
'Gemini Omni 3.5' 뒤에 숨은 실제 제품은?
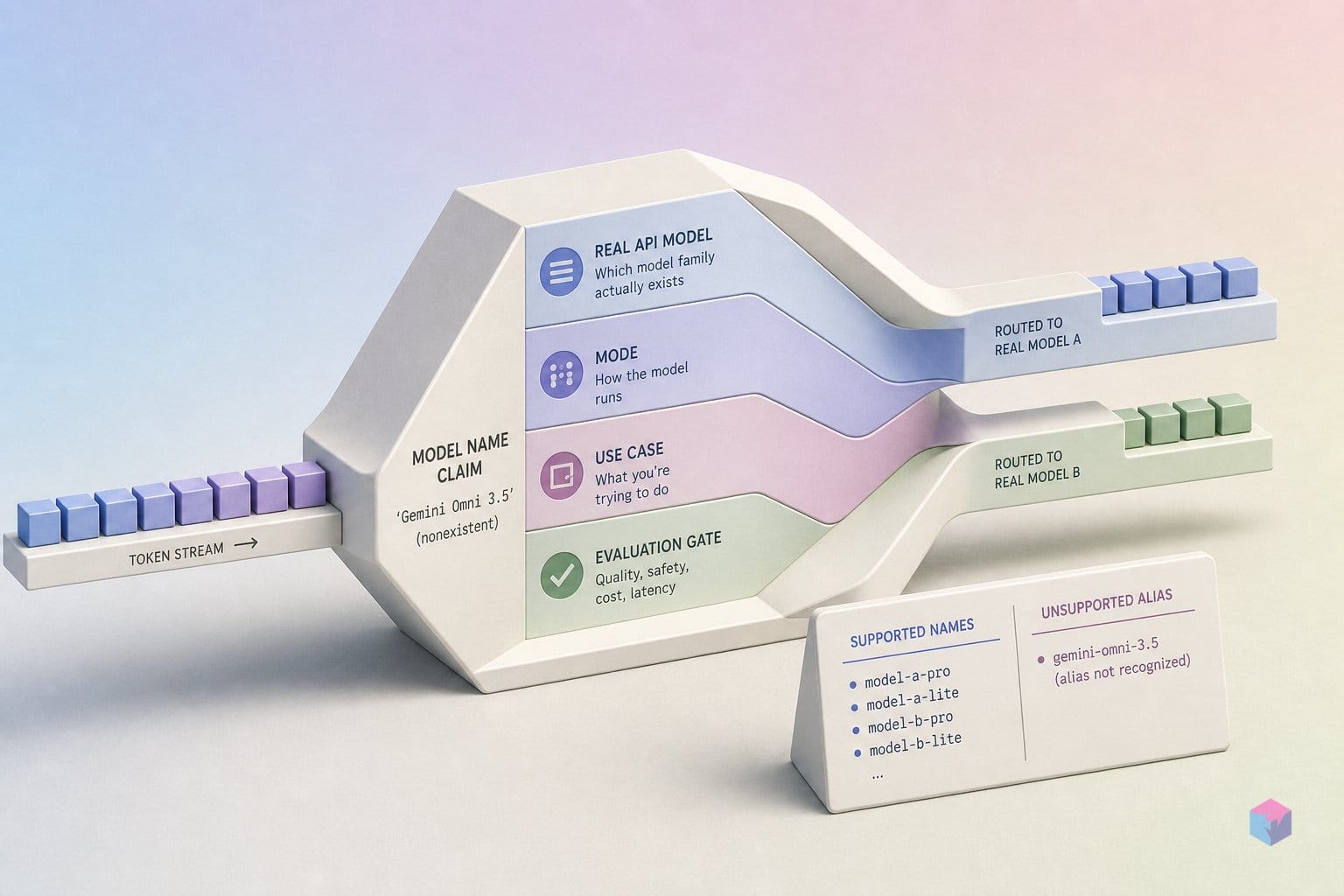
"Gemini Omni 3.5"는 실제 제품명이 아닙니다. 이 축약어는 Google이 2026년 5월 19일 Google I/O 2026에서 출시한 두 가지 별개 모델을 혼용한 것입니다 : Gemini 3.5 Flash(에이전틱 코딩에 최적화된 빠른 텍스트·멀티모달 모델)와 Gemini Omni Flash(모델 ID: gemini-omni-flash , 대화형 편집을 지원하는 영상 생성 전용 월드 모델)입니다. 두 모델은 엔드포인트도, 출력 유형도, 요금제 등급도 완전히 다릅니다. 잘못된 모델 ID를 사용하면 코드 한 줄 작성 전에 404 오류가 발생합니다.
핵심 정리: "Gemini Omni 3.5"는 존재하지 않습니다. Google I/O 2026(5월 19일)에서 출시된 모델은 두 가지입니다: 무료 요금제에서 빠른 텍스트 처리 및 에이전틱 코딩에 쓰이는 Gemini 3.5 Flash(gemini-3.5-flash)와, 유료 구독에서 영상 생성에 쓰이는 Gemini Omni Flash(gemini-omni-flash). 무료 요금제 API 키로 영상 호출을 시도하면 403이 반환됩니다.
아래 검증된 코드 스니펫(exit 0)은 실제 모델 네임스페이스를 탐색하며, gemini-omni-3.5가 호출 가능한 식별자로 존재하지 않음을 확인합니다:
models = {
"gemini-3-pro-preview": "Gemini: multimodal input -> text output",
"imagen-3.0-generate-002": "Imagen: image generation",
"veo-3.0-generate-preview": "Veo: video generation",
"gemini-2.5-flash-preview-native-audio-dialog": "Gemini Live/audio: realtime voice",
}
fake = "gemini-omni-3.5"
print(f"{fake!r} exists? {fake in models}")
print("Real split:")
for model, role in models.items():
print(f"- {model}: {role}")'gemini-omni-3.5' exists? False
Real split:
- gemini-3-pro-preview: Gemini: multimodal input -> text output
- imagen-3.0-generate-002: Imagen: image generation
- veo-3.0-generate-preview: Veo: video generation
- gemini-2.5-flash-preview-native-audio-dialog: Gemini Live/audio: realtime voice영상 렌더링은 범용 텍스트/추론 티어와 분리된 독립 모델 패밀리(Gemini Omni 또는 Veo)에 속합니다. 아래 표에서 두 모델의 차이를 한눈에 확인할 수 있습니다.
| 속성 | Gemini 3.5 Flash | Gemini Omni Flash |
|---|---|---|
| 모델 ID | gemini-3.5-flash |
gemini-omni-flash |
| 주요 출력 | 텍스트, 코드, 멀티모달 | 영상 (MP4 URI) |
| 주요 사용 사례 | 에이전틱 코딩, 장기 툴 사용 | 영상 생성, 대화형 편집 |
| 요금제 요건 | 무료 요금제 (AI Studio) | Google AI Plus, Pro 또는 Ultra |
"Gemini Omni는 월드 모델입니다 — 어떤 입력 유형에서도 모든 출력을 생성합니다." — Koray Kavukcuoglu, VP Research & Technology, Google DeepMind, Google I/O 2026
환경 설정: 설치 및 인증
두 모델 모두 동일한 SDK를 통해 제공됩니다. 한 번만 설치하면 같은 클라이언트 객체로 두 엔드포인트 모두에 접근할 수 있습니다. API 키는 Google AI Studio에서 발급받으세요.
# Python
pip install google-genai
# Node.js
npm install @google/genaiexport GOOGLE_GENAI_API_KEY="your-key-here"영상 엔드포인트를 다루기 전에 스모크 테스트를 먼저 진행하세요. gemini-3.5-flash에 대한 가벼운 텍스트 호출로 무료 요금제의 인증을 검증할 수 있습니다. 여기서 403이 나오면 키 자체가 잘못된 것입니다 — 구독 문제가 아닙니다. 영상 엔드포인트에는 추가적인 두 번째 관문이 있으므로 이 구분이 중요합니다 :
from google import genai
import os
client = genai.Client(api_key=os.environ["GOOGLE_GENAI_API_KEY"])
resp = client.models.generate_content(model="gemini-3.5-flash", contents="Hello")
print(resp.text) # any response = key is live이 테스트를 통과하면 자격 증명이 올바르게 설정된 것입니다. 영상 엔드포인트의 요금제 확인은 §4에서 다룹니다.
대화형 비디오 생성 및 개선
아래 네 단계를 순서대로 진행하세요. 각 단계는 다음 단계의 전제 조건을 검증합니다. 모든 호출은 gemini-omni-flash 를 사용하며 Google AI 유료 구독이 필요합니다 .
- 2단계 — 멀티모달 입력. JPEG를 전달해 시작 프레임을 고정하거나, MP3를 전달해 내레이션과 동기화된 비디오를 생성할 수 있습니다. 두 가지를 텍스트 프롬프트와 함께 단일 호출로 조합하는 것도 가능합니다. 이미지는 참조 프레임을 설정하고, 오디오는 렌더링 시작 전에 음성 트랙에 맞춰 비주얼 타이밍을 고정합니다.
- 4단계 — 모션 트랜스퍼. 대상 장면에 대한 텍스트 설명과 함께 MP4 참조 클립을 제공합니다. Gemini Omni는 참조 영상에서 모션 패턴과 미적 스타일을 추출해 새로운 생성에 적용합니다. 멀티 클립 프로젝트 전반에 걸쳐 일관된 카메라 페이싱을 유지하는 데 유용합니다.
3단계 — 대화형 개선. 채팅 세션을 초기화합니다. 동일 세션 내의 이후 generate_video() 호출은 점진적 편집으로 처리되며, 모델이 처음부터 다시 생성을 시작하지 않습니다 :
session = client.chats.create(model="gemini-omni-flash")
v1 = session.generate_video(contents=[{"text": "A golden retriever on a beach"}])
# poll v1 for COMPLETED...
v2 = session.generate_video(contents=[{"text": "Now make it snowing"}])
# model edits v1 in context — does not re-render from blank slate"swap the dog for a cat"이나 "shift to golden-hour lighting" 같은 후속 요청으로 체인을 이어갈 수 있습니다. 세션 컨텍스트는 객체를 닫거나 타임아웃될 때까지 유지됩니다.
1단계 — 기본 텍스트-투-비디오. 응답은 인라인 바이트가 아닌 MP4 URI를 반환합니다. 파일을 가져오기 전에 COMPLETED 상태가 될 때까지 폴링해야 합니다:
import os, time
from google import genai
client = genai.Client(api_key=os.environ["GOOGLE_GENAI_API_KEY"])
response = client.models.generate_video(
model="gemini-omni-flash",
contents="A slow-motion close-up of coffee being poured over ice"
)
while response.status != "COMPLETED":
time.sleep(10)
response = client.models.get_video_operation(response.operation_id)
print(response.video_uri) # download the MP4 from this URI예시 코드이며, 구조는 ourCodeWorld에 문서화된 google-genai SDK 규칙을 따릅니다. 프로덕션 환경에서는 절대 동기적으로 블로킹하지 마세요 — 폴링 루프는 비동기 워커로 감싸야 합니다.
SynthID + C2PA는 항상 활성화됩니다. 인지하기 어려운 디지털 워터마크와 C2PA 콘텐츠 자격증명이 모든 출력물에 자동으로 삽입됩니다 . 이를 비활성화하는 API 플래그는 없습니다. 배포 전에 플랫폼의 AI 공개 요건을 반드시 확인하세요.
주의할 점: 생성 시간, 할당량, 플랜 제한
- 출시 초기에는 생성 속도가 느립니다. 클립당 60~180초를 예상하세요 . 절대 동기적으로 블로킹하지 마세요 — 상태 엔드포인트에 지수 백오프를 적용한 비동기 폴링을 구현해야 합니다. 웹 요청 핸들러 내부에서 동기적으로 대기하면 타임아웃이 발생합니다.
- 출시 직후에는 버스트 할당량이 빡빡합니다. 클립 5개를 연속으로 생성하면 속도 제한에 걸릴 가능성이 높습니다. 요청 사이에 무작위 지터(2~5초)를 추가하고, 예외를 사용자에게 노출하는 대신
ResourceExhaustedError를 재시도-백오프 로직으로 처리하세요. - 플랜 확인은 키 발급 시점이 아니라 요청마다 이루어집니다. 플랜 업그레이드 전에 발급된 키는 동작이 일관되지 않을 수 있습니다. 구독 업그레이드 후 예상치 못한 403 오류가 발생한다면 AI Studio에서 키를 재발급하세요 — 서버가 새 권한에 바인딩된 신규 토큰을 필요로 합니다 .
- SynthID와 C2PA는 제거할 수 없습니다. 프로덕션 투입 전에 스톡 푸티지 제출, 소셜 미디어 스케줄링 파이프라인, 법적 공개 워크플로에 이 점을 반영하세요. 일부 플랫폼은 AI 생성 및 워터마크 콘텐츠에 대한 명시적 정책을 두고 있습니다.
- 복잡한 다중 객체 장면에서는 물리 추론 품질이 저하됩니다. 출시 초기에는 단일 피사체 프롬프트가 가장 일관된 결과를 냅니다. 단순한 입력으로 먼저 검증한 뒤 장면 복잡도를 점진적으로 높이세요.
텍스트 프롬프트를 넘어서: 멀티모달 입력과 프로덕션 패턴
오디오 우선 생성. 녹음된 MP3 내레이션을 비주얼 브리프와 함께 제공하세요. Gemini Omni는 음성 트랙에 이미 동기화된 비디오를 생성하므로 별도의 오디오 정렬 작업이 필요 없습니다. 스크립트가 비주얼 설계 전에 확정되는 설명 영상이나 광고 제작에 실용적입니다.
멀티샷 시퀀스를 위한 Google Flow. Google Flow는 동일한 gemini-omni-flash 엔드포인트를 샷 단위 구조화 인터페이스로 감쌉니다. 긴 시퀀스의 수동 세션 관리를 줄여주고, 출시부터 YouTube Shorts 직접 게시 경로를 제공합니다 . 이미 Google Workspace를 사용하는 팀은 내보내기 단계를 완전히 생략할 수 있습니다.
투 모델 파이프라인. 스크립트 생성, 장면 구조화, 메타데이터 추출에는 Gemini 3.5 Flash를 앞단에 사용하고, 렌더링은 Gemini Omni Flash에 장면 프롬프트를 넘기세요. 경제성 면에서도 합리적입니다. 3.5 Flash는 추론 집약적 작업을 무료 티어에서 처리하고, Omni Flash는 렌더링 시점에만 유료 할당량을 소비합니다. 계획과 렌더링을 별도 단계로 분리하면 각각을 독립적으로 테스트할 수 있어, 비디오 할당량을 쓰기 전에 장면 설명을 저렴하게 반복 개선할 수 있습니다.
자주 묻는 질문
Gemini Omni와 Gemini 3.5 Flash의 차이는?
2026년 5월 19일 Google I/O에서 발표된 두 가지 별개의 제품입니다 . Gemini 3.5 Flash(gemini-3.5-flash)는 에이전틱 코딩과 장기 툴 활용을 위한 빠른 텍스트·멀티모달 모델로, AI Studio에서 무료 티어로 사용할 수 있습니다. Gemini Omni Flash(gemini-omni-flash)는 동영상 생성 및 대화형 동영상 편집에 특화된 월드 모델로, Google AI 유료 구독이 필요합니다. 두 모델은 엔드포인트를 공유하지 않으며, 사용 사례도 겹치지 않습니다.
Gemini Omni 동영상 생성 엔드포인트를 호출하려면 유료 플랜이 필요한가요?
그렇습니다. Google AI Plus, Pro, 또는 Ultra 구독이 필요합니다 . 이 확인은 키 발급 시점이 아니라 매 요청마다 서버 측에서 실행됩니다. 무료 계정에서 발급한 API 키는 일일 할당량과 관계없이 동영상 생성 호출 시 HTTP 403을 반환합니다. 업그레이드 후에도 403이 발생하면 AI Studio에서 키를 재생성해 새 구독 권한에 바인딩하세요.
API를 통한 대화형 동영상 편집은 어떻게 작동하나요?
client.chats.create(model="gemini-omni-flash")로 채팅 세션을 생성합니다. 해당 세션에서 첫 번째 generate_video() 호출이 초기 클립을 생성합니다. 이후 호출마다 자연어 편집 명령("조명을 황혼으로 바꿔줘", "자동차를 자전거로 바꿔줘")을 전달하면, 모델은 처음부터 생성을 다시 시작하지 않고 점진적 편집으로 적용합니다 . 세션 컨텍스트는 세션 객체를 닫거나 서버 측에서 타임아웃이 발생할 때까지 유지됩니다.
SynthID란 무엇이며 Gemini Omni 출력물의 상업적 이용에 영향을 미치나요?
SynthID는 모든 Gemini Omni 출력물에 출처 검증을 위한 C2PA Content Credentials과 함께 내장되는 감지 불가능한 디지털 워터마크입니다 . API를 통해 제거할 수 없으며, 워터마크를 없애는 옵트아웃 플래그나 후처리 경로도 존재하지 않습니다. 상업적 배포나 스톡 영상 제출 전, 대상 플랫폼의 이용 약관이 AI 생성 콘텐츠 공개를 요구하거나 내장 워터마크를 금지하는지 반드시 확인하세요.
기존 동영상 클립을 Gemini Omni의 입력으로 제공할 수 있나요?
가능합니다. MP4 클립은 모션 전이를 위한 참조 입력으로 사용할 수 있습니다. 모델은 참조 영상에서 모션 패턴과 미적 스타일을 추출해, 목표 출력에 대한 텍스트 설명과 결합하여 새로 생성된 장면에 적용합니다. 결과물은 참조 영상을 바탕으로 한 새로운 생성물이며, 원본 파일을 직접 변환한 것이 아닙니다. 멀티 클립 프로젝트에서 일관된 카메라 움직임이나 시각적 리듬을 유지하는 데 유용합니다.
다음으로 무엇을 만들까
명칭 혼란에는 짚고 넘어갈 실질적인 결과가 있습니다. "Gemini Omni 3.5"라는 제목의 튜토리얼이나 샘플 저장소는 거의 확실하게 서로 다른 플랜 제한을 가진 두 엔드포인트에 대한 조언을 혼합하고 있습니다. 코드를 적용하기 전에 그 점을 염두에 두고 해당 리소스를 검토하세요.
새 프로젝트에서 가장 명확한 방향은 2단계 파이프라인입니다. 무료 티어에서 Gemini 3.5 Flash로 기획·스크립팅하고, 유료 티어에서 Gemini Omni Flash로 렌더링하는 방식입니다. 이렇게 하면 반복 비용을 낮추고 할당량 소비를 예측 가능하게 유지할 수 있습니다. 참고로 Vertex AI에서 Gemini Omni Flash의 초당 동영상 출력 가격은 2026-05-31 기준 공개되지 않았습니다. 프로덕션 규모로 전환하기 전에 소규모 배치로 테스트하세요.
최종 업데이트: 2026-05-31. Google I/O 2026 발표(2026년 5월 19일) 및 출시 시점에 제공된 google-genai SDK 문서를 바탕으로 작성되었습니다.




