
Google I/O 2026 발표: Gemini 3.5 패밀리 한눈에
Gemini 3.5 Flash는 에이전틱 워크로드를 위한 Google DeepMind의 새로운 프로덕션 모델로, 2026년 5월 19일부터 안정적인 모델 ID gemini-3.5-flash로 제공됩니다 . Google I/O 2026의 일환으로 진행된 이번 출시에서는 두 모델로 구성된 패밀리가 소개되었습니다. Flash는 현재 GA 상태이며, Gemini 3.5 Pro는 Gemini API를 통해 2026년 6월 GA를 목표로 비공개 테스트 중입니다 . Google이 이 시리즈에 부여한 포지셔닝인 "Frontier Intelligence with Action"은 벤치마크 리더보드 최적화에서 벗어나, 완료된 작업당 총 API 호출 횟수를 줄이는 다단계 에이전틱 실행으로의 의도적인 아키텍처 전환을 의미합니다. Gemini 3.5 모델과 함께, Google은 같은 날 유료 Gemini 앱 사용자를 대상으로 Gemini Omni(멀티모달 영상 편집)도 출시했습니다 .
빠른 답변: Gemini 3.5 Flash(gemini-3.5-flash)는 2026년 5월 19일 GA로 출시되었으며, 입력 토큰 100만 개당 $1.50, 출력 토큰 100만 개당 $9.00의 요금이 적용됩니다. Gemini 3.1 Pro보다 약 40% 저렴하지만, Gemini 3 Flash보다는 약 5.5배 비쌉니다. thinking_budget 파라미터는 더 이상 사용되지 않으며 런타임 오류를 발생시킵니다. 이 모델 ID로 전환하기 전에 모든 호출자는 thinking_level로 마이그레이션해야 합니다.
이번 발표는 Google DeepMind 리서치 부사장 Koray Kavukcuoglu가 작성했으며, 이 세대에 대한 그의 표현은 간결했습니다:
"Frontier Intelligence with Action." — Koray Kavukcuoglu, Google DeepMind 리서치 부사장, Google I/O 2026에서 Gemini 3.5 시리즈 소개 시 (source: Google DeepMind Blog)
3.5 Flash의 Gemini 3 Flash 대비 높은 토큰당 비용은 이러한 포지셔닝에서 직접 비롯됩니다. Google의 논리는 이렇습니다. 모델이 8번의 API 호출 대신 2번으로 작업을 완료한다면, 토큰당 프리미엄이 붙더라도 작업 완료가 가치의 기준이 되는 에이전틱 파이프라인의 총 비용을 줄일 수 있다는 것입니다. 이 계산이 여러분의 특정 워크로드에 적용될지는 실증적으로 확인해야 하며, 보장되지 않습니다. 자세한 내용은 아래 요금 섹션에서 다룹니다.
더 넓은 I/O 2026 개발자 영역에는 Managed Agents API(Antigravity 2.0 런타임을 기반으로 한 호스팅 실행 환경), Gemini Spark(미국 내 Google AI Ultra 구독자 전용 24시간 365일 개인 백그라운드 에이전트, 월 $100이며 개발자 API 액세스는 미발표), 그리고 데스크톱 앱·CLI·개발자 SDK로 새롭게 개편되어 출시되는 Antigravity 2.0 플랫폼도 포함됩니다. Google I/O 2026 개발자 하이라이트에 따르면, gemini-3.5-flash는 이제 전 세계 Gemini 소비자 앱과 Google 검색 AI 모드의 기본 모델로도 적용됩니다.
컨텍스트 윈도우, 처리량, 런타임 아키텍처
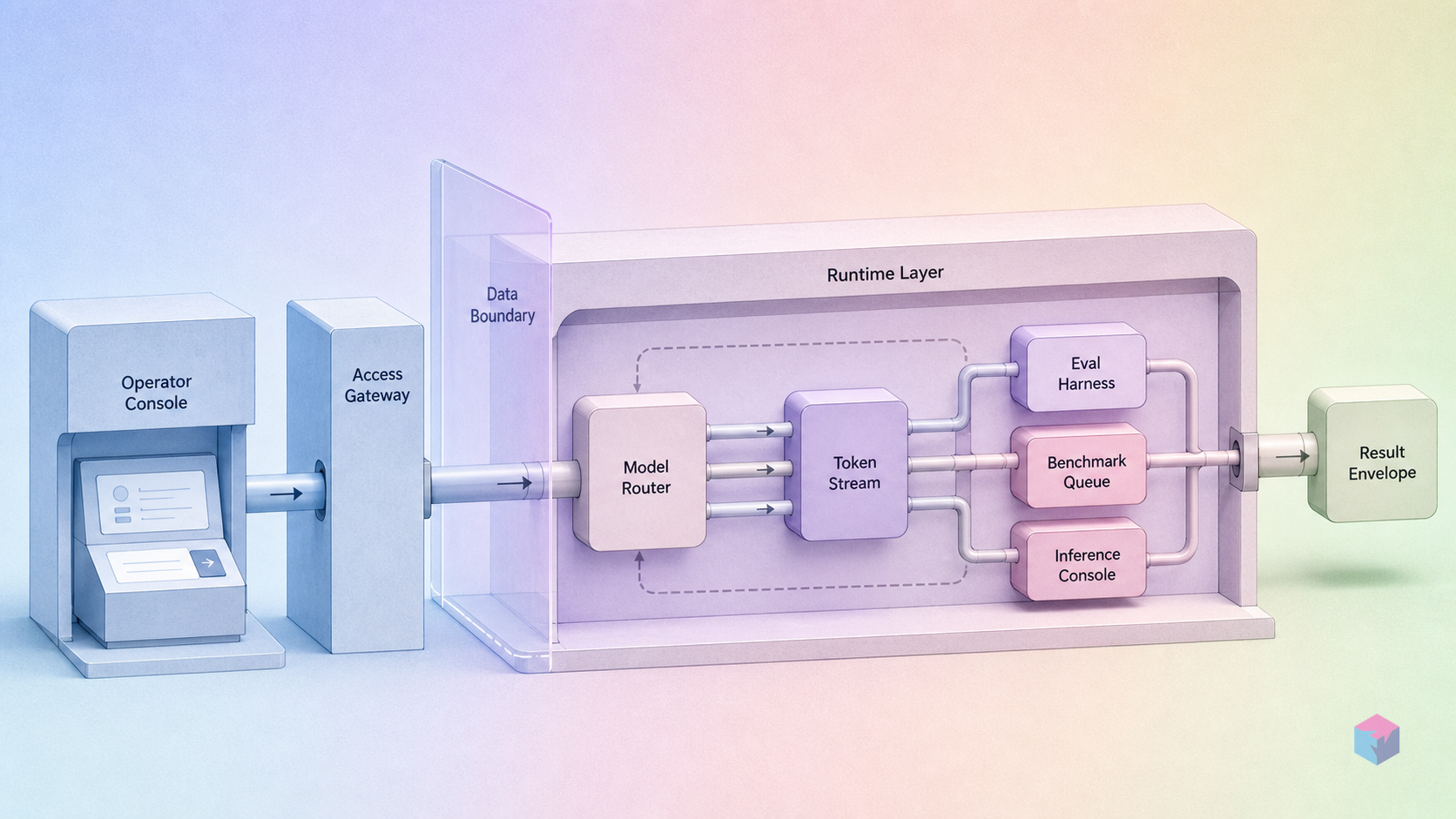
Gemini 3.5 Flash는 1,048,576토큰(~1M) 컨텍스트 윈도우와 최대 65,536개의 출력 토큰을 지원하며, 텍스트·이미지·영상·오디오를 포함한 완전한 멀티모달 입력을 지원합니다 . 공개 API 처리량은 초당 약 280토큰이며, Google은 이를 같은 역량 등급의 비교 가능한 프론티어 모델보다 4배 빠르다고 주장합니다 . Antigravity 2.0 런타임 내에서는 처리량이 공개 API 대비 12배까지 올라갑니다. 인퍼런스 API를 직접 호출하는 대신 Google 자체 오케스트레이션 레이어에서 워크로드를 실행한다면 의미 있는 차이입니다 .
1M 컨텍스트 윈도우는 청킹 없이도 멀티세션 대화 히스토리, 전체 레포지토리 코드베이스, 또는 연결된 문서 모음을 담기에 충분합니다. 실제로 대규모 운영에서 주된 제약은 용량이 아니라 비용입니다. 대용량 파이프라인에서 호출당 백만 토큰을 입력하면 $1.50/1M 입력 단가로 비용이 누적됩니다. $0.15/1M 캐시 입력 단가의 프롬프트 캐싱 티어(캐시 히트 시 약 90% 할인)는 대규모 공유 프리픽스가 여러 호출에 반복될 때 경제성을 크게 바꿉니다. 자세한 내용은 요금 섹션에서 다룹니다.
출시에서 가장 구체적인 처리량 데이터 포인트는 I/O 키노트 데모입니다. 93개의 병렬 서브에이전트가 약 12시간 만에 기능하는 운영 체제를 구축했으며, 15,000건 이상의 API 요청과 26억 토큰을 총 API 크레딧 $1,000 미만에 소비했습니다 . 암시된 캐시 히트율은 상당합니다. 표준 $1.50/1M 입력 단가로 26억 토큰을 계산하면 할인 전 약 $3,900에 달하므로, $1,000 미만의 청구서는 높은 캐시 활용을 전제합니다. 이 데모는 직접 재현 가능한 벤치마크가 아닌, 대규모 비용 보정 지점으로 참고하시기 바랍니다.
Antigravity 2.0는 아키텍처상 원시 API 액세스와 완전 관리형 실행 환경 사이에 위치합니다. Managed Agents API의 기반이 되며, Gemini 3.5 Flash를 12배 속도 이점으로 실행하고, 퍼스트클래스 병렬 서브에이전트 오케스트레이션과 예약된 백그라운드 작업 지원을 추가합니다. 이는 플랫폼 프리미티브이지, 인퍼런스 API를 감싸는 사용자 빌드 래퍼가 아닙니다. 멀티 에이전트 오케스트레이션 인프라를 직접 구축할지 구매할지 고려 중이라면 중요한 차이점입니다. Antigravity 2.0 플랫폼 전체 기능에 대한 자세한 내용은 Managed Agents 섹션에서 다룹니다.
벤치마크 결과: 3.5 Flash가 앞서는 영역과 뒤처지는 영역
Gemini 3.5 Flash는 대부분의 에이전틱·코딩 벤치마크에서 이전 플래그십인 Gemini 3.1 Pro를 넘어섰으나, 장문 컨텍스트 검색에서는 공개된 약점이 하나 있습니다. Terminal-Bench 2.1은 76.2%로 3.1 Pro의 70.3%를 앞섰고, GDPval-AA 에이전틱 Elo는 1,656, MCP Atlas 툴 사용 점수는 83.6%, MMMU-Pro와 CharXiv Reasoning은 83.6–84.2%를 기록했습니다 . 공개된 약점은 하나로, MRCR v2 128k(장문 컨텍스트 검색)에서 77.3%를 기록하며 점수를 공개하지 않은 3.1 Pro에 여전히 뒤처집니다 . 실용적 결론: 3.5 Flash는 에이전틱 툴 사용 파이프라인의 기본 선택으로 충분히 강력하며, 장문 컨텍스트 RAG 워크로드는 3.1 Pro에서 마이그레이션하기 전 별도 검증이 필요합니다.
| 벤치마크 | Gemini 3.5 Flash | Gemini 3.1 Pro | 비고 |
|---|---|---|---|
| Terminal-Bench 2.1 | 76.2% | 70.3% | 3.5 Flash가 +5.9 pp 앞섬 |
| GDPval-AA (에이전틱 Elo) | 1,656 | — | Google 자체 발표; 출시 시점 기준 독립 검증 없음 |
| MCP Atlas (툴 사용) | 83.6% | — | Google 자체 발표; 출시 시점 기준 독립 검증 없음 |
| MMMU-Pro | 83.6% | — | 멀티모달 이해 |
| CharXiv Reasoning | 84.2% | — | 차트 이해 및 추론 |
| Text + Code Arena | #9 / 1,507 | — | Gemini 3 Flash 대비 +70점; 독립적 크라우드 순위 |
| MRCR v2 128k | 77.3% | 앞섬 (점수 미공개) | 장문 컨텍스트 검색 — 3.1 Pro가 여전히 우위 |
이 수치들을 그대로 받아들이기 전에 두 가지 주의사항을 짚어야 합니다. GDPval-AA와 MCP Atlas는 Google이 설계하고 Google이 발표한 벤치마크입니다. Latent Space에 따르면, 5월 19일 발표 시점 기준으로 독립적인 제3자 재현 결과는 아직 없습니다. Text and Code Arena 순위(#9, 점수 1,507)는 현재 가장 중립적인 크로스모델 데이터 포인트로, 모델 벤더가 아닌 실제 사용자의 쌍별 비교 평가를 기반으로 합니다. Gemini 3 Flash 대비 +70점 향상(기준 점수 약 1,437 추정)은 세대 간 성능 차이를 가늠하는 대략적인 척도가 됩니다.
MRCR v2 128k 격차는 대용량 문서 코퍼스를 컨텍스트로 전달해 정밀한 스팬 수준 검색을 기대하는 RAG 워크로드에 직접적인 운영 영향을 미칩니다. 여러 참조 문서를 하나의 긴 프롬프트로 연결해 쿼리하는 파이프라인이라면, 3.5 Pro 벤치마크 데이터가 공개될 때까지 3.1 Pro를 유지하는 편이 낫습니다. 반면 함수 호출, MCP 툴 사용, 복수의 계획 단계를 포함한 에이전트 루프 등 툴 호출이 많은 워크로드에서는 Terminal-Bench와 MCP Atlas 결과를 감안할 때 3.5 Flash가 3.1 Pro보다 낮은 비용으로 더 나은 성능을 발휘합니다. 두 워크로드 유형은 마이그레이션 일정을 별도로 수립할 필요가 있습니다.
가격: Gemini 3 Flash 및 3.1 Pro와의 비용 비교
Gemini 3.5 Flash는 글로벌 리전 엔드포인트 기준으로 입력 토큰 1M당 $1.50, 출력 토큰 1M당 $9.00, 캐시된 입력 토큰 1M당 $0.15로 책정되어 있으며, 캐시 히트 시 약 90% 할인이 적용됩니다 . 비글로벌 리전 접근은 입력 1M당 $1.65, 출력 1M당 $9.90으로 소폭 높습니다 . 이전 플래그십 모델과 비교하면, 3.5 Flash는 입력·출력 모두에서 Gemini 3.1 Pro보다 약 40% 저렴하면서도 에이전틱 벤치마크에서 더 높은 점수를 기록합니다 — 가격 대비 성능 측면에서 3.1 Pro와의 비교가 가장 명확한 기준이 됩니다 .
| 모델 | 입력 ($/1M 토큰) | 출력 ($/1M 토큰) | 캐시된 입력 ($/1M) | 3.5 Flash 대비 |
|---|---|---|---|---|
| Gemini 3.5 Flash (글로벌) | $1.50 | $9.00 | $0.15 | — |
| Gemini 3.5 Flash (비글로벌) | $1.65 | $9.90 | n/a | +10% |
| Gemini 3.1 Pro (추정) | ~$2.50 | ~$15.00 | n/a | +67% (3.5 Flash 약 40% 저렴) |
| Gemini 3 Flash (추정) | ~$0.27 | ~$1.64 | n/a | −82% (3.5 Flash 약 5.5배 비쌈) |
Gemini 3.1 Pro 및 3 Flash 수치는 공개된 배율로부터 추정한 값입니다: 3.5 Flash는 3.1 Pro보다 약 40% 저렴하고, 3 Flash보다는 약 5.5배 비쌉니다 . 비용 모델을 수립하기 전에 Google Cloud 블로그와 공식 가격 페이지에서 수치를 반드시 확인하세요.
Gemini 3 Flash와의 비교는 더 면밀한 검토가 필요합니다. 토큰당 비용이 약 5.5배 높은 만큼, 비용 중립성이 성립하려면 에이전틱 작업이 훨씬 적은 총 API 호출 수로 완료되어야 합니다. Google의 논리는, 계획 수립과 도구 활용 능력이 뛰어난 모델일수록 재시도 호출, 계획 수정 루프, 검증 단계가 줄어들어 작업 완료당 총 토큰 소비가 감소한다는 것입니다. 이 논리 자체는 타당하지만, 실제로 여러분의 파이프라인에서 그 효과가 나타날지는 가정이 아닌 측정으로 확인해야 합니다. 현재 Gemini 3 Flash 파이프라인에서 첫 시도 성공률이 이미 높고 호출 횟수도 적다면, 비용만을 근거로 5.5배 프리미엄을 정당화하기는 어렵습니다.
$0.15/1M의 프롬프트 캐싱 티어 — 약 90% 할인 — 는 대용량 배포에서 비용 절감 효과가 가장 큰 레버입니다. 시스템 프롬프트, 참조 컨텍스트, 페르소나 정의의 합계가 50,000 토큰이고 하루 10,000회 호출에 걸쳐 반복된다면, 해당 프리픽스의 캐시 적용 비용은 하루 $0.75인 반면 표준 입력 요금으로는 $7.50입니다. 하루 100,000회 호출 시 그 차이는 $675에 달합니다. 전제 조건은 하나입니다: 캐시 키 일관성을 유지하려면 프롬프트 프리픽스가 요청 간에 안정적으로 유지되어야 합니다. 공유 프리픽스를 자주 수정하면 캐시가 무효화되어 할인 혜택이 사라집니다.
thinking_budget에서 thinking_level로: API 주요 변경 사항 마이그레이션
thinking_budget 파라미터(추론 트레이스의 토큰 할당을 제어하는 정수)는 지원이 중단되었으며, 대상 모델이 gemini-3.5-flash일 때 현재 SDK에서 런타임 오류를 발생시킵니다 . thinking_budget을 전달하는 코드는 모델 ID 전환 즉시 실패합니다. 유예 기간도, 자동 폴백도, 지원 중단 경고 단계도 없습니다 — 호출 시점에 즉시 오류가 발생합니다. 모델 ID를 변경한 후가 아니라, 변경하기 전에 이 문제를 반드시 먼저 수정하세요.
대체 파라미터는 thinking_level로, minimal·low·medium·high 네 가지 값을 받는 문자열 열거형입니다 . 더 큰 영향은 파라미터 이름 변경이 아니라 기본값이 high에서 medium으로 바뀐 것입니다. gemini-3-flash-preview에서 포팅한 코드가 thinking_level 값을 명시하지 않으면, 오류·경고·동작 변화 신호 없이 호출당 추론 깊이가 조용히 낮아집니다. 평가 스위트가 추론 깊이보다 출력 형식의 정확성에 집중한다면, 이 회귀는 테스트에서 쉽게 놓칩니다.
# 이전 코드 — model="gemini-3.5-flash"일 때 RuntimeError 발생
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=prompt,
config={"thinking_budget": 8192} # 지원 중단됨 — 즉시 오류 발생
)
# 이후 코드 — 이전 기본 동작과 일치하도록 명시적으로 설정
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=prompt,
config={"thinking_level": "high"} # 이전 기본값 복원
)
# medium으로 품질을 검증한 경우에만 새 기본값 수용
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=prompt,
config={"thinking_level": "medium"} # 새 기본값 — 명시적으로 지정하는 것이 더 안전
)
thinking_level 값 조정 방법: high는 내부 추론 트레이스에 더 많은 토큰을 할당하며 지연 시간이 비례해 증가합니다. minimal은 최소한의 추론으로 가장 빠르게 실행됩니다. 에이전트형 도구 사용 작업(다단계 계획, 함수 호출 시퀀스, 복잡한 코드 생성 등)에서는 high가 눈에 띄게 더 나은 결과를 냅니다. 추가 추론 단계가 도구 호출 체인을 통해 전파되기 전에 계획 오류를 잡아내기 때문입니다. 단순한 분류·추출·요약·단문 생성 작업에서는 medium이나 low가 일반적으로 더 낮은 비용과 지연 시간으로 동등한 결과를 냅니다. 최적 설정은 작업에 따라 다르므로, 기본값을 수용하기 전에 평가 세트에서 두 수준을 모두 실행해 품질 차이를 직접 측정하세요.
두 번째 신규 기능인 다중 턴 대화에서의 사고 보존(thought preservation)은 파괴적 변경이 아닌 추가 기능입니다. 활성화하면 모델의 추론 상태가 API 호출 간에 유지되므로, 각 턴 시작 시 추론 체인을 다시 프롬프트할 필요가 없습니다 . 다중 턴 에이전트 루프에서 턴 간 컨텍스트 재설정은 지속적인 지연 시간 및 토큰 오버헤드의 원인이었습니다. 사고 보존은 대화 기록에서 컨텍스트를 재구성하는 대신 이전 추론 상태에서 바로 이어갈 수 있게 해 이 오버헤드를 없앱니다.
마이그레이션 체크리스트 — 모델 ID 변경 전, 순서대로 실행:
- 코드베이스에서
thinking_budget을 검색하여 모든 인스턴스를thinking_level="high"로 교체해 이전 동작과 일치시킵니다 - 현재
thinking_level을 생략한 모든 호출 지점에 명시적인thinking_level값을 추가합니다. 어떤 호출 지점에서도 기본값에 의존하지 마세요 thinking_level="medium"으로 평가 스위트를 실행하여"high"대비 품질 차이를 정량화한 후, 작업 유형별로 새 기본값을 수용할지 결정하세요- 다중 턴 흐름에서 사고 보존 동작을 검증하고, 오케스트레이션 레이어가 세션 상태를 올바르게 처리하는지 확인하세요
- 위 단계가 모두 통과된 후 마지막으로 모델 ID를 변경하세요
Managed Agents API와 Antigravity 2.0 플랫폼
Managed Agents API(에이전트 식별자: antigravity-preview-05-2026)는 단일 API 호출로 완전한 호스팅 실행 환경을 프로비저닝합니다 . 모델 출력만 반환하는 Gemini 추론 API 직접 호출과 달리, Managed Agents API는 에이전트에게 Bash·Python·Node.js를 실행하는 영구 Linux 샌드박스와 파일 처리, 웹 브라우징, Google Cloud Storage 버킷 또는 코드 저장소를 에이전트 환경에 직접 마운트하는 기능을 제공합니다. 상태는 세션 내 호출 간에 유지되므로, 각 턴마다 샌드박스를 재프로비저닝하거나 재초기화할 필요가 없습니다.
Managed Agents API 발표에 따른 관리형 에이전트 세션 내 추가 내장 기능:
- 마크다운으로 정의하는 커스텀 스킬 — 마크다운으로 스킬 정의를 제공해 에이전트 기능 확장, 커스텀 오케스트레이션 코드 불필요
- GCS 및 저장소 마운트 — 스토리지 또는 소스 트리를 직접 연결, 에이전트가 네이티브로 읽기·쓰기·실행 가능
- 웹 브라우징 — 별도의 브라우저 자동화 레이어 없이 외부 URL을 가져와 파싱
- 병렬 서브에이전트 오케스트레이션 — 여러 에이전트를 동시에 디스패치하고 결과를 집계, 원시 API 위에 구축하는 패턴이 아닌 플랫폼 기본 요소
- 예약된 백그라운드 작업 — 자체 크론 인프라 없이 에이전트를 일정에 따라 실행하도록 등록
이로써 Google은 에이전트 작업용 관리형 컴퓨팅을 프로비저닝하는 OpenAI의 Codex 실행 환경 및 Anthropic의 컴퓨터 사용 기본 요소와 직접 경쟁하게 됩니다. Google의 아키텍처적 차별점: Antigravity 2.0 런타임이 Managed Agents API의 기반을 이루므로, 공개 API 대비 12× 처리량 향상이 관리형 실행 컨텍스트 내에서도 그대로 적용됩니다. Antigravity 2.0은 데스크톱 애플리케이션·CLI·개발자 SDK 형태로 제공되어 최종 사용자 제품과 프로그래매틱 통합 대상 모두로 접근 가능합니다.
프로덕션 도입 전에 고려해야 할 실질적인 한계 두 가지. 첫째, Flash 토큰 비용을 초과하는 샌드박스 컴퓨팅 가격은 출시 시점 기준 공개되지 않았습니다 — 관리형 실행의 전체 비용 모델은 미지수입니다. 둘째, antigravity-preview-05-2026 식별자는 프리뷰 제품임을 나타내며, 프리뷰와 GA 사이의 API 표면 변경 가능성이 높습니다. 지금 기능을 평가하되, Google이 안정적인 식별자와 전체 가격을 공개할 때까지 Managed Agents API를 안정적인 프로덕션 의존성이 아닌 기능 평가 창구로 취급하세요.
Gemini 3.5 Pro 출시 일정과 개발자 마이그레이션 경로

Gemini 3.5 Pro는 2026년 5월 19일 비공개 테스트에 돌입했으며, Gemini API를 통해 2026년 6월 GA를 목표로 하고 있습니다 . 벤치마크 결과와 가격은 아직 발표되지 않았습니다. 공개된 3.5 Flash의 약점 — MRCR v2 128k 77.3%로 3.1 Pro가 여전히 앞서는 영역 — 을 감안하면, 3.5 Pro의 역할은 그 장문 컨텍스트 검색 격차를 좁히고 Flash가 현재 뒤처지는 추론 집약적 워크로드에서 선두를 차지하는 것으로 예상됩니다 . 가격은 "완전한 기능을 갖춘 플래그십" 포지셔닝을 고려할 때 3.1 Pro를 상회할 것이 거의 확실하며, 공식 API 가격 페이지가 업데이트될 때 3.1 Pro 요금을 초과할 것으로 예상됩니다.
지금 개발 중인 팀에 대한 실질적 시사점: 모든 호출 지점에 "gemini-3.5-flash"를 하드코딩하는 대신 추상화 레이어를 통해 모델 접근을 라우팅하세요. 설정 변수나 모델 리졸버를 두면, 복잡도가 높은 태스크에서 3.5 Pro로의 전환이 코드베이스 리팩터링이 아닌 설정 변경으로 끝납니다. thinking_level 기본값에도 같은 원칙을 적용하세요 — 중앙화해두면 3.5 Pro GA 시점에 기본 동작이 바뀌더라도(Flash와 동일한 medium 기본값 패턴을 따를 것으로 예상) 파이프라인 전반에서 태스크 품질이 명확한 감사 추적 없이 조용히 저하되는 사태를 막을 수 있습니다.
2026년 6월까지 모니터링할 항목:
- 3.5 Pro GA 일정 및 가격 발표를 위한 공식 Google Cloud 블로그
- 3.5 Pro의 MRCR v2 128k 벤치마크 수치 — 장문 컨텍스트 RAG 마이그레이션 결정의 핵심 기술 지표
- 3.5 Flash의 GDPval-AA(Elo 1,656)와 MCP Atlas(83.6%) 수치에 대한 독립적 제3자 재현 결과 — 에이전틱 파이프라인 아키텍처를 해당 수치에 커밋하기 전에 검증 필요
- Managed Agents API 안정 식별자 및 전체 컴퓨트 가격 공개
현재 시점의 의사결정 기준: 주로 장문 컨텍스트 검색 워크로드에 Gemini 3.1 Pro를 사용 중이라면, 3.5 Pro의 MRCR v2 수치가 공개될 때까지 마이그레이션을 보류하세요. 에이전틱 툴 사용, 코딩, 또는 다단계 계획 태스크에 3.1 Pro를 사용 중이라면, 3.5 Flash가 이미 약 40% 낮은 비용으로 더 나은 벤치마크 성능을 제공합니다 — thinking API 변경 사항을 먼저 적용한 뒤 지금 바로 마이그레이션하세요.
자주 묻는 질문
Gemini 3.5 Flash는 gemini-3-flash-preview와 하위 호환이 되나요?
완전하지는 않습니다. 모델 ID가 gemini-3.5-flash로 변경되었으며, thinking API는 호환이 깨지는 변경 사항입니다. 기존의 thinking_budget 정수 파라미터는 새 SDK에서 런타임 오류를 발생시키므로, minimal, low, medium, high를 허용하는 문자열 열거형인 thinking_level로 교체해야 합니다 . 기본 추론 수준이 high에서 medium으로 바뀌었기 때문에, gemini-3-flash-preview에서 이식한 코드에서 thinking_level을 명시하지 않으면 오류·경고·가시적 신호 없이 호출당 추론량이 줄어듭니다. 기존 동작을 유지하려면 모든 호출 지점에서 thinking_level="high"를 명시적으로 설정하고, 이후 작업 유형별로 medium 기본값이 적합한지 평가하세요.
thinking_level='medium'과 'high'는 실제로 어떤 차이를 만드나요?
thinking_level은 모델이 출력 생성 전에 내부 추론 트레이스에 할당하는 토큰 수를 제어합니다. 수준이 높을수록 더 많은 토큰을 소비하고 지연이 늘어나며, 낮을수록 덜 숙고하되 더 빠르게 실행됩니다. medium은 새 SDK의 기본값으로, 단순한 생성 작업(분류, 추출, 요약, 단답형 Q&A)에는 충분하지만, 심층 추론 트레이스가 계획 오류를 호출 시퀀스 전반에 전파되기 전에 잡아야 하는 복잡한 다단계 계획이나 에이전트 도구 사용 체인에는 부족할 가능성이 높습니다. high는 이전 기본 동작을 복원하며, 에이전트 파이프라인·복잡한 코드 생성·멀티홉 추론 작업의 권장 시작 지점입니다. 평가에서 두 수준을 작업 분포에 적용해 보정하세요. medium이 품질 기준을 충족한다면, 출력 차이 없이 지연 감소와 토큰 비용 절감을 얻을 수 있습니다.
에이전트 벤치마크에서 Gemini 3.5 Flash는 Claude Sonnet이나 GPT-4o와 어떻게 비교되나요?
벤치마크 설계상 벤더 간 직접 비교는 복잡합니다. Google은 Gemini 3.5 Flash에 대해 GDPval-AA(Elo 1,656)와 MCP Atlas(83.6%)를 발표했지만, 2026년 5월 19일 발표 시점 기준으로 해당 수치의 독립적인 제3자 재현 결과는 아직 공개되지 않았습니다 . 가장 중립적인 모델 간 신호는 Text and Code Arena 순위로, Gemini 3.5 Flash는 벤더 설계 벤치마크가 아닌 실제 작업 기반 군중 평가 쌍별 비교에 따라 1,507점으로 9위에 올라 있습니다 . Claude Sonnet 또는 GPT-4o와의 프로덕션 비교를 위해서는 실제 환경에서 동일한 작업으로 두 모델을 직접 실행하세요. 서로 다른 벤치마크 설계에서 나온 벤더 보고 수치는 벤더 간에 직접 비교할 수 없습니다.
Managed Agents API란 무엇이며, Gemini API 직접 호출과 어떻게 다른가요?
Managed Agents API는 에이전트 식별자 antigravity-preview-05-2026로 단일 API 호출만으로 완전한 호스팅 실행 환경을 제공합니다. Bash·Python·Node.js 런타임을 갖춘 영구 Linux 샌드박스와 파일 처리, 웹 브라우징, GCS 및 저장소 마운트, 병렬 서브에이전트 오케스트레이션이 포함됩니다 . Gemini 추론 API를 직접 호출하면 모델 출력만 반환됩니다. 컴퓨팅 환경, 상태 관리, 실행 인프라는 직접 구축하고 유지해야 합니다. Managed Agents API는 원시 모델 API보다는 운영자 관리형 에이전트 플랫폼에 가까우며, 개념적으로 OpenAI의 Codex 실행 환경과 경쟁합니다. 현재 프리뷰 단계이며, Flash 토큰 비용 외의 컴퓨팅 요금은 아직 공개되지 않았습니다.
Gemini 3.5 Pro는 언제 출시되며 가격은 어떻게 되나요?
Gemini 3.5 Pro는 2026년 5월 19일 비공개 테스트에 진입했으며, Gemini API를 통한 2026년 6월 GA를 목표로 하고 있습니다 . 가격은 아직 발표되지 않았습니다. 3.5 Flash와 3.1 Pro 모두를 뛰어넘는 '풀캐퍼빌리티 플래그십' 포지셔닝을 고려하면, 공식 발표 시 가격은 3.1 Pro 요금을 초과할 것으로 예상됩니다. Pro 출시 시 주목해야 할 벤치마크는 MRCR v2 128k 장문 컨텍스트 검색입니다. 이는 3.5 Flash에서 공개된 격차(77.3%)이며, 3.5 Pro가 이를 메우는지 여부가 장문 컨텍스트 RAG 워크로드를 3.1 Pro에서 이전할지를 결정합니다. GA 날짜, 가격, 벤치마크 공개를 위해 Google DeepMind 블로그를 모니터링하세요.
지금 구축할 것, 기다려야 할 것
Gemini 3.5 Flash는 대부분의 세대 전환보다 개발자에게 더 깔끔한 업그레이드 경로를 제공합니다. 에이전트 벤치마크 성능 향상, 이전 플래그십 대비 약 40% 비용 절감, 출시 첫날부터 GA 제공이 그것입니다. thinking API 마이그레이션이 주요 운영 위험입니다. thinking_level="high"를 명시하지 않고 코드를 이식하면 눈에 띄지 않는 동작 회귀가 발생합니다. 올바른 순서는 먼저 thinking_budget 교체를 수정하고 모든 호출 지점에 명시적인 thinking_level 값을 추가한 다음, 평가를 실행하고 모델 ID를 변경하는 것입니다. 순서를 바꾸면 파라미터 지원 종료 오류와 추론 깊이 회귀를 동시에 디버깅하게 됩니다.
현재 멀티에이전트 파이프라인을 위한 커스텀 오케스트레이션 인프라를 유지하고 있다면, Managed Agents API와 Antigravity 2.0 플랫폼은 직접 평가해 볼 가치가 있습니다. 일급(first-class) 병렬 서브에이전트 지원과 공개 API 처리량의 12배로 실행되는 예약 백그라운드 작업 실행은 직접 소유하고 운영해야 하는 인프라 범위를 의미 있게 줄일 수 있습니다. 프리뷰 지정과 미공개 컴퓨팅 요금은 아직 프로덕션 워크로드를 맡기지 말 것을 시사합니다. 스테이징 환경에서 구축하면서 안정 릴리스와 전체 비용 공개를 기다리세요.
현재 Gemini 3.1 Pro를 사용 중인 팀은 워크로드 유형별로 마이그레이션 결정을 분리하세요. 에이전트 도구 사용 및 코딩 작업은 지금 3.5 Flash로 이전하세요. 벤치마크가 더 좋고, 비용도 낮으며, GA 상태가 확인되었습니다. 장문 컨텍스트 RAG 워크로드는 3.5 Pro MRCR v2 데이터로 합리적 판단이 가능해지는 2026년 6월까지 보류하세요. 지금 모델 ID 추상화 레이어 중심으로 코드를 구성해 두면, 나중에 그 결정이 리팩터링이 아닌 설정 업데이트로 처리됩니다.
마지막 업데이트: 2026-05-28. 이 글은 2026년 5월 19일 Google I/O 2026에서 발표된 Gemini 3.5 Flash GA 릴리스를 기반으로 합니다. Gemini 3.5 Pro 벤치마크 데이터, 가격, GA 날짜는 2026년 6월 예정인 공식 발표를 기다리고 있습니다.






