
What Qwen3.6-35B-A3B-NVFP4 Is, in Brief
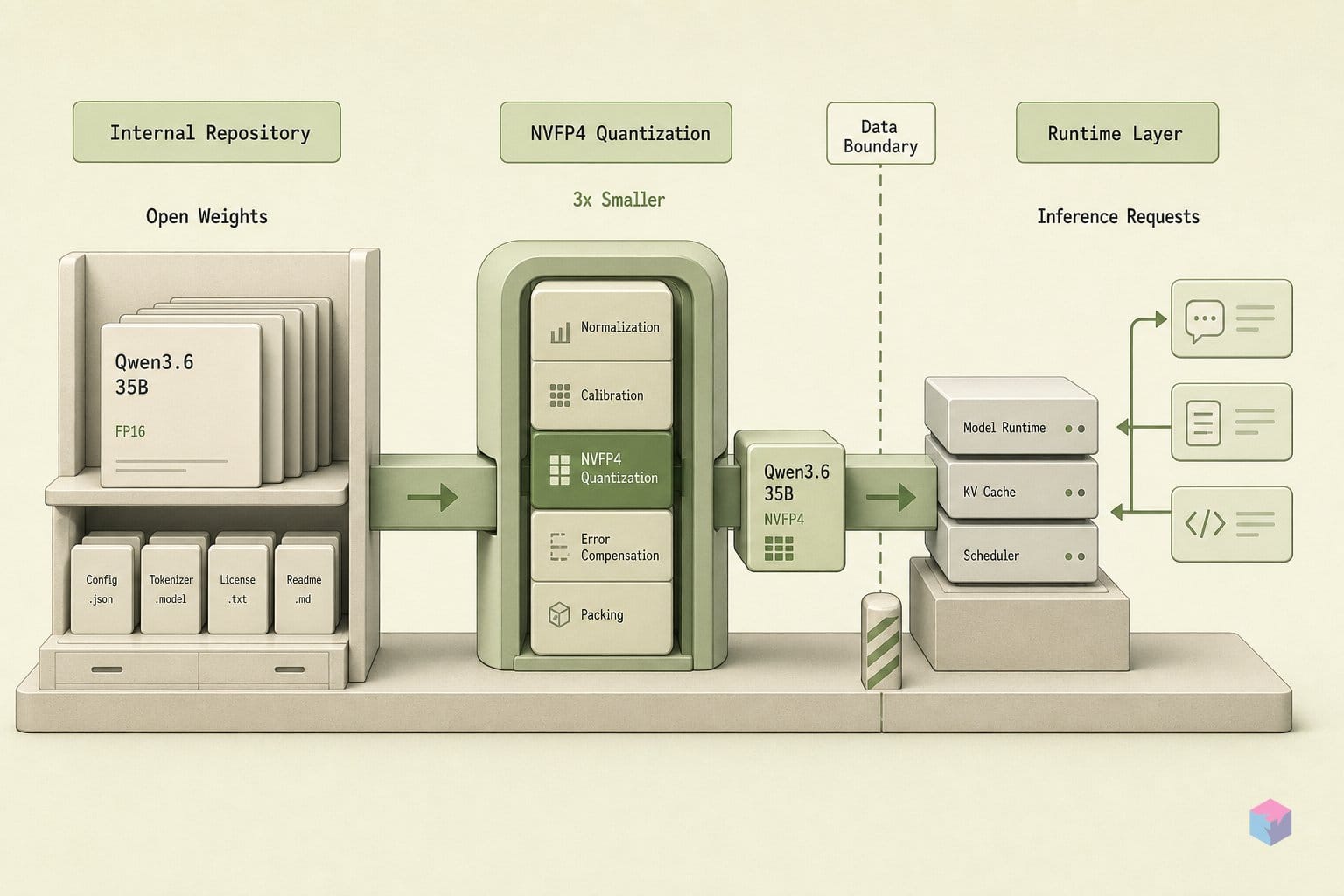
nvidia/Qwen3.6-35B-A3B-NVFP4 is a post-training-quantized variant of Alibaba's Qwen3.6-35B-A3B, published to Hugging Face by NVIDIA on May 28, 2026 . NVIDIA applied its proprietary NVFP4 4-bit floating-point quantization — not Alibaba — so you download it pre-calibrated and deploy without running a local quantization pipeline. The result is a 3.06× smaller checkpoint on disk and in GPU memory versus the BF16 original, with a storage footprint equivalent to a ~19B BF16 model despite retaining 35B total parameters .
Quick Answer: NVIDIA's Qwen3.6-35B-A3B-NVFP4 compresses Alibaba's 35B sparse MoE model to a ~19B-equivalent disk footprint (3.06× smaller than BF16) using NVFP4 4-bit floating-point quantization. Accuracy loss across MMLU Pro, GPQA Diamond, and AIME 2025 is under 1% per NVIDIA's model card. Blackwell GPUs (B200, B300, GB200, GB300) required for native execution; Apache 2.0 licensed.
The base model — Alibaba's Qwen3.6-35B-A3B, released April 16, 2026 under Apache 2.0 — is a sparse Mixture-of-Experts (MoE) architecture. "35B" refers to total parameter count across all experts; only ~3B parameters activate per forward pass, keeping per-token compute closer to a dense 3B model than a 35B one. The architecture includes Hybrid Attention and a native 262K-token context window, with multimodal inputs supporting text, image, and video .
The capability floor this quantization is applied to is genuinely competitive. On SWE-bench Verified, the base model scores 73.4 versus Gemma4-31B's 52.0 — a margin that survives the quantization step. On Terminal-Bench 2.0, the base model scores 51.5 versus Gemma4-31B's 42.9 . NVIDIA's quantization doesn't create capability; it preserves it while cutting deployment cost. The Apache 2.0 license carries through to the NVFP4 checkpoint — commercial use is unrestricted without royalty obligations .
NVFP4 Under the Hood: E2M1 Format and Why It Beats INT4
NVFP4 is a 4-bit floating-point format with the bit layout E2M1: 1 sign bit, 2 exponent bits, 1 mantissa bit. Unlike INT4, which represents values as fixed-point integers and clips distribution tails to fit the range, NVFP4 preserves floating-point dynamic range — a critical property for transformer inference. MoE architectures in particular can produce activation spikes in individual expert layers, and INT4 clips those outliers and accumulates quantization error. NVFP4 handles the non-uniform weight distributions typical of MoE expert routing without special handling .
The format uses a dual-scale design that improves on MXFP4. Each group of 16 values shares a fine-grained E4M3 FP8 scaling factor (the micro-block scalar), and the entire tensor is further scaled by a per-tensor FP32 scalar. Compare this to MXFP4, which uses an E8M0 power-of-two scalar per 32-value block. Coarser granularity means more quantization error on tensors with non-uniform weight distributions — exactly what appears in expert-routing layers. NVFP4's 16-value micro-blocks catch local distribution variance that MXFP4's 32-value blocks miss .
On the memory hierarchy, NVFP4 sits at roughly 3.5× smaller than FP16 and 1.8× smaller than FP8 . For Qwen3.6-35B, that compression is the difference between a multi-GPU setup and a single-GPU deployment on mid-range Blackwell cards. According to the NVIDIA Technical Blog, hardware support is Blackwell-native — B200, B300, GB200, GB300 — with Hopper listed as a supported runtime via software paths only .
INT4 comparison in practice: The clipping distortion INT4 applies to outlier activations is especially damaging for MoE layers. When an expert's activations spike, INT4 saturates at its fixed integer ceiling and the error compounds through subsequent matrix multiplications. NVFP4's floating-point dynamic range adjusts via the micro-block scalar rather than saturating — the per-16-value FP8 scale factor absorbs local distribution shifts. This is why NVFP4 consistently outperforms INT4 at equivalent bit-widths on models with non-uniform activation profiles.
FP8 vs NVFP4 decision guide: FP8 runs natively on both Hopper and Blackwell and carries more representational headroom at 8 bits. NVFP4 halves the bit width again and requires Blackwell for native execution. If memory is the binding constraint on Blackwell hardware, NVFP4 is the right choice. If you're on Hopper with no upgrade path planned, FP8 avoids the software emulation overhead that NVFP4 incurs on that architecture.
How NVIDIA Calibrated the Qwen3.6 Checkpoint
NVIDIA's quantization pipeline for this checkpoint ran through nvidia-modelopt v0.44.0, targeting the weights and activations of linear operators inside the MoE transformer blocks . This is weight-plus-activation co-quantization — a stricter regime than weights-only quantization, which leaves activations in full precision. Co-quantization forces the entire linear operator into the low-precision numeric regime: better runtime consistency (no mixed-precision scatter between weight and activation paths), but harder to calibrate without accuracy loss.
The calibration datasets were CNN DailyMail and NVIDIA's internal Nemotron-Post-Training-Dataset-v2 . The pairing is deliberate:
- CNN DailyMail (news summarization) — covers long-context passage processing, preserving fidelity for tasks requiring compression or recall across extended input windows.
- Nemotron-Post-Training-Dataset-v2 (multi-turn conversation) — covers instruction-following patterns, preserving response quality on chat, structured output, and agentic prompts.
Each dataset targets a known failure mode for aggressive quantization. Summarization tasks stress long-range attention recall — a fragile pattern when activations are clipped. Multi-turn dialogue stresses instruction-following precision and format adherence. Using both means the calibration minimizes error across two different forward-pass regimes rather than optimizing for one at the expense of the other.
"The checkpoint achieves a ~3.06× reduction in disk and GPU memory versus BF16, with effective GPU memory footprint equivalent to a ~19B BF16 model despite retaining 35B total parameters." — NVIDIA Model Card, nvidia/Qwen3.6-35B-A3B-NVFP4
The resulting artifact is labeled NVFP4 1.0. The versioning signals this is the initial production checkpoint — NVIDIA has published updated checkpoints (e.g., NVFP4 1.1 revisions) for other models when post-calibration analysis identified regressions. For Qwen3.6, the accuracy deltas published in the model card (Section 4) don't show any obvious regression, but tracking model card revision history on Hugging Face is prudent before committing to a long-running production deployment.
For developers who want to replicate or extend this quantization for custom calibration data: nvidia-modelopt is available via pip install nvidia-modelopt. The quantization API supports custom calibration datasets through the standard modelopt PTQ (post-training quantization) interface. NVIDIA has not published the exact calibration scripts used for this checkpoint, but the modelopt documentation covers the quantization API.
Accuracy vs. BF16: MMLU, GPQA, and Long-Context Recall
The headline claim is that NVFP4 quantization costs under 1% accuracy across all reported evaluations. The benchmark numbers on the official model card support this: the largest degradation is 0.6 percentage points on MMLU Pro, and the smallest is 0.1 points on GPQA Diamond . IFBench instruction-following actually ticks up 0.5 points — within noise. Critically, long-context recall on AA-LCR at the full 262K-token context shows zero measurable degradation .
| Benchmark | NVFP4 | BF16 | Delta | Notes |
|---|---|---|---|---|
| MMLU Pro | 85.0 | 85.6 | −0.6 | Broad knowledge, 57-category MCQ |
| GPQA Diamond | 84.8 | 84.9 | −0.1 | PhD-level science Q&A |
| AIME 2025 | 88.8 | 89.2 | −0.4 | Competition mathematics |
| IFBench | 62.8 | 62.3 | +0.5 | Within noise; instruction-following format adherence |
| AA-LCR (262K context) | 62.0 | 62.0 | 0.0 | Long-context retrieval; no measurable degradation |
Source: NVIDIA model card, vendor-reported. No independent third-party replication as of May 2026 .
The pattern is consistent with NVIDIA's published NVFP4 results across other model families — DeepSeek-R1, Llama-3.3-70B, and Gemma-4 show similar sub-1% degradation profiles using the same calibration methodology . This is not an outlier result. The dual-scale calibration design — micro-block FP8 plus per-tensor FP32 — appears to be consistently effective at preventing the accuracy collapse that characterized early INT4 quantization attempts on large models.
Verification caveat: All five rows above originate from NVIDIA's own model card. No independent third-party evaluation has reproduced these figures as of May 31, 2026. Treat them as vendor-reported until external replication appears on the Open LLM Leaderboard or equivalent. Practical implication: if MMLU Pro or GPQA accuracy on your specific downstream task is a hard deployment requirement, run your own eval suite before shipping. The direction of these numbers is trustworthy given NVIDIA's track record on this format; the exact magnitudes carry ±1–2% uncertainty until independently confirmed.
The long-context result deserves separate attention. Attention-heavy operations over 262K-token sequences are typically where quantization damage first appears — small accumulated errors in QKV projections compound over long dependency chains. Zero degradation on AA-LCR suggests NVIDIA's CNN DailyMail calibration specifically addressed this failure mode, consistent with the dataset design rationale described in Section 3.
Serving Qwen3.6 NVFP4 with vLLM: Required Flags
The recommended serving stack for this checkpoint is vLLM with two non-optional flags. The standard command for Blackwell hardware is straightforward — but omitting either flag will cause the model to load incorrectly or fail entirely:
vllm serve nvidia/Qwen3.6-35B-A3B-NVFP4 \
--quantization modelopt \
--kv-cache-dtype fp8--quantization modelopt routes the model through NVIDIA's modelopt inference backend rather than vLLM's built-in GPTQ/AWQ paths. --kv-cache-dtype fp8 keeps the KV cache in FP8 rather than BF16, which prevents a memory footprint mismatch between quantized weights and a full-precision cache. Both flags require nvidia-modelopt to be installed in the vLLM Python environment — if it's absent, the serve command fails at model load. The nightly Docker image vllm/vllm-openai:nightly ships with modelopt included .
DGX Spark (GB10, SM121 capability): The standard modelopt path is not the fastest option on GB10. The RedHatAI community checkpoint uses the compressed-tensors quantization backend paired with the flashinfer_cutlass MoE routing kernel, which is better optimized for the SM121 architecture . If you're targeting DGX Spark specifically, use the RedHatAI checkpoint and pass --quantization compressed-tensors with the flashinfer_cutlass router. The throughput figures in Section 6 come from this path.
Multi-Token Prediction (MTP) speculative decoding: The checkpoint bundles an MTP speculative decoding head. MTP is a speculative decoding variant where the primary model proposes draft tokens per step; a lightweight draft head validates them before committing. Enable it in vLLM via the draft head speculative decoding parameter. The acceptance rate for this checkpoint is 85.4% — well above the 65–70% range typical for single-step speculation on instruction-tuned models. At that acceptance rate, you should see meaningful wall-clock throughput improvement on most generation workloads.
Hopper caution: H100/H200 is listed as a supported runtime, but execution is via software emulation — not native FP4 tensor cores. NVIDIA's benchmarks were validated on Blackwell; no Hopper throughput figures appear in the model card. If you must run on Hopper, benchmark actual latency under your workload before assuming NVFP4 outperforms FP8 on that architecture. In most cases, an FP8 checkpoint on Hopper will be faster.
Blackwell deployment checklist:
- Install modelopt:
pip install nvidia-modelopt(or use thevllm/vllm-openai:nightlyDocker image) - Use vLLM ≥ 0.8.x (modelopt inference integration added in the 0.8 series)
- Pass
--quantization modelopt --kv-cache-dtype fp8on everyvllm serveinvocation - For DGX Spark: switch to the RedHatAI community checkpoint with
compressed-tensorsbackend andflashinfer_cutlassMoE routing - Optional: enable MTP draft head speculative decoding for throughput gains at 85.4% acceptance rate
DGX Spark on GB10: Latency, Speculation, and Load Performance
The most complete community performance data for this checkpoint comes from DGX Spark (GB10, SM121 capability), using the RedHatAI community checkpoint with the compressed-tensors backend and flashinfer_cutlass MoE routing. Single-user throughput is approximately 55.9 tokens/second . Under 32 concurrent users, aggregate throughput reaches approximately 433 tokens/second — roughly 13.5 tokens/second per user at that concurrency level .
| Load | Aggregate Throughput | Per-User Rate | Hardware | Backend |
|---|---|---|---|---|
| 1 user | ~55.9 tok/s | 55.9 tok/s | DGX Spark (GB10, SM121) | compressed-tensors + flashinfer_cutlass |
| 32 users | ~433 tok/s | ~13.5 tok/s | DGX Spark (GB10, SM121) | compressed-tensors + flashinfer_cutlass |
| B200 SXM | — (not yet published) | — | B200 SXM | — |
| GB200 NVL72 | — (not yet published) | — | GB200 NVL72 | — |
Source: Steve Scargall, vLLM Recipe: Qwen3.6-35B-A3B-NVFP4 on DGX Spark . B200/GB200 figures not yet public as of May 2026.
The 13.5 tokens/second per-user rate at 32 concurrent users is adequate for interactive chat — typical reading speed is 200–250 wpm (≈4–5 tokens/s), so 13.5 tok/s clears that by a wide margin. It becomes tight if you're streaming long structured outputs (code generation over several hundred lines, long-form reasoning chains) where users with developer tooling expect 20–30 tok/s to feel seamless. For batch processing workloads — document pipelines, offline RAG indexing, evals — the 433 tok/s aggregate figure is the one to plan around.
"MTP speculative decoding with this checkpoint achieves an 85.4% acceptance rate on DGX Spark — significantly above the 65–70% range typical for single-step speculation on instruction-tuned models at this scale." — Steve Scargall, vLLM Recipe: Qwen3.6-35B-A3B-NVFP4 on DGX Spark
An 85.4% MTP acceptance rate is worth contextualizing. In single-step MTP speculation, the model generates one draft token ahead of the autoregressive pass; the verifier accepts or rejects it. At 85.4% acceptance, roughly 6 out of every 7 speculative tokens pass — a hit rate that produces meaningful wall-clock speedup. The MoE architecture likely helps here: with only ~3B parameters activating per forward pass, the draft head can generate high-quality proposals at low compute overhead. The acceptance rate would likely drop with a denser architecture at equivalent total parameter count.
Gap to note for datacenter deployments: B200 SXM and GB200 NVL72 throughput figures for this specific checkpoint are not publicly available as of May 2026. Developers targeting datacenter-scale deployments should expect materially higher throughput on those platforms — B200 has significantly more memory bandwidth and FP4 tensor core throughput than GB10 — but cannot cite specific figures yet. Watch NVIDIA's official deployment recipes and the vLLM release notes for those numbers.
The Broader NVFP4 Catalog: Qwen3.6's Actual Position

Some coverage of this checkpoint described it as the "first NVFP4-quantized open-weight model on HuggingFace." That framing is incorrect. NVIDIA began publishing NVFP4 checkpoints in February 2025, starting with DeepSeek-R1 and expanding to Llama-3.3-70B, Llama-3.1-405B, Gemma-4, and others . The accurate and narrower claim: this is the first NVFP4 checkpoint for the Qwen3.6 model family specifically, and possibly the first NVFP4 open-weight multimodal sparse MoE checkpoint at the 3B-active / 35B-total parameter scale.
The May 2026 NVFP4 batch alongside Qwen3.6 also includes:
- Kimi-K2.6-NVFP4 — Moonshot AI's MoE model
- Qwen3.5-397B-A17B-NVFP4 — the larger Alibaba sparse MoE
- DeepSeek-V4-Pro-NVFP4 — latest DeepSeek architecture
This is a systematic program: NVIDIA is running leading open-weight checkpoints through modelopt on a rolling cadence, targeting Blackwell deployments across all major model families. The practical effect for Blackwell customers is a growing catalog of pre-quantized, validated checkpoints that require no local quantization infrastructure to deploy.
One architectural distinction worth flagging for memory planning: NVFP4 cuts the 35B static weight footprint 3.06×, but active-parameter compute per forward pass remains at ~3B. The latency profile in production resembles a quantized 3B dense model, not a 35B one — token generation is fast because per-token compute is low. What you're paying for relative to a native 3B model is the capability headroom that comes from having 35B expert parameters available to the router, even though only ~3B activate per forward pass. If your workload is purely latency-sensitive and doesn't need the full expert breadth, a native 3B dense model may outperform on raw tokens-per-second. If your workload depends on the broad knowledge and coding capability of a 35B-scale model, Qwen3.6 NVFP4 delivers it at 3B-class serving cost on Blackwell.
Frequently Asked Questions
What GPU is required to run Qwen3.6-35B-A3B-NVFP4 natively?
Native NVFP4 execution requires a Blackwell-architecture GPU: B200, B300, GB200, or GB300. These are the only hardware targets with FP4 tensor core support . Hopper (H100, H200) is listed as a supported runtime in the model card, but execution falls back to a software emulation path with no native FP4 acceleration — actual latency on Hopper may be worse than running a standard FP8 checkpoint on the same hardware. Pre-Hopper GPUs (Ampere and earlier) are not supported by the NVFP4 runtime.
How much accuracy does NVFP4 quantization cost on Qwen3.6-35B?
Per NVIDIA's model card, all benchmark degradations are under 1%: GPQA Diamond drops 0.1 points (84.9 → 84.8), AIME 2025 drops 0.4 points (89.2 → 88.8), and MMLU Pro drops 0.6 points (85.6 → 85.0). Long-context recall on AA-LCR at the full 262K-token context shows no measurable change (62.0 for both variants) . These are vendor-reported numbers — independent third-party replication had not appeared as of May 2026. For production SLA decisions, run your own task-specific evals rather than relying solely on these reported figures.
What is the difference between NVFP4, FP8, and INT4 quantization?
NVFP4 is a 4-bit floating-point format (E2M1: 1 sign, 2 exponent, 1 mantissa bit) that preserves floating-point dynamic range. INT4 uses fixed-point 4-bit integers and clips distribution tails, which causes accuracy degradation on models with activation outliers — a common problem in MoE expert layers. FP8 is an 8-bit floating-point format with more representational headroom than NVFP4 and considerably less compression. In memory terms, NVFP4 is approximately 3.5× smaller than FP16 and 1.8× smaller than FP8 . NVFP4's dual-scale design — per-16-value FP8 micro-block scalar plus per-tensor FP32 scalar — reduces quantization error compared to MXFP4's coarser per-32-value power-of-two scaling. Blackwell hardware is required for native NVFP4 execution; FP8 runs natively on both Hopper and Blackwell.
What vLLM flags do I need to serve this checkpoint?
For standard Blackwell hardware (B200, GB200, GB300): pass --quantization modelopt and --kv-cache-dtype fp8 to vllm serve. Ensure nvidia-modelopt is installed in the vLLM Python environment — the vllm/vllm-openai:nightly Docker image includes it. For DGX Spark (GB10, SM121 capability), use the RedHatAI community checkpoint variant with --quantization compressed-tensors and the flashinfer_cutlass MoE routing kernel for best per-token latency . The MTP speculative decoding head is bundled in the checkpoint; enable it via vLLM's draft head parameter to activate the 85.4% acceptance rate throughput gains.
Is this the first NVFP4 open-weight model on HuggingFace?
No. NVIDIA published NVFP4 checkpoints for DeepSeek-R1, Llama-3.3-70B, Llama-3.1-405B, Gemma-4, and other models beginning in February 2025 . The accurate distinction for this specific checkpoint: it is the first NVFP4 quantization of the Qwen3.6 model family, and possibly the first NVFP4 multimodal sparse MoE at this parameter scale (3B active / 35B total). NVIDIA's NVFP4 catalog as of May 2026 also includes Kimi-K2.6-NVFP4, Qwen3.5-397B-A17B-NVFP4, and DeepSeek-V4-Pro-NVFP4 .
What This Means for Blackwell Deployments
The practical takeaway is narrow and concrete. If you are deploying on Blackwell hardware and evaluating Qwen3.6-35B as a base model, the NVFP4 checkpoint eliminates your quantization pipeline entirely. You download a pre-calibrated, validated checkpoint, add two vLLM flags, and deploy. The 3.06× memory reduction is confirmed by the model card and consistent with NVIDIA's broader NVFP4 program. The sub-1% accuracy degradation is vendor-reported and methodologically plausible, but independent verification is still outstanding — factor that into your evaluation strategy for regulated or high-stakes production environments.
For the MoE plus NVFP4 combination specifically, the latency model is unusual relative to dense models at similar memory footprint. You are serving a model with the capability profile of a 35B-parameter system at the per-token compute cost of roughly 3B active parameters. On DGX Spark, that translates to ~55.9 tok/s single-user, sufficient for most interactive use cases. The bundled MTP speculative decoding head at 85.4% acceptance rate adds an efficiency layer that most FP8 checkpoints at this scale do not include out of the box. Together, these properties make the checkpoint particularly well-suited for agentic coding tasks, long-context RAG pipelines, and structured-output generation where model capability and per-token latency are both binding constraints.
Two gaps to track as the Blackwell ecosystem matures: B200 SXM and GB200 NVL72 throughput figures for this checkpoint are not yet publicly available as of May 2026, and no independent accuracy benchmarks have appeared on Open LLM Leaderboard or equivalent. Both will close as the deployment base grows. When independent evals emerge, they will either confirm NVIDIA's calibration claims or surface the edge cases the CNN DailyMail plus Nemotron dataset pair did not cover — either outcome is useful signal for production planning.
Last updated: 2026-05-31. Based on the NVIDIA model card published May 28, 2026 , NVIDIA Technical Blog documentation, and community benchmark data from DGX Spark hardware. Independent accuracy validation not yet available at time of writing.




