
Step 3.7 Flash shipped on May 29, 2026 as a structural upgrade to 3.5 Flash: same OpenAI-compatible SDK, new vision encoder, new runtime escalation, and a compute-control flag you can set per request. The migration from 3.5 is two environment variables. One of them has to be exactly right — or every call returns a silent 401.
What 3.7 brings that 3.5 didn't
Step 3.7 Flash adds three net-new capabilities over 3.5 Flash: a native 1.8B-parameter ViT encoder that injects image representations directly into the language backbone without a separate model call , an automatic Advisor Mode that routes failure-prone subtasks to a larger model at runtime, and a reasoning_effort parameter (low / medium / high) as a first-class API flag rather than a prompt-engineering convention. The production-relevance number is variance: 3.5 Flash scores ranged from 43% to 73% across different harnesses ; 3.7 narrows that to 64.5–71.5% , which matters more for production scheduling than the raw score improvement.
Quick Answer: Step 3.7 Flash is an OpenAI-SDK-compatible model — model string step-3.7-flash, base URL https://api.stepfun.ai/v1 (global) or https://api.stepfun.com/v1 (China region). New over 3.5: native vision input, automatic Advisor Mode escalation, and a reasoning_effort flag. The only breaking change from 3.5: base URL must match your account region exactly, or you get a 401 with no error body.
The architecture is a 198B sparse MoE model with roughly 11B parameters active per forward pass — dense-10B compute cost at much larger capacity. SWE-Bench Pro improved to 56.3% from 51.3% ; Terminal-Bench 2.1 improved to 59.5% from 53.4% , suggesting the planning and shell-operation gains that matter for coding agents are consistent across benchmarks.
Advisor Mode carries the headline cost claim from StepFun's internal harness: 97% of Claude Opus 4.6's coding performance at $0.19 vs. $1.76 per task . That's a vendor figure on a first-party SWE-Bench Verified run — treat it as directional until independent replication appears.
| Capability | Step 3.5 Flash | Step 3.7 Flash |
|---|---|---|
| Vision input | External model call | Native 1.8B ViT encoder |
| SWE-Bench Pro | 51.3% | 56.3% |
| Benchmark spread | 43–73% | 64.5–71.5% |
reasoning_effort flag |
Not available | low / medium / high |
| Advisor Mode | No | Automatic (runtime) |
| Context window | — | 256k tokens |
Before you send a request
Two environment variables and the correct regional URL are all that's required. The URL is the part that fails silently — verify it before writing any code.
Account region and base URL. StepFun runs two separate API domains that share no authentication state:
- Global account — register at platform.stepfun.ai; set
STEP_BASE_URL=https://api.stepfun.ai/v1 - China-region account — register at platform.stepfun.com; set
STEP_BASE_URL=https://api.stepfun.com/v1
Export both before running any code:
export STEP_API_KEY="sk-..."
export STEP_BASE_URL="https://api.stepfun.ai/v1" # global account
# China-region: export STEP_BASE_URL="https://api.stepfun.com/v1"
OpenRouter alternative. If you want to skip a StepFun account or consolidate all model routing behind a single proxy, OpenRouter lists Step 3.7 Flash under model ID stepfun/step-3.7-flash. Set base URL to https://openrouter.ai/api/v1 and use your existing OpenRouter key. No StepFun registration required.
NVIDIA NIM. For enterprise GPU inference, NVIDIA's NIM containerized endpoint runs Step 3.7 Flash on Hopper-class GPUs at up to 600 tokens/second , exposes the same OpenAI-compatible interface at http://0.0.0.0:8000/v1, and supports NeMo-based fine-tuning. Requires an NVIDIA enterprise license.
Python dependency: pip install openai. No StepFun-specific SDK or plugin needed.
Chat, image, and effort level: runnable examples
All four steps below use the standard openai Python client without modification. The only constructor differences from a standard OpenAI call are api_key and base_url.
Step 1 — Basic call. The SDK call structure is identical for any OpenAI-compatible Flash endpoint. The snippet below is illustrative (not executed in this context) and demonstrates the structural pattern — the same shape applies to Step 3.7 Flash by substituting your StepFun credentials:
import os
from openai import OpenAI
# Flash is otherwise OpenAI-compatible; the endpoint needs Google's /openai/ path.
client = OpenAI(
api_key=os.environ["GEMINI_API_KEY"],
base_url="https://generativelanguage.googleapis.com/v1beta/openai/",
)
response = client.chat.completions.create(
model="gemini-2.5-flash",
messages=[{"role": "user", "content": "Say hello in five words."}],
)
print(response.choices[0].message.content)
For Step 3.7 Flash, substitute your StepFun credentials in the constructor and set the model string to step-3.7-flash:
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ["STEP_API_KEY"],
base_url=os.environ["STEP_BASE_URL"], # https://api.stepfun.ai/v1
)
completion = client.chat.completions.create(
model="step-3.7-flash",
messages=[{"role": "user", "content": "Explain the actor model of concurrency."}],
)
print(completion.choices[0].message.content)
Step 2 — reasoning_effort. Pass the parameter directly to create() . Use high for complex code review or multi-step planning; use low for extraction, summarization, or rewriting where latency matters more than depth; omit it entirely to default to medium for general-purpose tasks. If you later switch base models, test the parameter explicitly — it may be accepted without error but silently ignored on models that don't support it:
completion = client.chat.completions.create(
model="step-3.7-flash",
reasoning_effort="high", # low | medium | high
messages=[{"role": "user", "content": "Review this code for race conditions: ..."}],
)
Step 3 — Image input. Replace the string content with a content array. Add a text dict and an image_url dict — identical shape to GPT-4o vision calls. The native 1.8B ViT encoder handles the image directly in the language backbone without routing to an external vision model:
completion = client.chat.completions.create(
model="step-3.7-flash",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "List the interactive elements in this UI screenshot."},
{"type": "image_url", "image_url": {"url": "https://example.com/screenshot.png"}}
]
}]
)
Step 4 — Advisor Mode. No parameter required. When the model detects high failure probability on a subtask — repeated errors, complex architectural reasoning — it automatically routes that subtask to a larger model at runtime without any caller intervention. To confirm escalation occurred in a given turn, inspect the response's usage or metadata fields; unexpectedly high per-step token counts relative to your base-model baseline are a reliable indicator. There is no flag in the current public API to force or suppress escalation.
Where it breaks and why
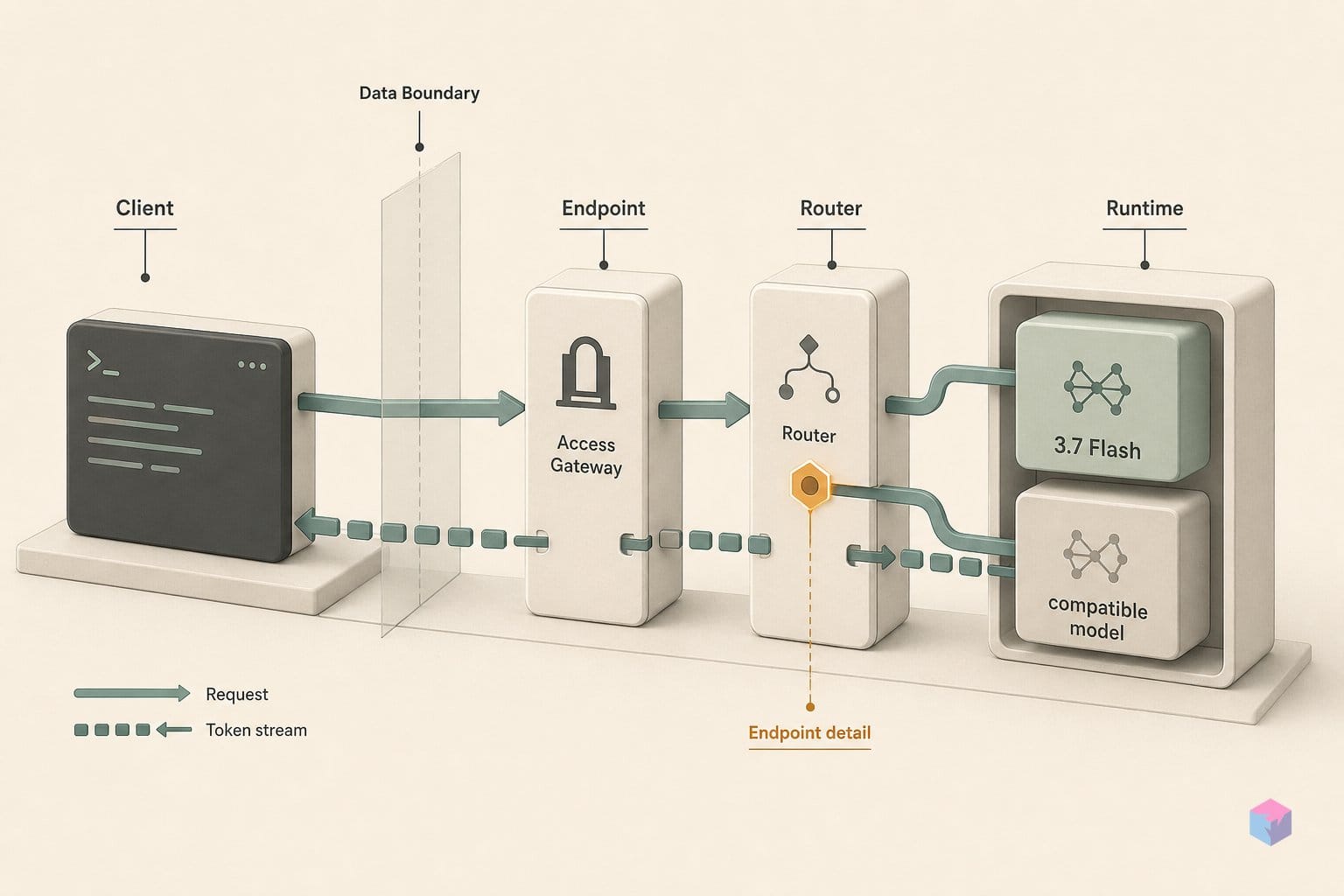
Most Step 3.7 Flash failures trace to one of four predictable sources. None produce descriptive error bodies — you have to know what to check.
- 401 from the wrong domain. The single most common integration failure.
STEP_BASE_URLmust match your account's registration domain exactly: global keys work only againstapi.stepfun.ai/v1; China-region keys work only againstapi.stepfun.com/v1. The 401 response body is empty — no hint about the actual cause. Check the env var before investigating anything else. reasoning_effortsilently ignored. If the model string has a typo or uses an undocumented alias, the parameter may be accepted with HTTP 200 but have no effect. The only confirmed model string isstep-3.7-flashexactly — no version aliases are currently documented in the official API reference . Verify the string before debugging effort-parameter behavior.- Single-run benchmark scores are noise. The 7-percentage-point spread (64.5–71.5%) means one eval run can look 7 points better or worse than the actual baseline. Run at least 5 passes on your task distribution before making a production decision based on a benchmark number.
- Advisor Mode cost figures are first-party only. The $0.19 vs. $1.76 per-task comparison against Claude Opus 4.6 comes from StepFun's own SWE-Bench Verified harness. No independent replication has been published as of May 29, 2026. Don't anchor infrastructure cost projections to this number until third-party results exist.
What to explore once it's working
Once the basic call runs, four experiments will give you grounded data on whether Step 3.7 Flash fits your actual workload rather than StepFun's harness.
- Measure
reasoning_efforttradeoffs on your own task distribution. Run a representative sample atlow,medium, andhigh, and record latency, cost, and quality score for each tier. The optimal setting is workload-specific — the vendor benchmarks don't answer this for your data. - Test native ViT grounding on layout-sensitive tasks. Send a UI screenshot or a chart alongside a structured extraction prompt. The native 1.8B ViT encoder should outperform a tool-chained vision call on tasks where spatial layout matters — form parsing, diagram annotation, UI diffing. Measure it on your actual data; this is a testable, falsifiable claim.
- Instrument Advisor Mode over a 10+ step agentic loop. Log per-step costs across a full run and compare total cost against a single-model baseline at
reasoning_effort=high. The auto-escalation cost delta is invisible on a single call; it becomes meaningful at the loop level. - Head-to-head against DeepSeek V4 Flash on your eval set. ClawEval-1.1 shows a 9-point tool-calling robustness gap: 67.1% for Step 3.7 vs. 57.8% for DeepSeek V4 Flash . Domain-specific results vary considerably — run the comparison on your own task set before committing to either model for production tool-calling workloads.
Frequently Asked Questions
Why does my Step 3.7 Flash request return a 401 error?
Endpoint region mismatch. Keys issued from platform.stepfun.ai (global) only authenticate against api.stepfun.ai/v1. Keys from the China-region platform only work with api.stepfun.com/v1. The 401 response body is empty — there is no hint in the error itself about the cause. Fix: confirm STEP_BASE_URL exactly matches the domain where you registered your account before investigating anything else in your request chain.
Is Step 3.7 Flash a true drop-in for the OpenAI API?
Structurally yes. The same openai Python client, the same messages array shape, and the same image_url content format all carry over without modification. Three things differ from a plain OpenAI call: the model string (step-3.7-flash instead of a GPT variant), the base URL (your regional StepFun endpoint), and reasoning_effort semantics — OpenAI's o-series uses it as a reasoning-chain depth hint, while Step 3.7 Flash uses it as a direct compute-allocation tier that controls inference cost and speed.
Do I have to configure Advisor Mode, or is it automatic?
Automatic. No API parameter enables, disables, or triggers it. The model identifies subtasks it predicts will fail — recovering from repeated errors, deep architectural planning steps — and routes them to a larger model at runtime without any caller-side configuration. StepFun's own SWE-Bench Verified harness reports this blended approach reaches 97% of Claude Opus 4.6's coding performance at $0.19 vs. $1.76 per task . Independent replication of that figure has not been published as of the time of writing.
Can I use Step 3.7 Flash for video as well as images?
The ViT architecture is described as video-capable in StepFun's materials, but video input via the public API should be verified against current platform API documentation before building on it. Static image_url objects in the messages content array are confirmed working today via the native encoder. Don't assume video parity from the architecture description alone — check the current API reference first.
How does Step 3.7 Flash compare in price to similar models?
Input tokens cost $0.20/M tokens (cache miss) and $0.04/M tokens (cache hit); output is $1.15/M tokens as of May 2026 . For agentic workflows, the more meaningful unit is per-task cost: StepFun claims $0.19 per task with Advisor Mode enabled vs. $1.76 for Claude Opus 4.6 alone . Compare to DeepSeek V4 Flash and similar sparse-MoE models at the task level rather than the token level — actual token consumption per task varies widely with prompt length, context reuse, and workflow structure.
The one endpoint detail that's not a drop-in
The migration from Step 3.5 Flash is mechanical: one model string, one env var, and you get vision input, Advisor Mode, and reasoning_effort without any other code changes. The SDK, the message shape, and the image format are identical to what you already use.
The only non-drop-in detail is the regional base URL. It produces a silent 401, it has no descriptive error, and it catches most developers on first integration. Set STEP_BASE_URL to match the domain where you registered, confirm the model string is exactly step-3.7-flash, and the rest of the call works as written. Track independent benchmark results as they emerge at Benchable and monitor API parameter additions via the official GitHub repository as the API stabilizes.
Last updated: 2026-06-01. Reflects Step 3.7 Flash as released May 29, 2026 . Benchmark claims are vendor-reported unless otherwise noted; Advisor Mode cost figures are from StepFun's internal harness and have not been independently replicated as of this date.




