
On May 29, 2026 , the vLLM project tagged both v0.22.0 stable and v0.22.1rc0 on the same calendar day — the second consecutive release where this dual-tag pattern appeared. The stable release incorporates 459 commits from 230 contributors and includes substantive work on DeepSeek V4 serving, Cutlass FP8 kernels, tiered KV cache offloading, and an experimental Rust frontend. The rc0 tag is a single CI fix with zero user-facing effect. Here is what actually changed and what requires action before you upgrade.
Concurrent GA + rc0: vLLM's New Dual-Tag Cadence
vLLM now ships two version tags on GA day: a stable release and an immediate signal that the patch branch is open. v0.22.0 and v0.22.1rc0 both landed on May 29, 2026 . The same dual-tag appeared for v0.21.0 and v0.21.1rc0 on May 15, 2026 — confirming this is deliberate release-branch policy, not a one-off accident.
Quick Answer: v0.22.0 is the shippable stable release (459 commits, 230 contributors, 63 first-timers). v0.22.1rc0 is a single CI test-harness fix with no user-facing changes. Deploy v0.22.0 now; rc0 has nothing for production operators.
The v0.22.0 release incorporated 459 commits from 230 contributors, including 63 first-time contributors — one of the larger point releases by commit volume in the project's history. The branch policy behind the dual-tag is documented in RELEASE.md: after a GA tag, a release/vX.Y branch opens and admits only regression, critical, and documentation cherry-picks.
"After a minor release is tagged, a release branch is opened. Only regression fixes, critical bug fixes, and documentation updates will be cherry-picked to the release branch." — vLLM RELEASE.md
For operators: deploy v0.22.0 now. Monitor the v0.22.1rcN tag sequence on GitHub if you run DeepSeek V4 or Cutlass FP8 paths in production — those are the active surfaces most likely to receive regression cherry-picks. One precedent worth noting: v0.21.1rc0 (May 15, 2026) never reached a GA stable tag . vLLM's bi-weekly minor cadence may advance directly to v0.23.0 before v0.22.1 promotes to stable, unless critical bugs accumulate.
DeepSeek V4 Gets a Dedicated Package: NVFP4 MoE, CUDA Graph, MTP Decoding
DeepSeek V4 model code was reorganized from the generic MoE path into a dedicated vllm/models/deepseek_v4/ package in v0.22.0 . Import paths change accordingly — grep your codebase for any direct module imports from the old MoE path before upgrading. Four functional additions shipped with the new package:
- NVFP4 fused MoE: FP4-quantized MoE expert weights fused into a single GPU kernel on Hopper-class hardware (H100/H200). Lower memory bandwidth than FP8 or FP16 MoE — but FP4 introduces additional quantization error. Benchmark accuracy on your specific task before switching workloads from FP8.
- Full and piecewise CUDA graph execution: Captures more of the DeepSeek V4 forward pass in static graphs, cutting per-step overhead. The piecewise variant handles dynamic shapes that full-graph mode cannot accommodate.
- MTP (Multi-Token Prediction) speculative decoding: Auxiliary heads generate draft tokens in parallel with the main decoding head. Potential latency gains on long-generation workloads — measure against your sequence-length distribution before enabling.
- Kernel accuracy fixes: The changelog explicitly flags several of these as correctness-relevant, not just performance improvements . Review these regardless of whether you adopt the new features — they matter for any existing DeepSeek V4 production deployment.
The kernel accuracy fixes are the highest-priority item for existing DeepSeek V4 deployments. NVFP4, CUDA graphs, and MTP are opt-in features that require workload-specific validation before adoption.
28.9% Latency Drop, KV Cache Offloading, and the Experimental Rust Frontend
Cutlass FP8 kernels in compile mode on SM80 (Ampere) delivered a measured 28.9% end-to-end latency improvement per the v0.22.0 release notes . That number comes from the project's own benchmarks — independent reproduction is needed before treating it as universally applicable across batch sizes, sequence lengths, and model architectures.
| Feature | Hardware Target | Status | Developer Action |
|---|---|---|---|
| Cutlass FP8 kernels (compile mode) | SM80 Ampere | Stable | Benchmark on your workload before assuming 28.9% |
| NVFP4 fused MoE (DeepSeek V4) | Hopper+ H100/H200 | Stable | Validate accuracy vs FP8/FP16 before switching |
| Tiered KV cache offloading | GPU HBM / CPU DRAM / Disk | Stable | Profile block access patterns; each tier adds latency |
| MR V2 (Qwen3 oracle, sleep-reload, update_config) | All | Stable (auto-fallback to MRv1) | No action unless using incompatible KV connector |
| Rust frontend + DP Supervisor | All | Experimental — unstable API | Do not use in production; treat as infrastructure groundwork |
| Blackwell/SM12x, ROCm, RISC-V RVV kernels | Respective hardware | Stable (additive) | No action required |
The tiered KV cache offloading framework uses three storage tiers: hot blocks stay on GPU HBM, warm blocks spill to CPU DRAM, and cold blocks go to a Python filesystem tier or the Mooncake disk backend. The value proposition is extended effective context capacity beyond GPU memory. The trade-off is per-tier access latency — profile your block access patterns before enabling, and decide whether extended context justifies the added latency on your workload.
Model Runner V2 additions include Qwen3 dense model oracle selection (automatic variant routing), sleep-mode weight reload, an update_config API, and shared KV-cache layers across transformer blocks. MR V2 auto-falls back to MRv1 when an incompatible KV connector is detected, making the migration path non-breaking for most deployments.
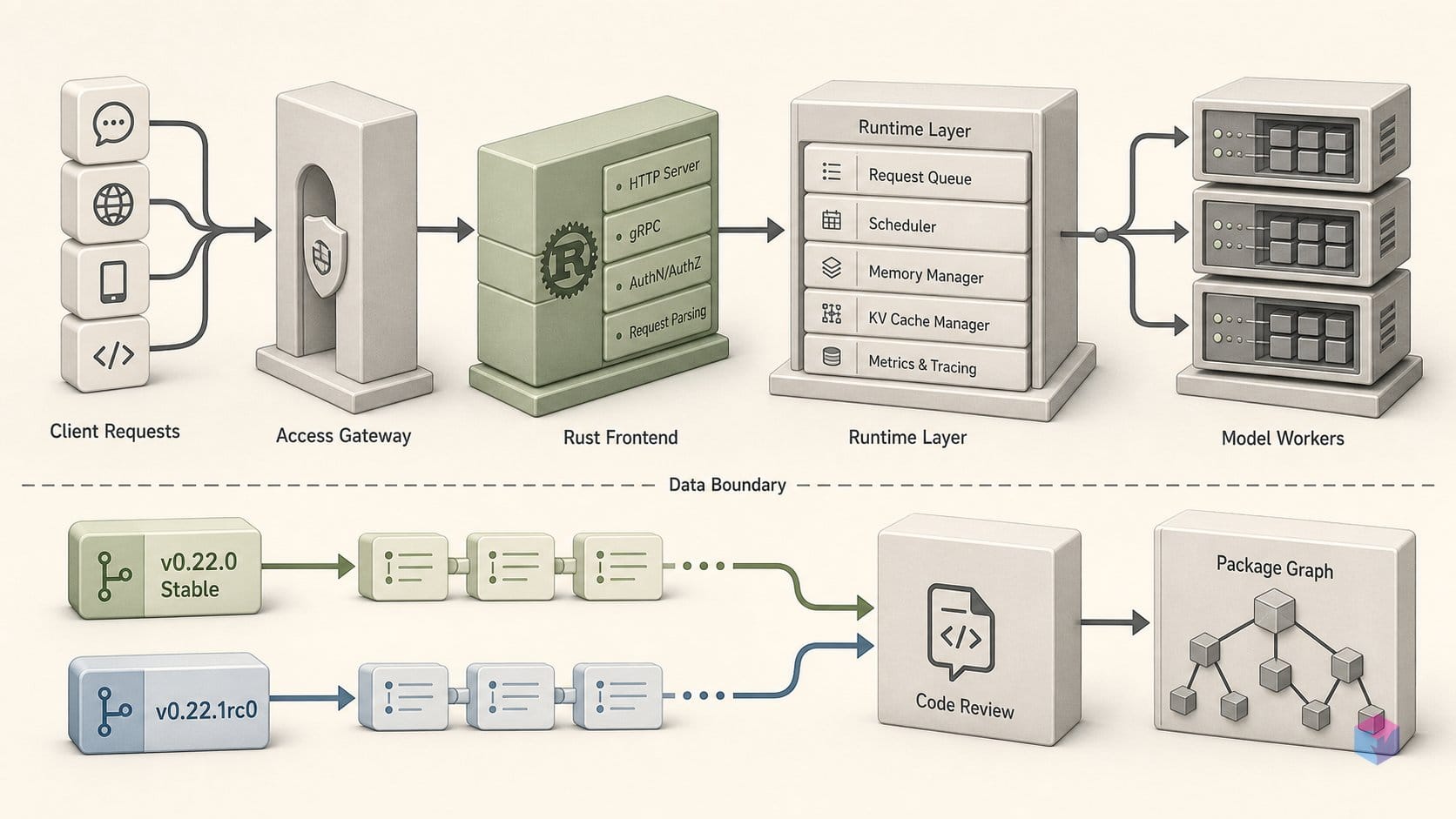
The experimental Rust frontend and Data-Parallel Supervisor are in-tree but explicitly not production-ready in v0.22.0 . The goal is GIL-free request orchestration at higher throughput; the API is unstable with no documented interface for external use. This is infrastructure groundwork for a future release, not a deployable feature today.
v0.22.1rc0: A Single CI Fix, Zero User Impact
The v0.22.1rc0 release contains exactly one change: PR #43971, merged by maintainer njhill on May 29, 2026 . The PR title is also the full release description: "[CI] Make Model Executor test hangs fail fast with a traceback."
The root cause: test_model_loader_download_files hung for approximately 10 hours inside an uninterruptible CUDA region during a nightly build . Buildkite's 35-minute step-level timeout failed to terminate the process because POSIX signals do not reach blocked CUDA threads.
The fix adds two entries to .buildkite/test_areas/model_executor.yaml:
PYTHONFAULTHANDLER=1— dumps Python thread tracebacks on signal, making the hang diagnosable post-mortempytest --timeout=900 --timeout-method=thread— a 15-minute per-test watchdog using thread-based interrupts, which can break out of C/CUDA hangs where signal-based methods cannot
No new package dependencies: pytest-timeout==2.3.1 was already declared in requirements/test/cuda.txt . If you serve inference with vLLM v0.22.0, rc0 has nothing for you. If you contribute to vLLM CI, this is a practical quality-of-life fix for test suites that block on long-running CUDA operations.
Upgrade Checklist: Removed Imports, Dropped Args, and Env Flag Renames

v0.22.0 removes three categories of previously deprecated interfaces . Additive changes — new models, new hardware kernels — require no action. Breaking changes require a codebase check before upgrading to avoid startup failures.
| Change Type | What Changed | Action Before Upgrading |
|---|---|---|
| Import removal | get_tokenizer old import path removed | grep -r "get_tokenizer" . and update to canonical path per release notes |
| Import removal | resolve_hf_chat_template old import path removed | grep -r "resolve_hf_chat_template" . and update to canonical path |
| Argument removal | Deprecated MLA prefill arguments removed | Remove explicit MLA prefill args from serving scripts and harnesses |
| Config migration | Several env vars migrated to backend flags | Consult v0.22.0 release notes for full mapping; validate in staging first |
| New models (additive) | MiniCPM-V 4.6, InternS2 Preview, OpenVLA added | None required |
| Hardware kernels (additive) | Blackwell/SM12x, ROCm parity, RISC-V RVV | None required |
The most likely breakage points in practice: internal tooling or serving harnesses that import from deprecated module paths will throw ImportError at startup. Run the grep commands above before promoting any upgrade. Env-var-to-flag renames are the other common source of silent config drift — validate your startup configuration against the v0.22.0 release notes in a staging environment before rolling to production.
Frequently Asked Questions
Should I upgrade to vLLM v0.22.1rc0 instead of v0.22.0?
No. v0.22.1rc0 contains a single CI test-infrastructure fix — PR #43971 — that has no effect on inference serving or model behavior. Use v0.22.0 for production deployments. Wait for a v0.22.1 GA tag before adopting that patch series; the rc0 is an internal CI quality-of-life improvement, not a user-facing fix. If v0.22.1 never reaches GA (as happened with v0.21.1), v0.22.0 remains the supported stable release.
What is the NVFP4 fused MoE kernel added for DeepSeek V4?
NVFP4 fuses FP4-quantized MoE expert weights into a single GPU kernel, targeting Hopper-class hardware (H100, H200). The benefit over FP8 or FP16 MoE is lower memory bandwidth pressure, which can improve throughput on memory-bound MoE inference. The trade-off is additional quantization error introduced by FP4 precision. Benchmark your task's output quality before switching — the right choice depends on your model's sensitivity to low-precision computation, not just throughput numbers.
Which import paths were removed in vLLM v0.22.0?
The old import locations for get_tokenizer and resolve_hf_chat_template were removed in v0.22.0. Both will cause ImportError at startup if not updated before upgrading. The v0.22.0 release notes list the new canonical paths. Before upgrading any environment, run grep -r "get_tokenizer\|resolve_hf_chat_template" your_project/ to find all affected import sites and update them to the current module locations.
How does the tiered KV cache offloading work in v0.22.0?
The framework manages KV cache blocks across three tiers: hot blocks stay on GPU HBM for lowest-latency access, warm blocks spill to CPU DRAM, and cold blocks are written to a filesystem tier implemented in Python or a Mooncake disk backend. This extends the effective context capacity of a deployment beyond what GPU memory alone can hold. Each tier transition adds latency — block access in CPU DRAM is significantly slower than GPU HBM, and disk-tier access slower still. Profile your actual block access patterns before enabling offloading, and measure whether the extended context capacity justifies the latency trade-off for your workload.
Is the Rust frontend in vLLM v0.22.0 ready to use?
No. The Rust frontend and Data-Parallel Supervisor are explicitly experimental in v0.22.0. The API is unstable, there is no documented interface for external use, and the components are not intended for production workloads in this tag. They represent infrastructure groundwork for GIL-free request orchestration in a future release — useful signal for what the project is building toward, but not a feature you can deploy today.
What to Watch in the v0.22.1 Patch Cycle
As of May 30, 2026, the v0.22.1 branch holds a single cherry-pick with no additional patches announced. The surface areas most likely to generate regression fixes are DeepSeek V4 (recently reorganized codebase, new kernel paths), Cutlass FP8 (new execution path in compile mode), and the MR V2 KV connector compatibility layer. Watch the vLLM releases page for rc1+ tags; if none appear before v0.23.0, the v0.21.1 precedent suggests the patch cycle may be superseded by the next minor release.
Two areas lack independent benchmark data at this time: the Mooncake disk-offload backend and the 28.9% Cutlass FP8 latency figure. Both are worth revisiting once community reproduction numbers surface. The experimental Rust frontend has no stability timeline attached to it — track the vLLM roadmap for any announced stabilization target.
Last updated: 2026-05-30. Article reflects the vLLM v0.22.0 and v0.22.1rc0 releases as tagged on May 29, 2026.






