
NVIDIA는 2026년 5월 28일 nvidia/Qwen3.6-35B-A3B-NVFP4를 공개했습니다 — Alibaba의 35B MoE 모델을 포스트 트레이닝 FP4로 양자화한 변형으로, VRAM을 ~71 GB에서 ~23 GB로 줄여 단일 H100에서 실행할 수 있습니다. A100이나 소비자용 GPU를 사용 중이라면 주의 사항 섹션을 먼저 확인하세요 — 이 양자화 포맷은 해당 하드웨어에서 동작하지 않습니다.
71 GB → 23 GB: 무엇이 양자화되고 무엇이 남는가
NVFP4 양자화는 트랜스포머 및 MoE 블록 내부 선형 연산자의 가중치와 활성화값을 대상으로 하며, LayerNorm·임베딩·바이어스는 수치 안정성을 위해 BF16/F32로 유지됩니다 . 이 선택적 4비트 압축으로 BF16 기준 대비 디스크 용량 및 VRAM이 3.06배 감소하며, Hopper 하드웨어 기준 약 71 GB에서 ~23 GB로 줄어듭니다 .
한 줄 요약: nvidia/Qwen3.6-35B-A3B-NVFP4는 선형 연산자 가중치와 활성화값에 4비트 양자화를 적용해 35B MoE 추론 모델을 단일 H100에서 실행할 수 있게 해줍니다. VRAM은 ~71 GB에서 ~23 GB(3.06배)로 줄고, 표준 벤치마크에서 정확도 손실은 1점 이내입니다. Hopper 또는 Blackwell이 필요하며, A100과 RTX 4090은 FP4 연산 경로가 없습니다.
캘리브레이션 파이프라인은 두 가지 데이터셋을 활용했습니다: 30만 건 이상의 영문 뉴스 기사로 구성된 cnn_dailymail과 멀티턴 대화 커버리지를 위한 NVIDIA의 Nemotron-Post-Training-Dataset-v2이며, NVIDIA Model Optimizer v0.44.0으로 처리되었습니다 . 이중 데이터셋 접근 방식은 주목할 만합니다. 뉴스 기사만으로 캘리브레이션된 양자화 모델은 구조화된 멀티턴 명령어 수행에서 성능 저하가 발생할 가능성이 높으며, 벤치마크 결과가 이를 뒷받침합니다.
NVIDIA의 공식 평가 결과, 정확도 차이는 미미합니다. NVFP4는 추론 벤치마크 전반에서 BF16과 0.5~0.8점 이내의 차이를 유지하며, 명령어 수행 및 멀티모달 태스크에서는 소폭 앞서기도 합니다 :
| 벤치마크 | BF16 | NVFP4 | 차이 |
|---|---|---|---|
| MMLU Pro | 85.6 | 85.0 | −0.6 |
| GPQA Diamond | 84.9 | 84.8 | −0.1 |
| AIME 2025 | 89.2 | 88.8 | −0.4 |
| τ²-Bench Telecom | 95.5 | 94.7 | −0.8 |
| SciCode | 40.8 | 40.6 | −0.2 |
| IFBench | 62.3 | 62.8 | +0.5 |
| MMMU Pro | 74.1 | 74.5 | +0.4 |
"NVFP4 양자화 모델은 BF16 원본과 거의 동일한 정확도를 유지하면서 메모리 요구량을 3.06배 줄여, 기존에는 여러 GPU에 걸친 텐서 병렬 처리가 필요했던 하드웨어에서도 단독 배포가 가능합니다." — NVIDIA Model Optimization Team, nvidia/Qwen3.6-35B-A3B-NVFP4 모델 카드
Hopper 또는 Blackwell: 다른 GPU가 동작하지 않는 이유
FP4 텐서 코어 실행 경로는 Hopper(H100, H200)와 Blackwell(GB200, GB300, DGX Spark GB10) 아키텍처에만 존재합니다 . RTX 4090(Ada Lovelace, sm_89), RTX 5090, A100(Ampere, sm_80)에는 네이티브 FP4 연산 유닛이 없습니다. 이 GPU에서 --quantization modelopt를 전달하면 로드 시 오류가 발생하거나, 더 나쁘게는 잘못된 출력이 조용히 생성될 수 있습니다.
Hopper/Blackwell이 아닌 하드웨어에서의 대안:
- BF16 기본 모델: VRAM ~71 GB 필요 — RTX PRO 6000(96 GB) 또는 H100/A100 80 GB
- 커뮤니티 GGUF 양자화: llama.cpp를 통해 소비자용 하드웨어에서 실행 가능. unsloth/Qwen3.6-35B-A3B-NVFP4와 AEON-7/Qwen3.6-35B-A3B-heretic-NVFP4는 서로 다른 양자화 트레이드오프와 더 넓은 하드웨어 지원을 제공합니다
DGX Spark(Blackwell, sm_120/121a)는 공식 지원되지만 추가 설정이 필요합니다: CUDA 13.0과 vllm/vllm-openai:cu130-nightly Docker 이미지 . 안정화된 vLLM 릴리스에는 아직 해당 아키텍처용 FlashInfer CUTLASS MoE 커널이 포함되어 있지 않습니다. 서빙을 시도하기 전에 vLLM 빌드에 compressed-tensors NVFP4 지원이 포함되어 있는지 반드시 확인하세요 — 빌드가 맞지 않으면 조용히 폴백되거나 모델 로드 시 충돌이 발생합니다.
vLLM Serve 명령어: 표준 및 DGX Spark
Hopper에서 동작하는 최소 실행 명령어입니다. 핵심 플래그는 두 가지입니다. --quantization modelopt는 NVIDIA Model Optimizer의 compressed-tensors 백엔드를 활성화하고, --reasoning-parser qwen3는 API 응답에서 <think>...</think> 형태의 추론 블록을 제거해 호출자에게 깔끔한 완성 결과만 전달합니다:
vllm serve nvidia/Qwen3.6-35B-A3B-NVFP4 \
--port 8000 \
--quantization modelopt \
--max-model-len 262144 \
--reasoning-parser qwen3DGX Spark(Blackwell)는 실행 전에 환경 변수 세 개를 반드시 설정해야 합니다. 하나라도 빠지면 시작 시 FlashInfer MoE 커널 불일치 오류가 발생합니다. 어떤 변수가 누락됐는지 오류 메시지가 명확히 알려주지 않는 경우가 많으므로, 세 개 모두 무조건 설정하세요 :
export VLLM_USE_FLASHINFER_MOE_FP4=0
export VLLM_FP8_MOE_BACKEND=flashinfer_cutlass
export FLASHINFER_DISABLE_VERSION_CHECK=1
vllm serve nvidia/Qwen3.6-35B-A3B-NVFP4 \
--quantization modelopt \
--kv-cache-dtype fp8 \
--attention-backend flashinfer \
--moe-backend marlin \
--gpu-memory-utilization 0.85 \
--max-model-len 65536 \
--max-num-seqs 4 \
--enable-chunked-prefill \
--enable-prefix-caching \
--speculative-config '{"method":"mtp","num_speculative_tokens":3,"moe_backend":"triton"}'플래그별 설명:
--kv-cache-dtype fp8— BF16 대비 KV 캐시 메모리를 절반으로 줄여, 0.85 VRAM 활용률에서 더 긴 유효 컨텍스트를 직접적으로 확보합니다--moe-backend marlin— Blackwell용 Marlin MoE 커널을 선택합니다. 기본 선택이 이 아키텍처에서 최적이 아닐 수 있습니다--max-num-seqs 4— 제한된 VRAM 환경에서 동시 시퀀스 메모리 사용량을 예측 가능하게 유지합니다. 값을 올릴 때는 OOM 동작을 주시하며 신중하게 올리세요--enable-chunked-prefill— DGX Spark에서 필수입니다. 없으면 긴 프롬프트가 65536토큰 한도 훨씬 이전에 OOM을 일으킵니다--enable-prefix-caching— 멀티턴 대화 워크로드에서 반복되는 시스템 프롬프트의 첫 토큰 출력 시간을 단축합니다--speculative-config '{"method":"mtp",...}'— 내장 Multi-Token Prediction 헤드를 활성화합니다. 별도의 드래프트 모델 없이 동작합니다
아래 스니펫은 (예시용 — 실행 불가; 실행하려면 transformers가 설치된 CUDA 환경이 필요합니다) 모델 로드 전 GPU가 Hopper 계열인지 확인하는 방법을 보여줍니다. 핵심은 major < 9 조건입니다. H100은 sm_90, A100은 sm_80을 보고합니다:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL = "Qwen/Qwen3.6-35B-NVFP4"
if not torch.cuda.is_available():
raise SystemExit("CUDA GPU required")
name = torch.cuda.get_device_name(0)
major, minor = torch.cuda.get_device_capability(0)
print(f"GPU: {name} (sm_{major}{minor})")
if major < 9:
raise SystemExit("NVFP4 path requires H100-class sm_90+; A100 is sm_80")
tok = AutoTokenizer.from_pretrained(MODEL)
model = AutoModelForCausalLM.from_pretrained(MODEL, device_map={"": 0})
print(model.generate(**tok("Qwen NVFP4 fits on one H100 because", return_tensors="pt").to(0), max_new_tokens=8))A100은 몇 분씩 걸리는 모델 다운로드를 낭비하기 전에 SystemExit에서 멈춥니다. 가중치 저장 공간이나 대역폭을 확보하기 전에 이 검사를 먼저 실행하세요.
어디서 깨지나: 컨슈머 GPU와 잘못된 플래그
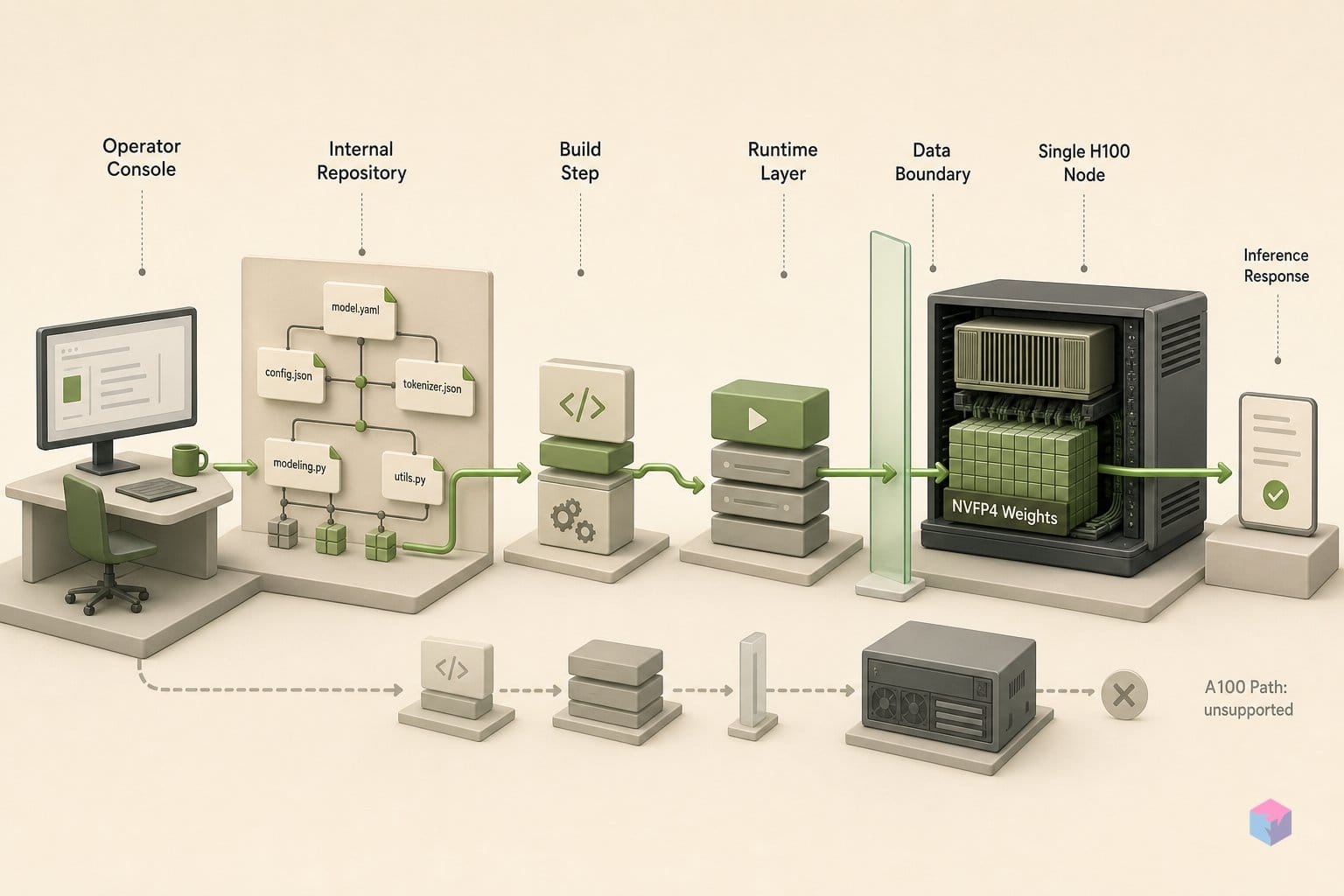
한 시간을 날리기 전에 알아둘 만한 실패 패턴 네 가지입니다:
- A100 또는 RTX 하드웨어에서
--quantization modelopt: Ampere나 Ada Lovelace에는 FP4 행렬곱 경로가 존재하지 않습니다. 로드 시 오류가 나거나, 더 나쁜 경우 출력이 조용히 저하됩니다. 해당 GPU에서는 BF16이나 GGUF를 사용하세요 — 우회 방법이 없습니다. - DGX Spark에서 환경 변수 누락: 실행 전에
VLLM_FP8_MOE_BACKEND나FLASHINFER_DISABLE_VERSION_CHECK를 빠뜨리면 FlashInfer MoE 커널 불일치가 발생합니다. 시작 오류가 어떤 변수가 빠진 건지 항상 명시하지는 않으므로, Blackwell에서 vLLM을 건드리기 전에 세 개 모두 무조건 설정하세요. --reasoning-parser qwen3누락: 모델이 모든 완성 응답에 날 것의<think>...</think>블록을 그대로 출력합니다. JSON 완성을 파싱하는 클라이언트는 잘못된 출력을 받고, 스트리밍 클라이언트는 추론 과정을 최종 사용자에게 직접 노출합니다. 이 플래그는 선택 사항이 아닙니다.- DGX Spark에서
--enable-chunked-prefill누락: 0.85 VRAM 활용률에서 긴 프롬프트가 65536토큰 한도 훨씬 이전에 OOM을 일으킵니다. 해당 플랫폼에서 청크 프리필은 성능 최적화가 아니라 모든 장문 컨텍스트 워크로드의 필수 요건입니다.
DGX Spark 프로덕션 운영 시 주의사항: vllm/vllm-openai:cu130-nightly 이미지는 안정 릴리스가 아닙니다 . 재현이 필요한 배포라면 특정 빌드 해시로 고정하거나, 업스트림에서 NVFP4 Blackwell 지원이 완전히 포함된 안정 vLLM 릴리스를 기다리세요.
더 나아가기: MTP와 긴 프롬프트

내장 MTP 투기적 디코딩 헤드는 단일 사용자 기준(512토큰 출력)에서 85.4%의 토큰 수용률을 달성하며, 4,096토큰 출력에서는 92.8%까지 상승합니다 . 별도 드래프트 모델을 로드하거나 관리할 필요 없이 MTP 헤드가 기본 체크포인트에 내장되어 있습니다. 동시성 1 기준 출력 처리량은 55.9 토큰/초이며, 동시성 32에서는 433.4 토큰/초로 확장됩니다 . 커뮤니티의 AEON-7 DFlash 변형은 DGX Spark에서 그리디 디코딩 기준 117 tok/s를 보고하며, 드래프트 수용률 62–78%, 타깃 스텝당 평균 수용 토큰 2.7–4.4를 기록합니다 .
기본 컨텍스트 윈도우는 131K 토큰이며, RoPE 스케일링을 통해 262,144까지 확장됩니다 . DGX Spark에서는 0.85 활용률 기준 안전한 VRAM 여유를 유지하기 위해 --max-model-len을 65536으로 제한하세요. H100/H200처럼 VRAM 여유가 더 많은 환경에서는 262K 전체 컨텍스트를 사용할 수 있습니다. 단, 2026년 6월 기준으로 262K 한계에서 NVFP4 대 BF16의 장문 컨텍스트 RAG 품질은 독립적으로 벤치마킹된 사례가 없습니다 — 데이터가 나오기 전까지 그 범위는 최선 노력 수준으로 간주하세요.
서버가 Hopper 또는 Blackwell에서 실행 중이라면, 같은 vLLM 엔드포인트에서 텍스트와 함께 이미지·영상 입력도 추가 플래그 없이 바로 처리됩니다. NVFP4 양자화 하에서의 멀티모달 추론 품질 역시 공개적으로 벤치마킹된 사례가 없으므로, 텍스트 벤치마크 결과를 대리 지표로 삼지 말고 실제 워크로드로 직접 평가하세요.
자주 묻는 질문
Qwen3.6-35B-A3B-NVFP4, RTX 4090이나 A100에서 쓸 수 있나요?
아닙니다. FP4 텐서 코어 경로는 Hopper(H100, H200) 또는 Blackwell(GB200, GB300, DGX Spark) 아키텍처가 필요합니다. RTX 4090은 Ada Lovelace(sm_89), A100은 Ampere(sm_80)로 — 둘 다 네이티브 FP4 연산 유닛이 없습니다. 해당 카드에서는 llama.cpp를 통한 커뮤니티 GGUF 양자화를 사용하거나, VRAM이 71GB 이상 확보되는 경우(RTX PRO 6000 96 GB 또는 H100/A100 80 GB) BF16 기본 모델을 사용하세요.
--quantization modelopt 플래그는 실제로 어떤 역할을 하나요?
vLLM이 가중치 로딩을 NVIDIA Model Optimizer의 compressed-tensors 백엔드를 통해 처리하도록 지시하는 플래그입니다. 이 백엔드는 NVFP4 형식을 이해하고 행렬 곱셈을 FP4 텐서 코어로 디스패치합니다. 이 플래그 없이는 vLLM이 양자화 방식을 인식하지 못해 시작 시 오류를 던지거나 가중치를 다른 형식으로 해석하려 할 수 있으며 — 어느 쪽도 제대로 된 출력을 내지 못합니다.
NVFP4는 BF16 대비 정확도가 얼마나 낮아지나요?
NVIDIA 공식 평가 스위트 기준 대부분의 벤치마크에서 0.5–0.8점 차이입니다 . MMLU Pro는 85.6→85.0, GPQA Diamond는 84.9→84.8, AIME 2025는 89.2→88.8로 하락합니다. 명령 수행(IFBench: 62.8 대 62.3)과 멀티모달 추론(MMMU Pro: 74.5 대 74.1)에서는 NVFP4가 BF16을 소폭 앞서는데 — 멀티턴 Nemotron 데이터를 사용한 캘리브레이션 데이터셋 효과로 추정됩니다.
MTP 추론 디코딩에 별도 드래프트 모델이 필요한가요?
아닙니다. Multi-Token Prediction 헤드는 Qwen3.6-35B-A3B 체크포인트 자체에 내장되어 있습니다. --speculative-config '{"method":"mtp","num_speculative_tokens":3,"moe_backend":"triton"}'을 전달해 활성화하면 — vLLM이 별도 체크포인트를 다운로드하거나 로드하지 않고 모델 자체 MTP 헤드를 사용합니다.
DGX Spark에 필요한 vLLM·CUDA 버전은 무엇인가요?
CUDA 13.0과 vllm/vllm-openai:cu130-nightly Docker 이미지가 필요합니다 . 현재 vLLM 안정 릴리스에는 Blackwell sm_120/121a용 FlashInfer CUTLASS MoE 커널이 없습니다. 프로덕션 배포 시에는 특정 nightly 빌드 해시를 고정하세요 — 2026년 6월 기준으로 NVFP4 Blackwell을 완전히 지원하는 안정 vLLM 릴리스는 아직 출시되지 않았습니다.
다음으로 시도해볼 것들
Hopper 카드에서는 이제 실용적인 경로가 열렸습니다. vllm serve 명령 하나에 --quantization modelopt과 --reasoning-parser qwen3만 추가하면 — 262K 컨텍스트, 내장 연쇄 사고 처리, 네이티브 툴 호출을 갖춘 35B 추론 모델을 단일 GPU에서 실행할 수 있습니다. 3.06배 메모리 절감은 4방향 텐서 병렬 처리가 필요한 경계와 단일 카드에 올릴 수 있는 경계 사이의 운영 임계값입니다.
여기서 기본 설정을 더 확장할 수 있습니다. 에이전트 워크로드의 구조적 툴 호출을 위해 --enable-auto-tool-choice --tool-call-parser qwen3를 추가하고, 지연 시간에 민감한 경로에서는 --default-chat-template-kwargs '{"enable_thinking": false}'로 thinking 모드를 비활성화하세요. 또한 실제 문서 길이를 기준으로 262K RAG 경로를 스트레스 테스트해보세요. 레지스트리 요건이 있는 엔터프라이즈 환경을 위한 RedHatAI 미러도 Hugging Face에서 제공됩니다.
DGX Spark에서는 nightly 이미지 의존성이 주요 운영 위험입니다. 커뮤니티 패치 현황은 AEON-7/Qwen3.6-NVFP4-DFlash 리포지토리에서 확인하고, Blackwell sm_120/121a 커널이 안정 빌드에 포함되는 시점을 위해 upstream vLLM 릴리스를 주시하세요. 그 전까지는 nightly 이미지 해시를 고정하세요.
최종 업데이트: 2026-06-01. nvidia/Qwen3.6-35B-A3B-NVFP4 모델 카드(2026-05-28 공개)와 2026년 6월 기준 검토된 커뮤니티 배포 보고서를 바탕으로 합니다.







