
What Nine Official Demos Are Claiming to Prove
On May 29, 2026, Google published "9 demos of Gemini Omni and Gemini 3.5 in action," a curated video set authored by Zahra Thompson consolidating the most demo-rich capability proofs from Google I/O 2026 and supplementing them with additional recordings published post-event . The post covers two distinct model families, both announced at Google I/O on May 19, 2026 , and their claims are structurally different enough that examining them together without separation obscures what is actually being tested.
Quick Answer: Google's nine official demos (published May 29, 2026) test two separate claims: Gemini Omni preserves scene physics and character identity across multi-turn video edits without regenerating the full clip, while Gemini 3.5 Flash delivers approximately 4× more output tokens per second than Gemini 3.1 Pro on coding and parallel-agent tasks. Only Flash is callable via API today; Omni remains demo-only.
Gemini Omni is the video-editing model. Its core claim is that it can process natural-language edit instructions across multiple conversational turns on an existing video clip, without triggering a full clip regeneration between turns. Demos attempt to substantiate this by presenting before-and-after footage where specific surface materials, physics behaviors, or camera angles change while other scene properties — lighting direction, shadow geometry, character identity — remain constant.
Gemini 3.5 Flash (API model ID: gemini-3.5-flash) is the coding and agentic model, GA since May 19, 2026 . Its claim is throughput: approximately 4× output tokens per second compared to Gemini 3.1 Pro . Flash demos illustrate this through parallel sub-task execution — multiple agents running concurrently inside AI Studio — and an agentic personal assistant completing cross-app actions in real time.
These two claims require different verification criteria. The Omni claim depends on observable visual consistency in footage — something a viewer can inspect and reason about directly. The Flash throughput claim depends on benchmark scores and API performance figures that must be measured externally. The sections below examine both, keeping verification criteria separate and noting what each demo set does and does not demonstrate.
How Omni Edits Without Regenerating the Clip
Gemini Omni's defining technical property is scene-persistent editing. Prior video generation models, including Veo 3.x, required a full clip regeneration from a new prompt for every change — no scene memory was carried across turns, and developers who wanted a revised angle or different material had to accept whatever the model generated fresh from the new prompt. Omni changes this by fusing four discrete components into a single pipeline .
Google DeepMind CEO Koray Kavukcuoglu described the architectural composition in his May 19, 2026 blog post:
"Omni is a new architectural fusion: Gemini's reasoning engine, Veo's rendering layer, DeepMind's Genie world simulation, and a Nano Banana image-editing layer — a model that edits video via natural-language multi-turn conversation rather than prompt-to-new-clip regeneration." — Koray Kavukcuoglu, CEO, Google DeepMind (source: Google DeepMind Blog, May 2026)
Each component maps to a specific preservation property visible in the demo footage:
- Gemini reasoning engine: Interprets the natural-language instruction in the context of the existing scene, determining what should change versus what should be held constant. This is what enables a "relocate the musician" instruction to modify the environment without touching the musician's identity.
- Veo rendering layer: Handles visual synthesis of the modified clip, constrained by scene context rather than free-generating from a new prompt. The output remains anchored to the prior state.
- DeepMind Genie world simulation: Maintains a physics-aware representation of the scene — gravity, light propagation, surface interaction — that propagates correctly through edits. This is the component responsible for physically correct ripple propagation in the Liquid Mirror demo rather than arbitrary procedural animation.
- Nano Banana image-editing layer: Handles fine-grained surface and material manipulation — material swaps, texture application, nested visual transforms — without disrupting broader scene state. This enables the stone-to-soap-bubble substitution in the Bubble Sculpture demo while preserving shadow geometry.
The practical workflow implication: when you tell Omni to move the violinist to a concert hall, the model does not forget the violinist's face. When you then request an over-the-shoulder camera angle, it does not reset the concert hall or the musician's position. Scene state accumulates rather than resets between conversational turns. This moves video editing closer to the iteration patterns developers already use with text and code — successive refinements on a stable base, not regenerations from a new starting point.
One architectural feature with no prior equivalent is the Reimagine Action capability, which enables complex nested transformations within a single instruction. The Checkerboard Sphere demo places a large-scale room pattern recursively inside a glass sphere with independent internal lighting — a transformation requiring understanding of spatial containment, scale shift, and dual lighting simultaneously . Prompt-based regeneration models cannot replicate this because they have no persistent scene representation to reason about hierarchically.
At launch, Omni enforces a 10-second clip duration cap . Google has characterized this as a deployment decision rather than a technical ceiling, with extension expected over time. Audio editing is withheld at launch due to deepfake concerns — a constraint that limits editing completeness for clips with dialogue, but was stated transparently rather than quietly omitted.
The Omni Demo Set: Scene Consistency Claims Examined
Google's four Omni demos each test a different aspect of scene preservation — material transformation, physics simulation, multi-turn identity stability, and nested spatial composition. Examining each individually clarifies what the claims are actually asserting and where the limits of demo-based verification apply .
Demo-by-Demo Breakdown
| Demo | Edit Instruction (Summary) | What Changed | What Was Claimed Preserved | Strongest Verification Signal |
|---|---|---|---|---|
| Bubble Sculpture | "Make the sculpture out of bubbles" | Stone surface → translucent soap material with iridescent highlights | Composition, lighting direction, shadow geometry | Shadow cast angle unchanged — same directional light source before and after material swap |
| Liquid Mirror | "Make the mirror ripple like liquid; turn the arm into reflective mirror material" | Static mirror → outward ripple propagation; skin → chrome surface | Physics from touch point; room reflected accurately in chrome arm | Ripples originate at contact point with correct outward spread; chrome surface reflects actual room geometry, not generic HDR map |
| Violinist Multi-Turn (Turn 1) | Relocate musician to new environment | Stage background → new setting | Facial features, posture, instrument grip | Identity stable across complete background replacement |
| Violinist Multi-Turn (Turn 2) | Over-the-shoulder camera angle | Viewing angle shifted without scene reset | All prior identity and environment state from Turn 1 | Camera change without triggering new-clip generation — scene state carries across both prompts |
| Checkerboard Sphere (Reimagine Action) | Place room's checkerboard pattern inside glass sphere recursively | Glass sphere → displays miniature room with independent internal lighting | Outer room geometry, hand position, sphere shape | Sphere interior lit independently from outer scene — hierarchical lighting requires dual scene representation |
The Bubble Sculpture demo is the most straightforward to inspect for the preservation claim. The assertion is that shadow geometry is held constant while surface material changes. In the footage, directional shadows maintain the same cast angle before and after the material swap. This would be inconsistent if the model had regenerated the clip from a new prompt — a freshly generated clip described as "bubbles" would not reliably reproduce the identical shadow geometry as the original stone sculpture, because the lighting setup is not encoded in the text description .
The Liquid Mirror demo layers two distinct verification signals. The ripple physics claim — propagation outward from the point of contact — is testable from the footage: random or procedurally generated ripples would not necessarily originate from the touch point with correct physics. The chrome reflection claim requires that the renderer carried scene context. A synthetic chrome surface invented mid-clip would reflect either nothing or a generic environment map, not the specific room geometry visible in the original footage. Both properties are observable, though not independently auditable from a demo video alone.
The Violinist Multi-Turn sequence is the most direct demonstration of what "multi-turn" means operationally. Three sequential edit prompts — original stage, relocated environment, over-the-shoulder angle — are applied with the musician's facial features, instrument grip, and posture remaining consistent throughout. An important caveat applies here: the demos were selected and edited by Google's team. The footage does not show processing latency per turn, failed attempts, or cases where identity drift occurred. These gaps are standard in demo-format capability presentations across the industry; they do not invalidate the claim, but they define the extent of what the footage alone can establish.
The Checkerboard Sphere (Reimagine Action) is compositionally the most complex edit in the set. The instruction requires Omni to recursively place a large-scale room pattern inside a small glass object with independent internal lighting — understanding spatial containment, scale shift, and dual lighting rigs within a single transformation . This is also the demo most dependent on the Nano Banana and Genie components working in conjunction, and the one that would be most difficult to produce through prompt regeneration — a fresh clip prompted as "room inside sphere" would lack the spatial and lighting specificity of the original scene.
3.5 Flash's Parallel Coding Demos: Speed in Practice
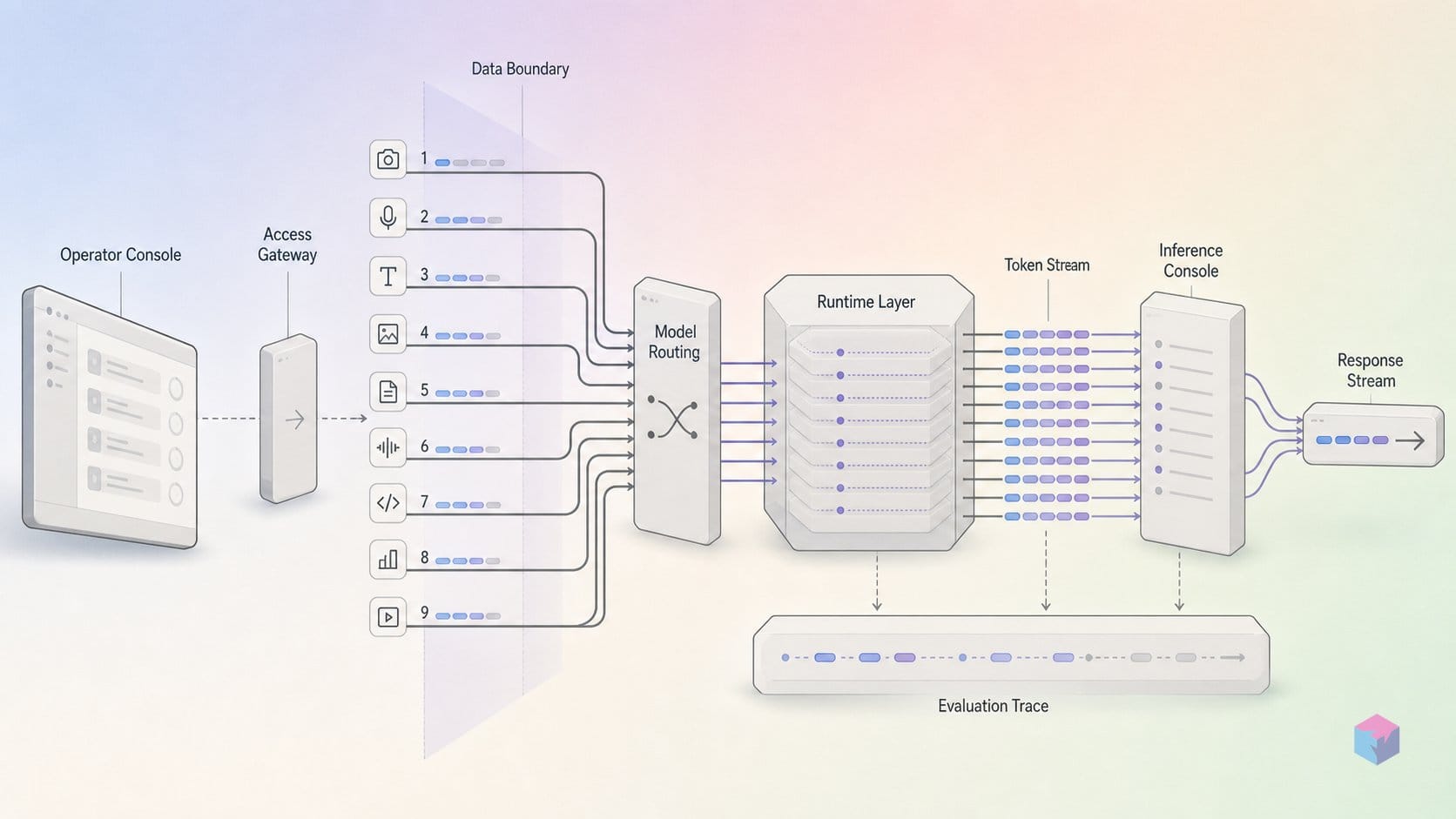
Gemini 3.5 Flash's five demos are structured differently from the Omni set. Rather than showing visual transformations, they demonstrate throughput — specifically, what happens when parallel sub-tasks are routed through a fast model rather than serialized through a slower one. The key signal is not per-token quality but iteration density: how many meaningful variations a developer or agent can generate within a fixed time window .
| Demo | Task Type | Parallelism Pattern | Claimed Output | Developer Relevance |
|---|---|---|---|---|
| Antigravity 2.0 IDE — Asset Categorization | Agentic: rename + categorize unstructured digital assets | Collaborative sub-agents running concurrently | Full asset library organized autonomously, no human loop required | Parallel sub-task dispatch reduces wall-clock time for broad file operations; Flash's throughput is the enabling factor |
| Pi Visualization | Interactive web UI generation | Parallel creative concept sub-agents in AI Studio | Multiple UI approaches for the same mathematical concept generated in one session | Rapid iteration on visual design problems where multiple candidate outputs beat one polished result |
| 64 Fractal Variations | Generative design exploration | Batch parallel generation | 64 distinct fractal design variations in a single session | High-count batch generation is Flash's throughput advantage realized at scale — same generation count via slower model takes ~4× longer |
| Checkout UX in 60 Seconds | Iterative UX and code generation | Iterative coding loops inside AI Studio | Multiple checkout flow design approaches under 60 seconds | Short feedback loops; useful for early-stage UI prototyping with human-in-the-loop selection; replicable today in AI Studio |
| Gemini Spark — Personal Agent | Cross-app proactive orchestration | Single persistent agent, multi-app integration | Nut-free snack list generated → pushed to Instacart; Gmail/Docs/Slides integration | 3.5 Flash as backbone for always-on agentic workflows; latency at inference time matters more than maximum reasoning depth here |
The Antigravity 2.0 IDE demo surfaces a product distinction worth flagging immediately. Antigravity 2.0 is an agentic coding environment — not the Gemini API itself. It is the orchestration runtime that dispatches and coordinates the parallel sub-agents shown in the demo. No public release date appears in official I/O materials for Antigravity 2.0 . The underlying Flash model is callable today via the API; the orchestration layer shown in the demos is not available externally.
The 64 Fractal Variations demo makes the throughput argument most explicitly. Generating 64 distinct creative variations in one session requires sustaining high output token rates without degradation. At approximately 4× the tokens-per-second of 3.1 Pro, Flash makes this kind of batch creative exploration feasible within a reasonable time window . The same batch run through a slower model at equivalent quality would take roughly four times as long — a compounding difference for iterative design workflows where time-to-first-good-option matters.
The Checkout UX demo is the most immediately replicable for developers with AI Studio access today. Iterative code generation inside AI Studio, running successive refinements of a UI component with Flash's throughput compressing the feedback loop, requires no Antigravity 2.0. This is the demo most directly applicable to a developer's existing workflow without waiting for additional product availability.
The Gemini Spark demo is the most infrastructure-dependent of the five. The 24/7 proactive agent behavior — generating a nut-free snack list and pushing it to Instacart without explicit prompting — requires persistent session state and cross-app authorization. Google indicated broader beta access for AI Ultra subscribers within approximately one week of the May 19, 2026 I/O announcement . As a consumer product rather than a developer API, its architecture is not directly portable to custom agent implementations.
Is the Scene-Preservation Claim Verified?
Two tiers of evidence exist for the Omni demos: Google's official curated nine-video set and an independently documented expanded set. The Omni architectural claim has a specific, testable structure — but benchmark data from a recognized external source is absent as of May 31, 2026, and the demos leave several operational questions unanswered.
nvinio.com independently documented 11 total demo variants from the I/O period — two more than Google's official May 29 post . The additional variants included a Search-based Information Agent tracking athlete sneaker collaboration announcements continuously, and a Generative UI demo for Gyroid patterns. The broader coverage confirms the demo set is wider than the official curated post presents — useful signal when evaluating whether Google is showing only favorable edge cases or testing across varied task types.
"The Bubble Sculpture and Liquid Mirror demos exhibit the kind of physically consistent behavior — identical shadow geometry, correct ripple propagation from contact points — that would be inconsistent with fresh clip generation. This offers stronger verification signal than purely visual similarity claims alone." — AtlasCloud AI analysis, May 2026
Kavukcuoglu's layer-by-layer architectural description in the May 19 blog maps specifically to what is observable in the footage . The Genie world simulation component is the claimed source of physics propagation in the Liquid Mirror demo — and the physically correct outward ripple propagation from the touch point is exactly what a world-physics representation would produce. A model without that component would generate visually plausible but physically arbitrary ripple patterns. The Nano Banana layer, responsible for material editing, corresponds to what is observable in the Bubble Sculpture transformation: surface material replaced without disturbing the directional lighting setup. This correspondence between stated architecture and observed demo behavior is meaningful, though it does not constitute an independent audit.
What the demos do not show, and what remains unknown:
- Per-edit processing latency: No timing data appears in the footage. Whether each edit takes 5 seconds or 120 seconds is not established by the demos.
- Context window limits across turns: How many sequential edits Omni can sustain before scene state degrades is not addressed in the demo set or in any published technical documentation as of May 31, 2026.
- Failure cases: No degraded outputs or failed transformations are shown. This is standard for product demos across the industry — not a specific criticism — but relevant for forming calibrated expectations.
- Absolute quality positioning: Independent reviewers have characterized Omni as solid mid-to-upper tier on raw cinematic fidelity, trailing Seedance 2.0 and Kling 3.0 on cinematic quality . The scene-preservation capability is differentiated; absolute output quality is not the top of the current market.
For Flash's 4× throughput claim: this figure originates from Google's own May 19, 2026 release documentation . No independent benchmark at a recognized leaderboard has published Flash-vs-3.1-Pro throughput comparison data as of May 31, 2026. The task-accuracy benchmarks that have been published — Terminal-Bench 2.1, GDPval-AA, MCP Atlas — are from Google's own release materials . Treat the 4× number as directionally credible but unverified by an external source until independent results appear.
What's Live in Vertex AI vs. Still Under Preview
As of May 31, 2026, the two model families sit at very different stages of developer availability. Conflating them leads to either premature roadmap planning or missed near-term opportunities. The table below reflects confirmed status, not marketing positioning.
gemini-3.5-flash is GA on Vertex AI and Google AI Studio, with the model ID confirmed and callable today . It has been the default model in the Gemini consumer app since May 19, 2026 — reaching users at scale before most developers have integrated it. API pricing is published: $1.50 per million input tokens, $9.00 per million output tokens, and $0.15 per million cached input tokens . This is roughly 25% cheaper than Gemini 3.1 Pro's $2.00/$12.00 rates — a meaningful cost reduction for high-volume agentic workloads where Flash's accuracy on the target task is sufficient.
Gemini Spark (3.5 Flash-powered) entered AI Ultra subscriber preview immediately post-I/O, with broader rollout expected within approximately one week of the May 19, 2026 announcement . As of May 31, that stated window has elapsed; AI Ultra subscribers should check current availability. Gemini Spark is a consumer product — it is not a developer API surface.
Gemini Omni is demo-only as of May 31, 2026. There is no public API endpoint, no developer preview program, no announced timeline, and no published developer API pricing . Google's stated position is "coming in the coming weeks" — language that has appeared in multiple official communications without a firm date attached. Consumer-facing access is more defined: free on YouTube Shorts and YouTube Create App, with paid tiers at AI Plus ($7.99/month), AI Pro ($19.99/month), and AI Ultra ($99.99/month or $199.99/month) . None of this is a developer API.
Antigravity 2.0 IDE has no public release date in official I/O materials and should be treated as internal tooling until Google states otherwise. The parallel sub-agent dispatch pattern it demonstrates can be approximated today using the Gemini API with manually orchestrated concurrent calls — the underlying model is available, the proprietary orchestration environment is not.
Two additional gaps worth tracking for planning purposes: Gemini 3.5 Pro is reportedly in internal use at Google, with Sundar Pichai targeting June 2026 for broader availability — no committed date has been given. And Omni's audio editing capability is deferred indefinitely for safety and deepfake concerns, limiting the editing completeness of any clip containing spoken dialogue or sound design.
From 3.1 Pro to 3.5 Flash: Speed Gains and Compatibility

If you are running gemini-3.1-pro in production today and want to evaluate an upgrade, the path is a model ID swap to gemini-3.5-flash — the first model in the Gemini 3.5 series, GA since May 19, 2026 . Whether that swap makes sense depends entirely on your workload shape.
The throughput gain — approximately 4× output tokens per second versus 3.1 Pro — has the highest practical payoff in high-frequency coding loops, iterative generation pipelines, and parallel sub-task patterns . These are exactly the workload shapes the I/O demos were designed to show. If your application dispatches many concurrent generation calls, serializes multiple model calls per user action, or runs a coding assistant loop where latency between iterations is directly visible to users, the throughput difference compounds quickly. The cost reduction — roughly 25% cheaper per token than 3.1 Pro at $1.50 vs $2.00 per million input tokens — makes the case stronger for high-volume workloads .
Flash's published advantage on task-accuracy benchmarks, per Google's May 19, 2026 release data:
- Terminal-Bench 2.1: 76.2% (Flash) vs. 70.3% (3.1 Pro)
- GDPval-AA: 1,656 Elo (Flash) vs. 1,314 Elo (3.1 Pro)
- MCP Atlas: 83.6% (Flash) vs. 78.2% (3.1 Pro)
- CharXiv Reasoning: 84.2% (Flash)
Areas where 3.1 Pro still leads Flash, per the same release data:
- Humanity's Last Exam: 44.4% (Pro) vs. 40.2% (Flash)
- ARC-AGI-2: 77.1% (Pro) vs. 72.1% (Flash)
- Long-context 128k retrieval: 84.9% (Pro) vs. 77.3% (Flash)
The cases where holding on 3.1 Pro is justified: workloads dependent on deep reasoning over complex documents, tasks near the frontier of formal reasoning difficulty, and long-context retrieval at 128k tokens where the 7.6 percentage point gap in retrieval accuracy is operationally meaningful. For these, Flash's throughput advantage does not compensate for the capability regression. Note that Flash's context window is 1,048,576 input tokens with 64K output capacity and a knowledge cutoff of January 2026 — the input window size is equivalent to 3.1 Pro; it is retrieval accuracy at long context that differs, not the window itself.
One important caveat applies to all the benchmark figures above: they come from Google's own release documentation, not from independently run third-party evaluations at a recognized leaderboard. Treat the directional signal as credible, but run evaluation on your specific workload and task distribution before committing to a full cutover. TechCrunch's May 19, 2026 analysis of Flash noted Google's explicit bet on agents over chatbots as the design orientation — the benchmark selection reflects this, favoring agentic and coding task types where Flash's throughput profile is most advantageous .
Frequently Asked Questions
How is Gemini Omni different from Veo 3?
Veo 3 regenerates a complete new clip from a new prompt on every edit request — there is no scene memory carried between turns. Gemini Omni preserves scene context across multi-turn conversational edits: physics simulation (via the Genie world simulation layer), lighting geometry, and character identity persist through successive instructions without resetting. Architecturally, Omni fuses Gemini's reasoning engine with Veo's rendering layer, DeepMind's Genie world simulation, and a Nano Banana image-editing layer . This creates a pipeline where scene state accumulates rather than resets between edits — fundamentally changing how iterative video editing works compared to prompt-and-regenerate models.
Is gemini-3.5-flash available in the API today?
Yes. gemini-3.5-flash reached general availability on May 19, 2026 on both Vertex AI and Google AI Studio . It is the first model in the Gemini 3.5 family and functions as a drop-in replacement for existing 3.x API integrations. Published API pricing: $1.50 per million input tokens, $9.00 per million output tokens, $0.15 per million cached input tokens — approximately 25% cheaper than Gemini 3.1 Pro at equivalent quality for coding and agentic tasks . Context window is 1,048,576 input tokens with 64K output capacity.
When will Gemini Omni be accessible to developers?
No developer API or preview program has been announced as of May 31, 2026. Google's stated position is "coming in the coming weeks" with no firm date or pricing published for the developer API tier. Consumer-facing access is defined: Omni is available free on YouTube Shorts and YouTube Create App, with paid tiers at AI Plus ($7.99/month), AI Pro ($19.99/month), and AI Ultra ($99.99/month or $199.99/month) . Audio editing remains deferred for deepfake safety reasons. Do not build developer-facing timelines around the Omni API until a specific date and pricing are announced.
How much faster is Gemini 3.5 Flash than 3.1 Pro?
Approximately 4× output tokens per second, per Google's May 19, 2026 release documentation . Flash also outperforms 3.1 Pro on coding and agentic benchmarks: Terminal-Bench 2.1 (76.2% vs 70.3%), GDPval-AA (1,656 Elo vs 1,314 Elo), MCP Atlas (83.6% vs 78.2%) . Third-party independent throughput benchmarks have not been published as of May 31, 2026. The 4× figure is Google's own claim — directionally credible, not yet externally verified.
What is the Antigravity 2.0 IDE shown in the Flash demos?
Antigravity 2.0 is the agentic coding environment used in the 3.5 Flash I/O demos for parallel asset categorization and collaborative sub-task execution. It is a separate product from the Gemini API — it serves as the orchestration runtime dispatching parallel sub-agents. No public release date appears in official I/O materials as of May 31, 2026 . Treat it as internal tooling until Google announces external availability. The underlying Flash model that powers it is callable today via the API; the parallel orchestration environment shown in demos is not.
What to Build Now, and What to Wait For
The two model families from Google I/O 2026 are at materially different stages of readiness, and the practical decision for a developer is straightforward once the availability is separated from the demo presentation. gemini-3.5-flash is available, priced, and has published benchmark data. If your workload is parallel agentic tasks, iterative code generation, or high-frequency user-facing generation where latency compounds, the throughput and cost profile is worth evaluating immediately. The strongest case for holding on 3.1 Pro is long-context retrieval at scale and frontier reasoning tasks — both of which have measurable regressions in Flash's published benchmarks. Run a targeted A/B evaluation on your specific task distribution before a full cutover; the benchmark profiles are from Google's own release materials and reflect a design orientation toward agentic workloads.
For Omni: the scene-preservation architecture addresses a genuine limitation of the prior prompt-and-regenerate model — the multi-turn conversation pattern maps more naturally to how developers iterate than the Veo 3.x regeneration cycle. But it is not callable, has no published API pricing, and has no confirmed timeline beyond "coming weeks." The demo evidence for the preservation claim is stronger than typical product marketing — the shadow geometry and physics propagation signals are observable and would be hard to produce through regeneration — but the operational questions that matter for production use (latency per turn, context window across edits, degradation at depth) remain unanswered. When the API launches, those are the first numbers to benchmark.
Gemini 3.5 Pro (targeting June 2026, no committed date) and an external throughput benchmark for Flash are the two external signals that will most sharpen the decision framework over the next 30 to 60 days. Until those land, the Flash-vs-3.1-Pro comparison rests on Google's own data, which is detailed enough to act on directionally but should not be treated as independently verified .
Last updated: 2026-05-31. This article reflects official Google announcements through May 29, 2026 and independently documented demo coverage through the same date. Availability status, benchmark figures, and pricing are subject to change as third-party evaluations, Gemini API releases, and Gemini 3.5 Pro availability are confirmed.




