 즉시 취해야 할 조치는 명확합니다. 회귀 추적에 사용하는 llama-bench 결과를 재기준화하고, 앞으로는 출력에 -fa 상태를 명시적인 컬럼으로 포함하세요. 기본값 변경은 사소한 툴체인 정렬이지만, 벤치마크 유효성에 미치는 영향은 구체적입니다 — b9437 이전에 CUDA, Metal, 또는 Vulkan에서 실행된 모든 테스트는 조용히 더 느린 어텐션 경로를 측정하고 있었습니다.
멀티 GPU 시스템을 사용 중이라면, iGPU 기본값 수정을 위해 b9439도 함께 pull하세요 . Qwen 3.6 처리량이 테스트 매트릭스에 포함된다면, Multi-Token Prediction의 --mtp-n-draft 플래그도 범위에 포함하세요 — dense 27B에서 약 24%의 성능 향상 은 측정할 가치가 있지만, MoE 변형 결과는 편차가 크므로 자신의 하드웨어와 양자화 설정에서 직접 수치를 확인해야 합니다.
최종 업데이트: 2026-06-01. llama.cpp 연속 빌드 b9436–b9439 (2026년 5월 30–31일) 기준 .







