
the source document section throughout the research output. For systematic reviews and meta-analyses — where peer reviewers or regulatory bodies require a chain of custody for each finding — this structural property is a meaningful difference from document-chat tools built primarily for information retrieval.
Comparing it to existing tools: Elicit and Consensus operate as search-and-filter interfaces over scientific paper databases, surfacing relevant papers with structured study attributes. Literature Insights starts after retrieval — it ingests an existing corpus and outputs structured data with multimodal generation. Slide decks and infographics from a research corpus are not Elicit or Consensus outputs. Teams that already hold a literature corpus and need structured synthesis with per-cell citation links are addressing a different workflow step than teams using search-first tools to find relevant papers .
Because Literature Insights is built on NotebookLM, it inherits that platform's document-parsing infrastructure. Corpus size limits, supported file formats, and API access terms are likely to follow NotebookLM's roadmap rather than a standalone product track. Developers evaluating Literature Insights for production integration should monitor NotebookLM's API documentation for the relevant constraints rather than treating it as an independently versioned service.
Co-Scientist: From Challenge Statement to Ranked Hypothesis Candidates
Co-Scientist is a multi-agent Gemini system that structures hypothesis generation as an iterative evaluation loop. Researchers define a challenge statement; Co-Scientist then runs what Google describes as an "idea tournament" — generating candidate hypotheses, deploying agents to debate their validity, flagging logical flaws, supplying clickable citations for all factual claims within each hypothesis, and ranking the survivors after multiple rounds . Surviving hypotheses feed back into the generation stage for further refinement. The Co-Scientist research paper was published in Nature on May 19, 2026 , simultaneous with the I/O announcement.
"Co-Scientist runs a multi-agent idea tournament — generating, critiquing, and iteratively refining candidate hypotheses with clickable citations for every factual claim within each proposal." — Co-Scientist, Google DeepMind (source: Nature, 2026-05)
An early experiment gives a concrete illustration of what Co-Scientist surfaces. The system identified a potential mechanism linking AK2 gene mutations to a rare genetic disease — a result the research team found novel enough to pursue experimentally. The framing matters: Co-Scientist generates and ranks candidate hypotheses with flagged weaknesses; experimental verification remains entirely the researcher's responsibility. The output is a prioritized list of ideas, not a confirmed finding.
| Organization | Sector | Application | Deployment Status |
|---|---|---|---|
| Daiichi Sankyo | Pharmaceutical | Drug research acceleration | Production |
| Bayer Crop Science | Agriculture | Crop research optimization | Production |
| U.S. National Laboratories (DoE Genesis Mission) | Government / Multi-domain Research | Scientific research acceleration | Production (waitlist bypassed) |
Production adoption by Daiichi Sankyo and Bayer Crop Science confirms that Co-Scientist is past the prototype stage in pharmaceutical and agricultural research pipelines . The DoE Genesis Mission partnership is architecturally notable: U.S. National Laboratories bypassed the general waitlist under a dedicated government agreement, meaning the most compute-intensive scientific use cases are already running in production. Prior published Co-Scientist research addressed antimicrobial resistance, plant immunity, and liver fibrosis — domains outside the current enterprise partner list.
What the public materials do not disclose: the agent count, internal coordination protocol, or latency profile of the idea tournament. The specific Gemini model version (2.x or 3.x) powering Co-Scientist is also unspecified in published materials. Developers interested in building on Co-Scientist via API should treat these as unknowns until Google releases detailed technical documentation.
ERA and AlphaEvolve: Computational Discovery Through Parallelized Search
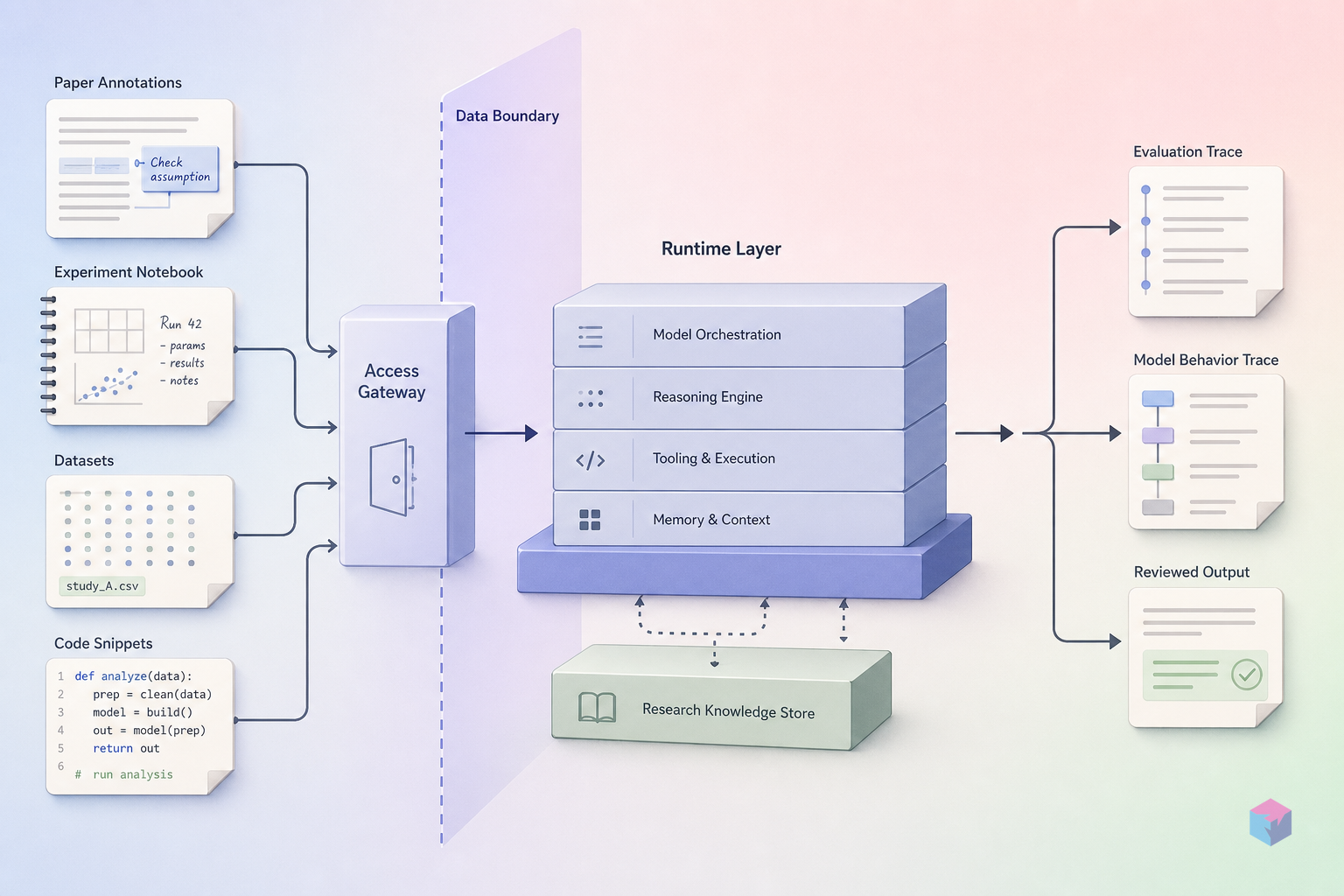
ERA (Empirical Research Assistance) and AlphaEvolve form the Computational Discovery layer — the component of Gemini for Science focused on writing and optimizing scientific software at scale. ERA acts as a code-optimizing research engine: given a scientific task and a user-specified optimization metric, it searches relevant literature, writes scientific code, and runs tree-search over thousands of code variants in parallel, scoring each against the metric. Literature search is woven into ERA's optimization loop, not a separate preprocessing step. ERA's Nature paper, published May 19, 2026 , reports performance across six domains : genomics, public health, satellite imagery analysis, neuroscience prediction, time-series forecasting, and mathematics.
The practical distinction from standard LLM code generation is the search loop itself. A standard model returns one completion per prompt. ERA generates a tree of code variants, evaluates all of them against domain-specific scientific metrics, and iterates — the final output is the best-performing variant after many evaluation rounds, not the first plausible completion. This design suits optimization problems where you have a quantifiable objective: forecast accuracy, genomic alignment quality, model efficiency. It is not optimized for one-shot coding tasks where any working solution is the acceptance criterion.
AlphaEvolve operates with a different mechanism. Where ERA targets empirical software optimization against domain metrics, AlphaEvolve applies evolutionary algorithm search over code and mathematical structures — a broader search space suited for mathematical structure discovery rather than metric-driven code optimization. Enterprise partners BASF (supply chain optimization) and Klarna (ML model optimization) are in private preview with AlphaEvolve as of launch. The two systems are complementary rather than interchangeable: ERA for code optimization against measurable scientific metrics, AlphaEvolve for structure search over a wider mathematical space.
For developers evaluating the Computational Discovery layer: ERA and AlphaEvolve appear to have distinct access paths. AlphaEvolve is in private enterprise preview, suggesting a separate engagement track from the Labs waitlist. ERA is the component accessible via interest registration at labs.google/science under the Computational Discovery label. Whether they will share API surface, authentication, or billing in a future release has not been disclosed. The backbone Gemini model version powering ERA is also unspecified in public materials.
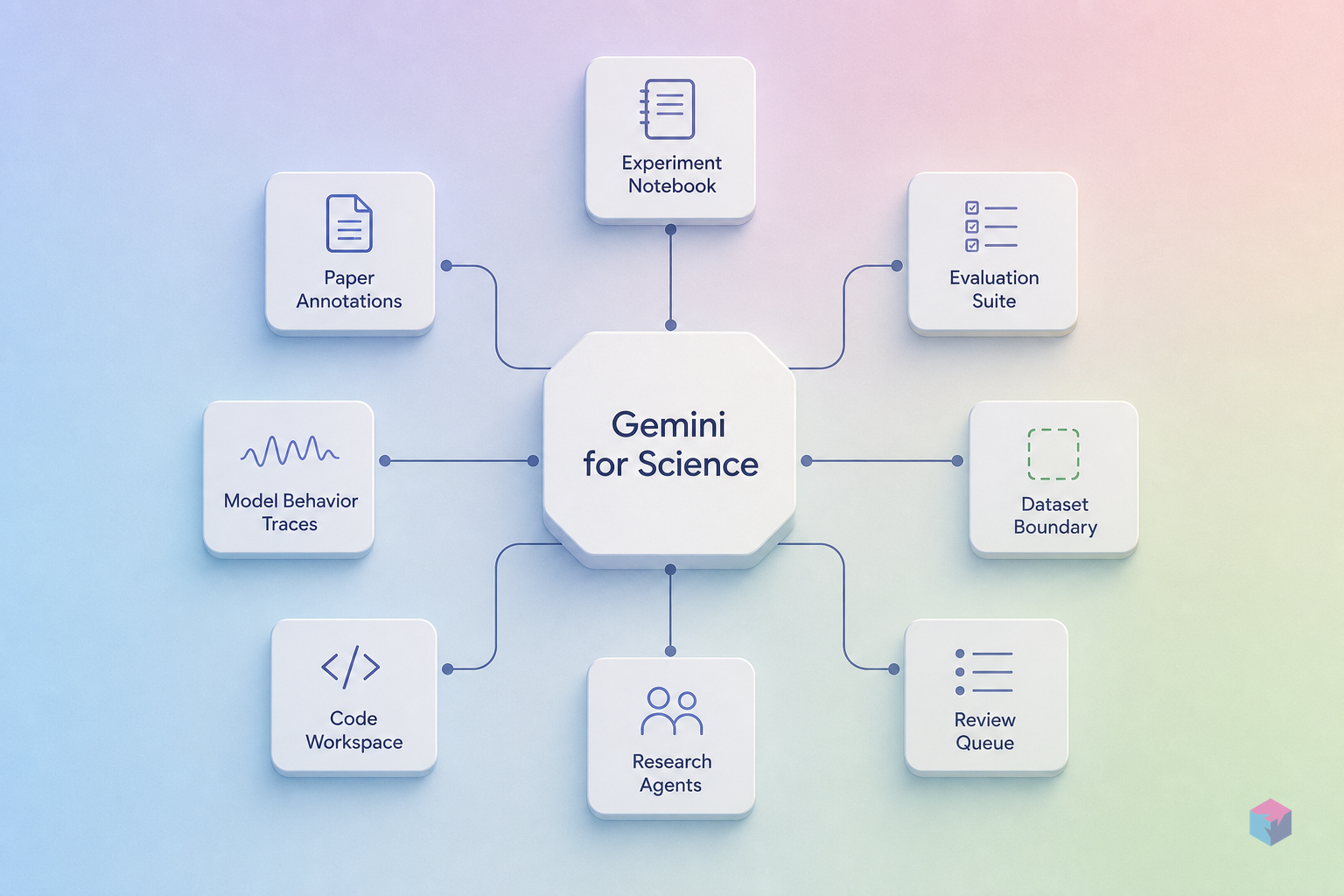
Science Skills: Connecting Gemini to 30+ Life Science Databases
Science Skills is the structured-query layer within Google Antigravity 2.0 — Google's agentic orchestration environment. It connects Gemini to more than 30 life science databases — including UniProt, the AlphaFold Database, the AlphaGenome API, and InterPro — enabling researchers to query across protein sequences, predicted 3D structures, genomic annotations, and protein family classifications through a natural language interface. Unlike the three Labs tools, Science Skills requires no waitlist and is available immediately at antigravity.google/use-cases/science .
The positioning is deliberately narrow. Science Skills is not a generative hypothesis tool, a literature organizer, or a code optimizer. It is a query orchestration layer for researchers who already know what biological data they need and want Gemini-level natural language to handle retrieval and cross-database integration — removing the need to write separate API calls for each system or switch between database interfaces mid-workflow. The integration targets structural bioinformatics and computational genomics workflows where data sources are well-defined and the friction is context-switching.
The architectural distinction from the Labs tools has direct adoption implications. Antigravity 2.0 is an agentic development platform; Science Skills slots into it as an agent skill, not a standalone product. Developers already building on Antigravity 2.0 can add Science Skills to existing agent workflows immediately. Teams not yet on Antigravity 2.0 need to evaluate the platform as a prerequisite , not just the Science Skills component itself. That onboarding step is worth factoring into any evaluation timeline.
Published Performance: ERA vs. CDC Forecasting and Official Climate Baselines
ERA's published performance benchmarks are the most concrete technical evidence in the Gemini for Science announcement. Across U.S. hospital-admission forecasting for flu, COVID-19, and RSV, ERA's predictions "consistently rank at or near the top" of CDC leaderboards . On season-averaged accuracy across all three respiratory viruses, ERA outperformed the CDC's own COVID-19 hospitalization forecasting ensemble — the benchmark model maintained by the federal public health agency that all participating forecasters are measured against.
"ERA's U.S. hospital-admission forecasts for flu, COVID-19, and RSV consistently rank at or near the top of CDC leaderboards, outperforming the CDC's own hospitalization forecasting ensemble on season-averaged accuracy across all three respiratory viruses." — ERA Research Team, Google DeepMind (source: ERA Nature Publication Blog, 2026-05)
| Domain | Task | ERA Result | Reference Baseline |
|---|---|---|---|
| Epidemiology | U.S. hospital admissions — flu, COVID-19, RSV | At or near top of CDC leaderboards | All CDC-tracked forecasting models |
| Epidemiology | COVID-19 hospitalization forecasting (season-averaged) | Outperformed CDC ensemble | CDC's own ensemble model |
| Hydrology | California spring runoff prediction | More accurate than B120 outlook | California official B120 seasonal forecast |
| Atmospheric Science | CO₂ atmospheric concentration mapping | Unprecedented spatial and temporal resolution | Prior methods |
| Energy | Solar panel design optimization | 500-triangle volumetric fan geometry | Prior geometric designs |
| Retail | Commercial forecast accuracy | Met or exceeded consensus estimates | Commercial consensus |
Several benchmarks are independently interpretable. California's B120 outlook is the state's primary seasonal water-supply forecast used for agricultural planning and municipal water allocation — not an internal research baseline. ERA outperforming the B120 is a claim against a published, operationally significant forecast . The solar panel design result — a 500-triangle volumetric fan geometry as the optimized output — illustrates what ERA's tree-search architecture actually produces: a specific engineered design derived from iterative code optimization, not a general recommendation.
The benchmark framing warrants scrutiny. All reported results come from Google's own Nature paper and supporting blog posts. Peer review validates methodology and internal consistency — it does not constitute independent reproduction. As of May 30, 2026 , no independent third-party replication of ERA's CDC performance or California hydrology results had been published. These benchmarks are the right thing to track as the broader research community evaluates them.
Early Registration Status and What Remains Experimental

Interest registration for the three Google Labs tools has been open since May 19, 2026 at labs.google/science. Rollout is gradual; no timeline for general registrant access has been disclosed. Named enterprise partners — Daiichi Sankyo, Bayer Crop Science, BASF, Klarna, and U.S. National Laboratories under the DoE Genesis Mission — are already past the waitlist phase. The DoE partnership bypassed the queue entirely under a dedicated government agreement .
All three Labs tools carry an explicit "experimental" label. No SLA or production-readiness commitment appears in any published materials. No pricing tier has been announced for Literature Insights, Co-Scientist, or Computational Discovery. This is consistent with Google Labs' standard experimental release posture — but teams evaluating these tools for production research pipelines should plan for API-level access terms, rate limits, and cost structures to be disclosed at a later stage.
Science Skills is the exception. Available immediately through Google Antigravity 2.0, it carries no experimental label and requires no waitlist. For research teams working with structured biological databases who need Gemini-level query integration today, Antigravity 2.0 is the current entry point .
Several technical details remain undisclosed as of launch: the Gemini model version powering Co-Scientist and ERA, the internal agent coordination architecture for the idea tournament, and the validation infrastructure for ERA's out-of-benchmark generalization. Over 100 academic institutions are collaborating to validate the suite — named partners include Stanford School of Medicine, Imperial College London, and the Francis Crick Institute . Independent validation output from these partners should surface over the next several months and provide the clearest signal on whether published benchmarks hold outside Google's own evaluation infrastructure.
Frequently Asked Questions
How is Gemini for Science different from using standard Gemini in a research context?
Gemini for Science bundles three purpose-built systems not exposed in the standard Gemini product or API. Literature Insights structures findings from an uploaded corpus into citation-linked evidence tables and generates slides and infographics — standard Gemini returns prose summaries with no per-cell source traceability. Co-Scientist runs a multi-round hypothesis tournament where agents generate, debate, and rank candidates iteratively — standard Gemini produces a single-pass response to a prompt. ERA performs tree-search over thousands of code variants scored against user-defined scientific metrics — standard Gemini code generation returns one completion per prompt. None of these behaviors are accessible through the standard Gemini interface or via the general Gemini API.
What does ERA do that standard LLM code generation doesn't?
Standard LLM code generation returns one code completion per prompt. ERA runs tree-search over thousands of code variants in parallel, scores each against user-defined optimization metrics, and iterates. Literature search is integrated into the loop: ERA reads relevant papers, generates code variants informed by that literature, scores them against the metric, and refines. The output is the best-performing variant after many evaluation rounds — not the first plausible completion. This makes ERA suited for scientific optimization problems with a quantifiable objective (forecast accuracy, genomic alignment quality, ML model performance) rather than one-shot tasks where any working solution meets the bar.
Is Co-Scientist available now, or is there a waitlist?
Interest registration for Co-Scientist opened May 19, 2026 at labs.google/science. Rollout is gradual with no stated timeline for when new registrants will receive access. Named enterprise partners — Daiichi Sankyo, Bayer Crop Science, and U.S. National Laboratories under the DoE Genesis Mission — are already in production, having bypassed or pre-empted the general queue. Science Skills on Google Antigravity 2.0 is available immediately without registration, but it is a structured biological database query layer, not Co-Scientist's hypothesis generation system. These are distinct tools with distinct access paths.
How does Literature Insights compare to tools like Elicit or Consensus?
Elicit and Consensus are primarily search-and-filter interfaces: they surface relevant papers from large indexed databases with structured study attributes, helping researchers find what they need. Literature Insights starts after retrieval — it works on an uploaded corpus and maps findings to structured evidence tables with per-cell source links. Multimodal output (slide decks and infographics generated directly from a research corpus) is a capability neither Elicit nor Consensus offers. Teams that already hold a literature corpus and need structured synthesis with citation traceability throughout the output are working at a different workflow step than teams using search-first tools to identify relevant papers in the first place. According to published analysis, the table-generation and multimodal output are the key differentiating capabilities.
What is Google Antigravity 2.0 and how does Science Skills fit in?
Google Antigravity 2.0 is Google's agentic orchestration environment, accessible at antigravity.google. Science Skills is a set of agent skills within Antigravity 2.0 that connects Gemini to more than 30 life science databases — including UniProt, the AlphaFold Database, the AlphaGenome API, and InterPro — as a structured-data query layer. Unlike the three experimental Labs tools, Science Skills requires no waitlist and is available immediately. It targets researchers who need Gemini-level natural language querying across structured biological databases without writing separate API pipelines for each data source. Antigravity 2.0 is a platform prerequisite, not a standalone product: developers not yet on Antigravity 2.0 should factor that onboarding step into their evaluation timeline before assessing Science Skills specifically. Coverage at Creati.ai provides additional context on the Antigravity platform positioning.
What to Build With, What to Watch For
Gemini for Science is the most substantive deployment of Google's multi-year frontier AI investment into the research lifecycle. ERA and Co-Scientist arrive with peer-reviewed Nature papers and active production deployments at Daiichi Sankyo, Bayer Crop Science, and U.S. National Laboratories — not announced as future capabilities. Literature Insights extends NotebookLM's proven document intelligence into structured evidence tables with per-cell citation traceability. Science Skills provides immediate, no-waitlist biological database integration for teams already on Antigravity 2.0.
The practical split for research engineering teams is clear. Science Skills on Antigravity 2.0 is available now and targets structured biological database queries. The three Labs tools — Literature Insights, Co-Scientist, ERA — require interest registration at labs.google/science with gradual rollout and no disclosed pricing. Enterprise teams at pharmaceutical or national lab scale should investigate the DoE Genesis Mission and existing partner engagement tracks directly rather than the general registration queue. AlphaEvolve remains in private enterprise preview; BASF and Klarna are the current access holders. The full I/O 2026 announcement context situates Gemini for Science within a broader push that also includes Gemma V4 open weights and MedGemma.
The benchmarks are the most important signal to track over the next six months. ERA's CDC forecasting performance and California runoff accuracy are specific, verifiable claims published in a peer-reviewed journal. As independent groups attempt to reproduce those results — and as Stanford School of Medicine, Imperial College London, and the Francis Crick Institute publish their validation findings — those follow-up papers will determine whether the performance holds outside Google's own evaluation infrastructure. Register interest now if the research applications are directly relevant; calibrate confidence in the published numbers against independent validation as it emerges.
Last updated: 2026-05-30. Based on Google I/O 2026 announcement materials and Nature papers published May 19, 2026; no independent third-party reproductions of ERA or Co-Scientist benchmarks had been published as of this date.






