
What Does Headroom Do Before Your Message Reaches the LLM?
Headroom is a context compression middleware that intercepts outbound messages — tool outputs, RAG chunks, logs, code search results, and database rows — before the LLM provider's token counter sees them. The library compresses those payloads first, so the model receives a smaller, semantically equivalent payload rather than the raw original. The published core claim is 60–95% token reduction with accuracy preservation, validated on GSM8K (baseline held at 0.870) and TruthfulQA (+0.030 over uncompressed baseline) .
Quick Answer: Headroom is open-source context compression middleware (Apache 2.0, Python 3.10–3.13) that sits between your agent runtime and any LLM provider, compressing tool outputs, RAG chunks, logs, and code search results before tokens are counted. Published benchmarks show 60–95% token reduction with GSM8K held at 0.870 ; latency overhead is 5–50ms per call.
The library is distributed as headroom-ai on PyPI and npm under Apache 2.0. As of May 21, 2026, the latest release is v0.22.3 — the 151st release across 1,376 commits — with approximately 3,000 GitHub stars and 260 forks on chopratejas/headroom . The project targets Python 3.10–3.13 and is listed as Beta (Development Status 4) on PyPI .
The architecture is provider-agnostic by design. The model parameter in compress(messages, model='claude-sonnet') tunes the compression strategy — models with smaller context windows receive more aggressive compression — but does not restrict which provider endpoint receives the compressed payload. Proxy mode speaks the OpenAI-compatible API contract, so any conforming endpoint accepts its output without modification.
The key trade-off to evaluate before integrating Headroom into a latency-sensitive pipeline is the 5–50ms overhead per compression call . For most async agent pipelines, this is negligible compared to the LLM provider round-trip. For sub-100ms interactive paths, benchmark it on your actual hardware before committing.
SmartCrusher, CodeCompressor, Kompress-base, CacheAligner: Which Runs When
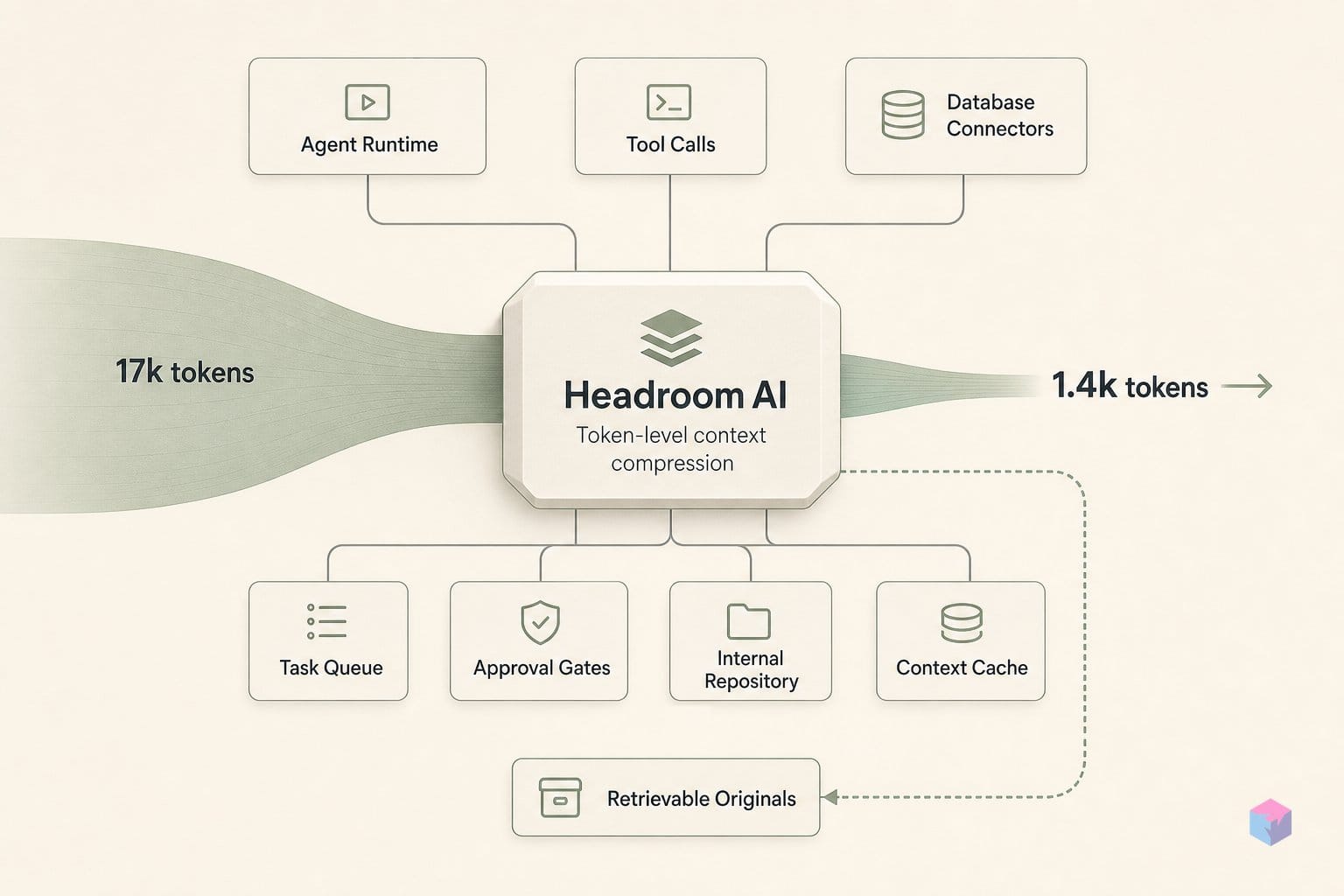
Headroom routes each incoming payload through one of four specialized engines based on automatic content-type detection — you do not configure which engine runs. SmartCrusher handles JSON arrays and nested objects; CodeCompressor handles source code via AST parsing; Kompress-base handles prose and log data via a locally-running ML model; CacheAligner handles message prefix stabilization for provider cache optimization. Each engine targets a different data shape and none is a general-purpose compressor.
SmartCrusher analyzes field variance across JSON array elements, strips null and empty fields, removes redundant keys that repeat identical values across objects, and collapses repetitive structures. On standard REST API payloads — tool call outputs, API responses with many similar objects — this produces approximately 65% token reduction on average . The compressor is lossless on the fields it retains: it drops structurally redundant data, not semantically unique values.
CodeCompressor parses ASTs for Python, JavaScript, Go, Rust, Java, and C++. Rather than treating source code as text and running a string-based comparison, it identifies structural boilerplate — import blocks, standard function signatures, repeated type declarations — and separates that from unique logic. This achieves the highest compression ratios on multi-file code search results, where the same import patterns and module structure repeat across dozens of files. The 100-file code search benchmark (17,765 → 1,408 tokens, 92%) is the headline number for this engine .
Kompress-base is a HuggingFace model trained specifically on agentic traces — the kind of conversational and log data generated during multi-step tool use. It applies LLMLingua-2-derived cross-encoder sentence ranking: a local model scores each sentence in the payload against the user query, and low-relevance sentences are dropped while those matching intent are preserved. The model runs locally — no external API call — which means first-run download latency and a resident memory footprint to account for in memory-constrained environments.
CacheAligner is addressed in detail below. Briefly: it normalizes dynamic metadata in message prefixes — timestamps, session IDs, rotating headers — to produce stable strings that maximize provider-side KV cache hits. This job is orthogonal to compression ratio. Even a workload that compresses poorly still benefits from prefix stabilization if the prefix was previously volatile.
| Engine | Target content | Technique | Typical reduction | Runtime |
|---|---|---|---|---|
| SmartCrusher | JSON arrays, nested objects | Field variance analysis, null stripping, key deduplication | ~65% on REST payloads | Pure Python |
| CodeCompressor | Source code (Python, JS, Go, Rust, Java, C++) | AST parsing, boilerplate vs. logic separation | Up to 92% on multi-file search | Python + tree-sitter |
| Kompress-base | Prose, logs, conversation history | LLMLingua-2-derived cross-encoder sentence ranking | 47–73% depending on entropy | HuggingFace (local) |
| CacheAligner | Message prefix metadata | Volatile element normalization for KV cache stability | Up to 90% read cost reduction (on cache hit) | Pure Python |
CCR: Compress, Store, and Retrieve on Demand
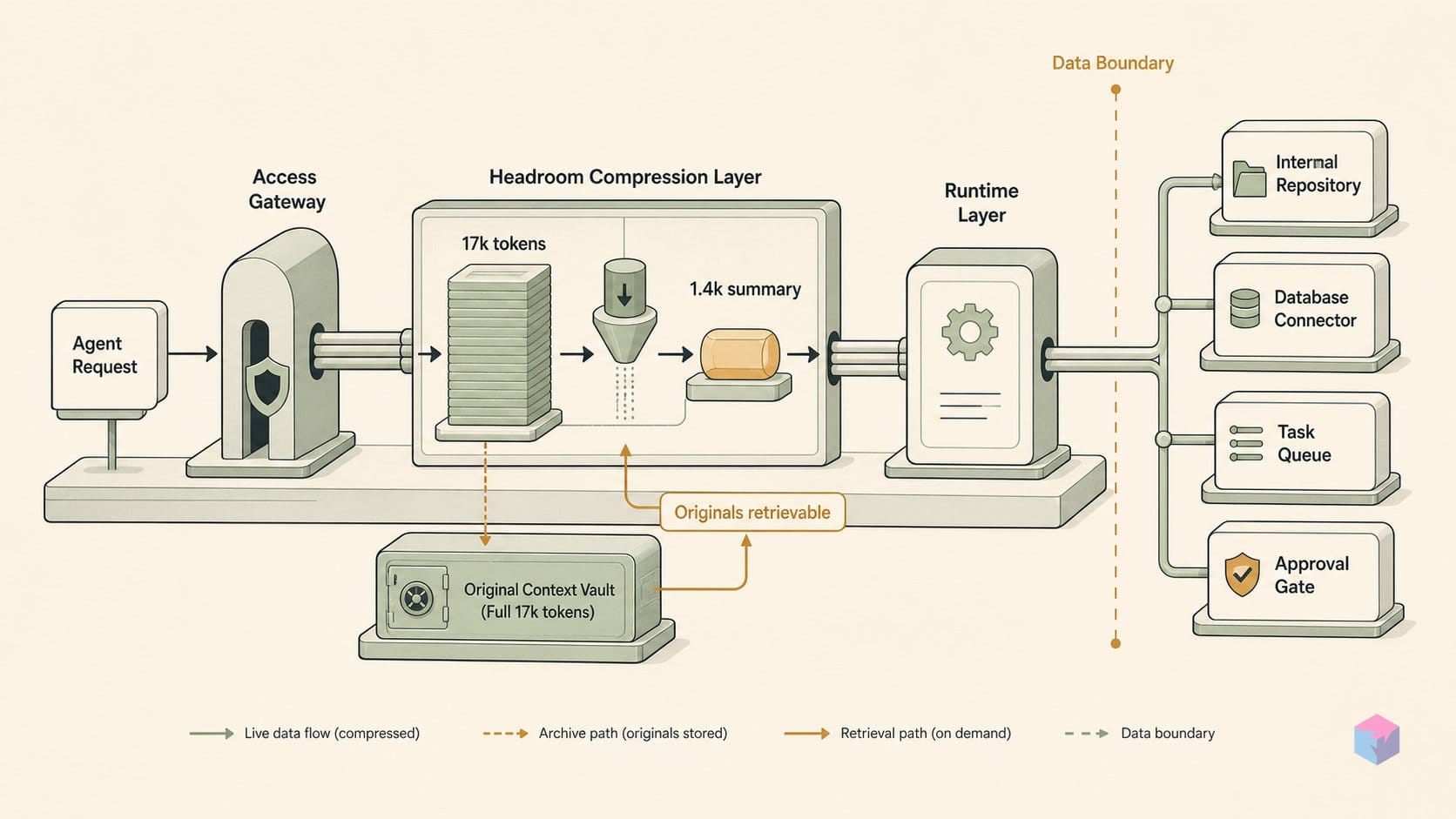
CCR (Compress-Cache-Retrieve) is Headroom's answer to the primary failure mode of aggressive context compression: the agent permanently discards information before it knows whether it needs it. Instead of truncating and moving on, CCR stores the full original payload locally with a hash identifier, sends the LLM a statistical summary, and exposes a headroom_retrieve MCP tool the model can invoke to pull the full data if the summary is insufficient. The LLM decides whether to retrieve; no information is unrecoverably lost.
A concrete example: a 100-row database result set gets collapsed to a summary like "487 passed, 2 failed, 1 error" in the compressed payload. If the downstream reasoning only needs the pass/fail ratio, the agent proceeds without retrieving the rows. If it needs to inspect which specific tests failed, it calls headroom_retrieve with the hash and gets the original 100 rows. This prevents the scenario where a 73% compression ratio turns a debugging task into a dead end because the relevant rows were summarized away.
"The CCR approach flips the usual assumption about compression: instead of asking 'what can we safely throw away?', it asks 'what does the model need right now?' — and defers the rest until requested." — Headroom project documentation
The MCP server (installed via headroom mcp install) surfaces three tools to any MCP-capable host: headroom_compress, headroom_retrieve, and headroom_stats. These integrate natively with Claude Desktop and agent frameworks that support MCP tool discovery, without additional plumbing . The LLM can call headroom_retrieve directly through the MCP tool interface once it determines the summary is insufficient for the task at hand.
The practical implication for pipeline design is that CCR lets you compress more aggressively than you otherwise would. When the original is one tool call away, you can accept a higher initial compression ratio without accepting irreversible information loss. This changes the calculus particularly for long-horizon tasks where context fills up and aggressive truncation would otherwise be the only option.
CacheAligner: Preventing Prompt Variation From Killing Provider Cache Reuse
CacheAligner addresses a different problem than compression ratio: it stops your framework from silently invalidating provider KV cache on every request. Many LLM frameworks inject dynamic metadata — timestamps, session IDs, tool call IDs, rotating headers — into message prefixes. If those values change between calls, the provider treats each request as a cache miss even when the substantive system prompt content is identical. CacheAligner normalizes those volatile elements to produce stable prefix strings, turning repeated full-bill requests into near-free cache reads after the first call.
The specific target is Claude's prompt prefix caching, which offers a 90% cost discount on cached prefix tokens . If your system prompt is 100,000 tokens and your framework injects a timestamp that changes every turn, you pay full price on every call. With CacheAligner normalizing that prefix, you pay full price once and the discount applies on all subsequent turns with identical substantive content.
"A missed cache hit on a 100k-token shared system prompt means full billing every turn. CacheAligner turns this into a near-free read after the first call." — Headroom Labs documentation
The savings from CacheAligner are orthogonal to compression ratio. Even a workload that is not highly compressible — dense technical prose, conversation history, varied tool outputs — can achieve substantial cost reduction from prefix stabilization alone, if the prefix was previously volatile. The two mechanisms stack: a compressed, cache-aligned prompt is both smaller and more likely to hit the provider's cache on the second and subsequent calls in a session.
For teams using LangChain, Agno, or other frameworks that decorate system prompts with session metadata, CacheAligner is worth evaluating independently of the rest of Headroom's compression stack. The memory footprint is negligible, the overhead is pure Python string normalization, and a single framework-injected UUID in the prefix is enough to break cache consistency across an entire session.
The 92% Compression Ratio: What the Published Workload Data Shows
The headline benchmark — code search (100 results): 17,765 → 1,408 tokens, 92% reduction — reflects the workload most favorable to CodeCompressor . A 100-file code search result contains massive repetition in import blocks, module declarations, and type scaffolding; AST-based boilerplate detection is purpose-built for this shape. Replicate this benchmark on your own codebase before treating 92% as a general expectation — it holds specifically for large multi-file code search payloads, not all structured data.
The SRE incident log debugging benchmark (65,694 → 5,118 tokens, 92%) also hits 92%, but through a different path: log data is highly repetitive in structure — timestamps, severity levels, repeated service names — with sparse unique content per line. Kompress-base's sentence ranking discards structurally similar lines and retains anomalous ones, which is precisely what an SRE debugging session needs .
GitHub issue triage (54,174 → 14,761 tokens, 73%) and RAG over a customer support corpus (73% reduction, maintained F1 on answer quality) represent more heterogeneous content where ratios are lower but still material . Issue text and support tickets contain diverse natural language and specific technical details that compress less uniformly than structured data.
Multi-hour autonomous agent sessions achieve 47% savings on running context — the lowest figure in the published benchmark suite, because conversation history is the least compressible payload type . Treat 47% as the realistic floor for general-purpose agent use. The 60–95% range requires workloads with structural repetition — code search, logs, uniform API responses — to reach the upper end.
| Workload | Input tokens | Compressed tokens | Reduction | Primary engine |
|---|---|---|---|---|
| Code search (100 results) | 17,765 | 1,408 | 92% | CodeCompressor |
| SRE incident log debugging | 65,694 | 5,118 | 92% | Kompress-base |
| GitHub issue triage | 54,174 | 14,761 | 73% | Kompress-base |
| RAG (customer support corpus) | — | — | 73% | SmartCrusher / Kompress-base |
| Multi-hour agent sessions | — | — | 47% | Mixed (history-dominant) |
Verification note. The GSM8K (0.870) and TruthfulQA (+0.030) accuracy figures are independently checkable against published leaderboards . The code search and SRE numbers come from the project's own published benchmarks; no third-party reproducibility study has been published as of June 2026. Run Headroom against your own representative workload — not the project's selected benchmarks — before projecting cost savings into production planning.
Wiring Headroom Into Your Pipeline: Library, Proxy, and Wrapper Options
Headroom offers four integration modes, each trading control for convenience differently. The library mode gives maximum visibility into per-call compression decisions; the agent wrapper gives the least. Most teams benefit from starting with proxy mode to establish a baseline on a real workload, then migrating to library mode for production pipelines where observability into what was compressed matters.
Library mode — pip install 'headroom-ai[all]' or npm install headroom-ai — gives you direct access to compress(messages, model='claude-sonnet'). The return value includes the compressed messages array and a metrics object detailing which engine ran, original and compressed token counts, and any pass-through flags for payloads that resisted compression. This is the right choice when you want to inspect compression decisions before sending. Granular install extras include [proxy], [mcp], [ml], [agno], [langchain], [evals], and [bedrock].
Proxy mode — headroom proxy --port 8787 — launches an OpenAI-compatible reverse proxy. Any language or framework that speaks the OpenAI API contract routes through it with zero code changes. Requests arrive, get compressed, and forward to your configured backend endpoint. This is the fastest path to measuring compression impact on a real workload without modifying application code.
MCP Server — headroom mcp install — registers Headroom as a tool set in any MCP-capable host, exposing headroom_compress, headroom_retrieve, and headroom_stats. These are discoverable by Claude Desktop and agent frameworks with MCP support without additional plumbing. This mode pairs naturally with the CCR system: the LLM calls headroom_retrieve via the MCP tool interface directly .
Agent wrapper — headroom wrap claude|codex|cursor|aider|copilot — wraps CLI-level invocations of existing coding assistants at the shell level. No pipeline changes required. The trade-off is minimal observability: you see aggregate token reduction but have no access to per-call compression metrics or the CCR store.
For LangChain users, integration is a single line: model = HeadroomChatModel(ChatOpenAI(model='gpt-4o-mini')). Other supported orchestration frameworks include LiteLLM, Agno, Vercel AI SDK, AWS Strands, and CrewAI .
Latency Overhead and When Compression Can Backfire

The 5–50ms per compression call is acceptable for most async agent pipelines — it is typically dwarfed by the LLM provider round-trip — but the range is wide enough to matter for specific workloads . The 5ms lower bound reflects a CPU-bound pure-Python compressor (SmartCrusher or CodeCompressor) on capable hardware. The 50ms upper bound includes Kompress-base's ML inference pass. Before deploying Headroom in a sub-100ms interactive path, benchmark it on your actual infrastructure — not a development machine.
Kompress-base's local ML model carries two resource costs invisible in throughput benchmarks: first-run download time and resident memory footprint. In serverless environments or small containers, a model that runs comfortably on a developer workstation may exceed the memory ceiling. Profile Kompress-base's footprint on representative infrastructure before assuming it fits. If memory is constrained, install without the [ml] extra and rely on SmartCrusher and CodeCompressor alone — you lose prose compression but keep the pure-Python engines.
"Highly entropic content — cryptographic output, dense float arrays, random UUIDs as primary payload — compresses poorly. Headroom passes it through but still spends the 5–50ms attempting compression." — BrightCoding, May 2026
The pass-through behavior is designed to fail gracefully: Headroom returns a metrics object with a flag indicating minimal compression rather than silently truncating or erroring. No data is lost. However, the latency cost is still paid — you spend 5–50ms confirming that the payload could not be reduced. If your workload is primarily cryptographic hashes or dense numerical arrays, Headroom adds overhead with no compression benefit. This is the one scenario where the cost-benefit math reliably inverts.
The CCR local storage layer introduces a second operational concern for long-running agents: it grows with session length. A persistent autonomous agent accumulates original payloads in the local store with no default TTL. Without an explicit cleanup strategy — a TTL policy, a session-scoped store, or periodic pruning — the original-payload store can itself become a disk cost concern, partly undermining the purpose of aggressive token reduction. This is a known Beta-stage limitation, not a fundamental design flaw, but it requires an explicit policy before deploying CCR-enabled Headroom in production long-running agents.
Frequently Asked Questions
Does Headroom work with any LLM provider, or is it tied to OpenAI and Anthropic?
Headroom is provider-agnostic by design. The model parameter in compress(messages, model='claude-sonnet') informs compression strategy — tuning aggressiveness to the target model's context window — but does not restrict which provider receives the compressed output. Proxy mode speaks the OpenAI-compatible API contract, so any conforming endpoint accepts its output without modification. This includes self-hosted models, Azure OpenAI, Bedrock (via the [bedrock] install extra), and any other OpenAI-API-compatible service.
Can compression cause the LLM to produce wrong answers?
The CCR system directly addresses irreversible information loss: original payloads are stored locally and retrievable on demand via headroom_retrieve, so the LLM can always pull the full data if a summary proves insufficient. Published accuracy benchmarks show GSM8K held at 0.870 and TruthfulQA improved by +0.030 over an uncompressed baseline . The important caveat: these benchmarks use project-selected workloads (structured Q&A tasks). How accuracy degrades on multi-step tool-chaining or long-horizon planning under aggressive compression is not independently verified as of June 2026. Test on your domain before relying on the headline figures.
What happens when Headroom encounters content that cannot be compressed further?
Headroom falls back gracefully. Highly entropic payloads — cryptographic hashes, dense numerical arrays, random UUIDs as primary content — pass through unchanged, and the returned metrics object includes a flag indicating minimal or zero compression was achieved. No silent truncation occurs. The latency overhead (5–50ms) is still spent during the compression attempt, so if your workload is predominantly entropic content, evaluate whether that overhead is justified before integrating Headroom into that specific path.
Is the Kompress-base ML model downloaded locally or called via an external API?
Kompress-base runs locally via HuggingFace — there is no external API call during inference. This means fully offline operation is possible, which matters for air-gapped environments or pipelines where external model calls are restricted by policy. The trade-offs are: first-run download latency while model weights are fetched, a persistent memory footprint for as long as the model is loaded, and a hard dependency on the local environment's available memory. Cloud-based reranker alternatives eliminate local overhead but introduce external latency and availability dependency. Install Kompress-base with pip install 'headroom-ai[ml]'.
How does Headroom interact with Claude's native prompt caching?
CacheAligner is specifically designed to preserve Claude's prefix-based cache hits. Claude's prompt caching offers a 90% read cost discount on cached prefix tokens, but this discount breaks whenever framework-injected dynamic metadata — timestamps, session IDs, tool call IDs — changes between turns, causing every request to be treated as a full cache miss. CacheAligner normalizes those volatile elements to produce stable prefix strings, restoring consistent cache hits across turns. Even on workloads where raw compression ratios are low, prefix stabilization alone can produce substantial cost reduction on long-context system prompts that would otherwise be billed in full on every turn.
Evaluation Summary: Three Questions Before You Integrate
Headroom's value proposition is strongest for pipelines with structured, repetitive context: multi-file code search, SRE log analysis, large API response payloads, and RAG over uniform document corpora. These workloads hit the 73–92% reduction range. For general conversational agents or pipelines dominated by conversation history, 47% is the more realistic expectation based on the published benchmark suite.
Three questions determine whether Headroom belongs in your pipeline. First: what is the dominant content type in your LLM context? Structured data with repetition (code search, API responses, log files) favors Headroom strongly; highly variable natural language compresses less reliably, and you should verify on your domain. Second: is your pipeline async (5–50ms overhead is negligible) or sub-100ms interactive (benchmark on actual hardware first, and consider whether the [ml] extra fits your memory budget)? Third: does your framework inject dynamic prefix metadata, and are you on a provider with KV cache discounts? If yes to both, CacheAligner alone may justify the integration independent of compression ratios.
The Beta label is worth taking seriously. As of June 2026, no third-party reproducibility study has validated the published benchmarks, the CCR store lacks a default TTL for long-running agents, and Kompress-base's resource footprint in constrained production environments has limited public documentation. The Apache 2.0 license and open codebase mean you can validate the numbers yourself — and doing so on a representative workload is strongly recommended before any production commitment.
Last updated: 2026-06-01. Article reflects Headroom v0.22.3 (released May 21, 2026) and published benchmarks available as of June 2026. Benchmark figures are sourced from project-published materials; independent third-party reproducibility studies were not available at time of writing.







