
What SIA Does, and Why Removing the Human Loop Matters
SIA (Self-Improving AI) is a closed-loop agent framework released by Hexo Labs on May 26, 2026 that autonomously edits both its own execution scaffold and fine-tunes model weights — without a human approval gate between iterations. The accompanying preprint (arXiv:2605.27276) frames the core problem plainly: in every existing AI improvement cycle, a human expert decides what to change next. SIA replaces that step with a learned Feedback-Agent that selects, applies, and evaluates its own modifications.
Quick Answer: SIA is a self-improving agent framework from Hexo Labs (arXiv:2605.27276, May 2026) that autonomously modifies both its execution scaffold and model weights via LoRA rank-32 fine-tuning. On LawBench, it reached 70.1% accuracy versus a prior SOTA of 45.0%. On GPU kernel optimization, scaffold-only edits produced a 10.7× regression; weight fine-tuning recovered and improved performance by 12.4% over prior SOTA.
The system runs in two modes. SIA-H modifies the harness — system prompt, tool-dispatch logic, retry policies, and answer-extraction code — while keeping weights frozen. SIA-W+H layers LoRA rank-32 fine-tuning on top, applied to gpt-oss-120b, a 120B-parameter instruction-tuned model . Both modes are evaluated across three domains: 191-class legal classification (LawBench), GPU kernel runtime minimization (AlphaEvolve TriMul), and single-cell RNA sequencing denoising (MAGIC scRNA-seq). In all three, SIA-W+H surpasses the prior state of the art .
What separates SIA architecturally from prior self-improving agent work is that the choice between scaffold editing and weight training is itself dynamic. The Feedback-Agent selects from six reinforcement learning algorithms based on the current reward landscape — not a fixed policy. The authors, led by Kunal Bhatia and Prannay Hebbar at Hexo Labs, frame this as the first system to unify the two self-improvement paradigms under a single adaptive loop . Whether that holds up to independent replication is addressed further below.
From Task Spec to Trained Weights: How the Loop Runs
SIA's execution loop has three distinct agent roles with defined responsibility boundaries. The Meta-Agent (ℳ) bootstraps the system: given a task specification and reference implementations, it generates the initial harness — system prompt, tool-dispatch logic, retry policies, and answer-extraction code. ℳ runs once at domain initialization and is not involved in subsequent iterations .
The Task-Specific Agent (Aₘ) executes against an evaluation dataset 𝒟. Every call, tool invocation, intermediate output, and final answer is logged into a full execution trajectory τ. Aₘ is built on gpt-oss-120b and has four modifiable sub-components: LLM weights θ, system prompt, tool-dispatch logic, and answer-extraction code. The trajectory τ is the raw material the Feedback-Agent uses to diagnose what broke and why .
The Feedback-Agent (ℱ) is the system's decision core. It receives τ and makes exactly one decision per iteration: edit the harness, or trigger LoRA weight training. If harness edits are chosen, ℱ rewrites one or more harness components and immediately re-runs Aₘ with the updated scaffold. If weight training is triggered, ℱ selects the appropriate RL algorithm, constructs a training batch from τ, fine-tunes gpt-oss-120b via LoRA rank 32, and feeds the updated weights into the next Aₘ run . No human step exists between iteration N and iteration N+1 in either path.
This structure matters for how to think about the system's failure modes. Prior self-improving agent systems automated either scaffold editing (DSPy-style optimizers) or fine-tuning pipelines — but not both within a unified loop with a learned selection policy. The trajectory-based feedback means every decision ℱ makes is grounded in the actual execution record, not a high-level accuracy summary. The authors argue this enables more targeted interventions than aggregate-score-based approaches . The main thing the paper doesn't clarify is the compute cost of ℱ itself — whether it's a prompted base model or something pre-trained, which affects reproducibility. That's addressed in the portability section.
Harness vs. Weight Updates: Two Different Levels of Self-Modification
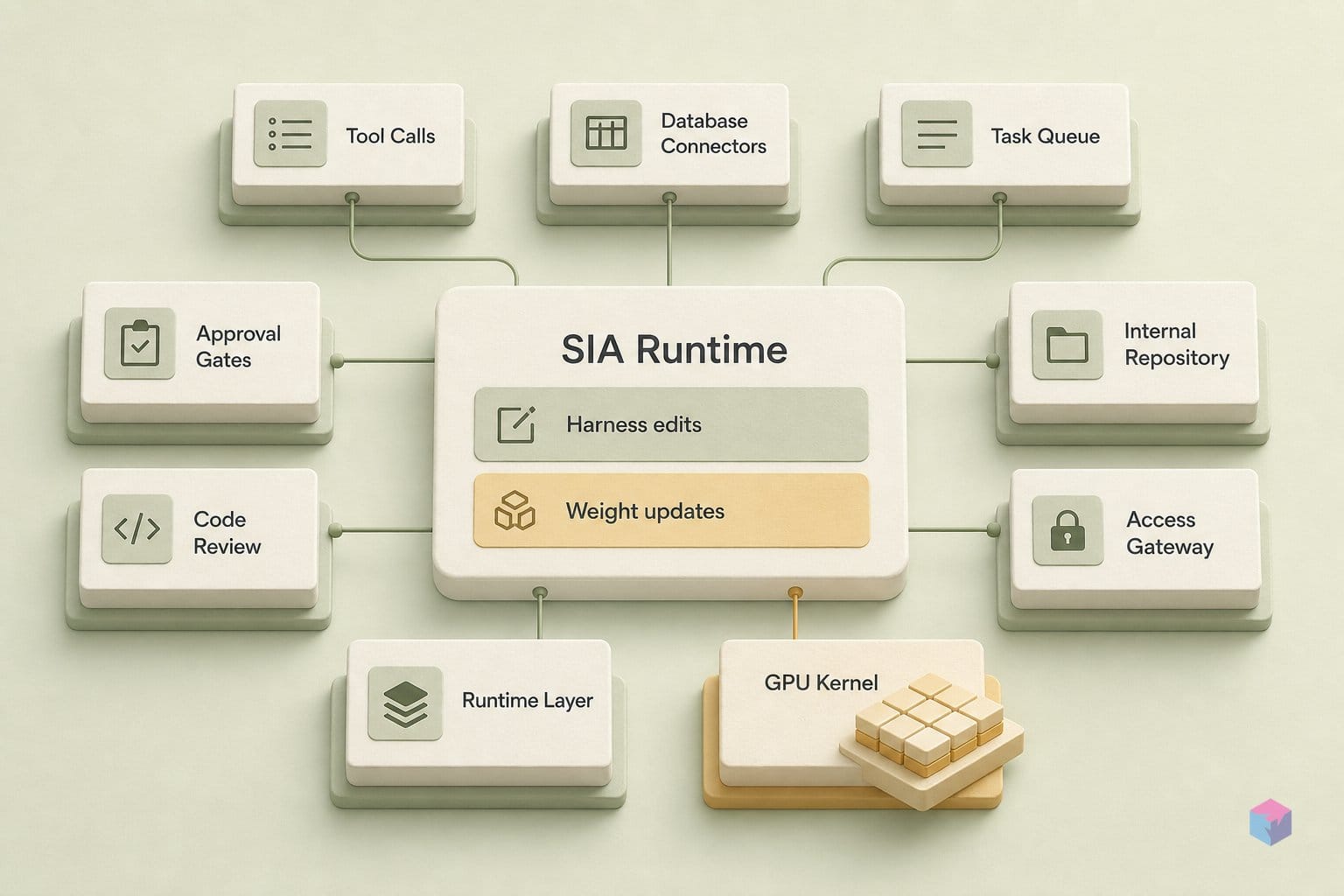
The distinction between modifying the harness and modifying model weights determines what class of errors each mode can fix — not just how fast each mode runs. Harness components (system prompt, tool-dispatch logic, retry policies, answer-extraction code) are software artifacts. Modifying them is fast, costs zero GPU time, and can meaningfully improve performance when the agent's failure mode is routing errors, malformed outputs, or suboptimal tool selection. What they cannot do is change what the underlying model knows at the weight level .
Weight training via LoRA rank 32 targets a different problem class: knowledge the model does not have and cannot acquire through prompt rewriting. H100-specific GPU kernel numerical patterns, fine-grained legal category boundaries across 191 classes , domain-specific statistical distributions in single-cell RNA data — these require weight-level internalization. The paper's clearest evidence for this is the GPU kernel result: harness edits alone worsened performance from 1,161 μs to 12,483 μs, while weight training recovered and improved to 1,017 μs .
| Dimension | SIA-H (Harness Only) | SIA-W+H (Harness + Weights) |
|---|---|---|
| Edit cost | Near-zero GPU cost; fast iteration | LoRA rank-32 fine-tuning on H100; higher cost per cycle |
| Iteration speed | Sub-minute per cycle | Minutes to hours per fine-tuning run (GPU-dependent) |
| Performance ceiling | Bounded by model's existing knowledge; cannot encode new domain patterns | Internalizes domain-specific patterns via weight updates; ceiling shifts each cycle |
| LawBench vs. prior SOTA (45.0%) | 50.0% (+5.0 pp) | 70.1% (+25.1 pp) |
| AlphaEvolve TriMul vs. prior SOTA (1,161 μs) | 12,483 μs (−10.7× regression) | 1,017 μs (+12.4% improvement) |
| MAGIC scRNA-seq vs. prior SOTA (0.240) | 0.241 (+0.4%) | 0.289 (+20.4%) |
| Best fit for | Tasks where failures are routing, formatting, or tool-selection errors | Tasks requiring domain knowledge internalization or sub-symbolic pattern encoding |
The Feedback-Agent decides which mode to trigger based on the reward signal trend across iterations. If harness edits produce diminishing returns — reward improvement plateaus or inverts — ℱ switches to weight training. This dynamic selection is the mechanism that prevents SIA-H's ceiling from becoming the system's ceiling. The practical implication: SIA-H is not a cost-cutting substitute for SIA-W+H; it's an appropriate tool for a specific (and bounded) problem class .
Six RL Algorithms, Dynamically Selected: The Feedback Module's Decision Logic
When ℱ determines that weight training is warranted, it does not default to a fixed algorithm. It selects from a pool of six reinforcement learning methods based on four characteristics of the current reward landscape: reward density (how often the agent receives non-zero signal), rollout cost (compute per trajectory sample), pass-rate distribution (whether successes cluster or spread uniformly), and regression risk (likelihood of overwriting prior gains) .
The six algorithms and their target conditions:
- PPO with GAE: Used for dense multi-step reward signals where intermediate actions receive credit. Standard for high-frequency feedback environments.
- GRPO: Targets cheap rollout regimes with episode-end verification — reward is assigned only at end-of-trajectory. Well-suited to legal classification, where answer correctness is the single verifiable signal.
- Entropic Advantage Weighting: Applied when reward distributions are right-skewed — most runs fail, a small fraction succeed. Rather than discarding low-reward samples, EAW extracts signal from near-successes via entropy-weighted advantages.
- REINFORCE+KL: Dense reward settings with high regression risk. The KL penalty prevents the updated policy from drifting far from the base model, protecting gains from prior iterations.
- Best-of-N Behavioral Cloning: A cold-start mechanism for sparse reward settings where RL gradient estimates are too noisy. Supervised BC on the top-N trajectories provides a stable initial signal.
- DPO (Direct Preference Optimization): Used when outputs are rankable but not cardinally scored — the system can express preferences between two outputs without assigning a numeric reward to either.
The motivation for this taxonomy is that the reward landscape for a 191-class legal classification task is structurally different from a GPU kernel runtime minimization task. Legal accuracy has a different noise shape, convergence rate, and failure mode distribution than a continuous latency metric. Static RL pipelines commit to one algorithm at setup time, which is appropriate if your task is fixed. SIA's dynamic selection is the paper's argument that a fixed RL recipe is insufficient for a general-purpose self-improvement framework that operates across domains .
One gap worth flagging for practitioners: the paper does not publish ℱ's exact decision function for algorithm selection . The algorithm taxonomy is documented, but the mapping from reward landscape features to algorithm choice is not specified in enough detail to reproduce ℱ independently. For teams building domain-specific agents where the task type varies over time — a coding assistant handling both documentation generation and runtime optimization, for instance — the algorithm taxonomy is still a useful design checklist, even if the selection logic itself requires the codebase to replicate.
The GPU Kernel Regression: Why Scaffold Edits Alone Made Things 10× Worse
The AlphaEvolve TriMul benchmark measures GPU kernel runtime in microseconds — lower is better. The prior state of the art was 1,161 μs . SIA-H, applying harness modifications only, produced 12,483 μs — a 10.7× regression . This is the paper's most diagnostic result, and it deserves more attention than the headline LawBench numbers.
GPU kernel optimization for H100 hardware requires encoding sub-symbolic numerical patterns: memory access coalescing strategies, warp-level synchronization timing, tensor core utilization schedules. These are not expressible as natural language reasoning in a system prompt — and they are not learnable by changing how tools are dispatched or answers are extracted. When SIA-H's Feedback-Agent rewrote the harness in response to poor kernel performance, it injected prompt-level reasoning about optimization that the model then acted on in ways that actively disrupted kernel structure. The harness edits compounded the error rather than correcting it .
SIA-W+H reached 1,017 μs — 12.4% faster than the prior SOTA and approximately 12.3× better than SIA-H's regressed output . The LoRA fine-tuning pass internalized H100-specific kernel generation patterns that the base gpt-oss-120b checkpoint did not carry and that no prompt could transfer. This is the key empirical boundary the paper draws: for low-level systems optimization, scaffold editing without weight training has a hard ceiling — and in some configurations, a negative floor.
"Today's AI systems are powerful but share a fundamental limitation: every meaningful leap still depends on intervention of human experts to decide what to try next." — Kunal Bhatia, CEO and Co-founder at Hexo Labs
The practical implication is sharp. If you're evaluating whether SIA-H alone is sufficient for your use case, the GPU kernel result is the boundary condition to calibrate against. Tasks involving sub-symbolic pattern encoding — numerical optimization, low-level code generation, hardware-specific inference — are where harness-only approaches break down. Tasks primarily involving routing, formatting, or high-level reasoning are where SIA-H's cheaper iteration cycle makes sense. The regression was not a bug in the implementation; it's the system accurately revealing the limits of one approach when applied to a mismatched task class.
LawBench 70.1% and scRNA-seq: What the Law and Biology Results Tell Us
Across the two non-systems benchmarks, SIA-W+H produced consistent, large gains over both prior SOTA and its own harness-only baseline. LawBench is a 191-class Chinese legal classification task where prior SOTA was 45.0%. SIA-H moved that to 50.0% (+5.0 pp) — real, but modest. SIA-W+H reached 70.1% , a +25.1 pp improvement over prior SOTA and +20.1 pp over SIA-H alone. Legal category boundaries at 191-class granularity are difficult to specify via prompt; LoRA fine-tuning on domain examples can encode those distinctions at the weight level in a way that instruction changes cannot.
MAGIC scRNA-seq shows a slightly different pattern. Prior SOTA on mse_norm was 0.240 ; SIA-H reached 0.241 (+0.4%), and SIA-W+H reached 0.289 (+20.4% over prior SOTA). The harness-only gain is non-zero but negligible. Unlike the GPU kernel task, SIA-H did not regress performance — the floor is above zero — but the headroom exists almost entirely at the weight level. The biology domain sits between the law result (large harness gain, enormous weight gain) and the GPU result (negative harness impact, large weight gain) on this spectrum.
| Benchmark | Metric | Prior SOTA | SIA-H | SIA-W+H | Δ vs. Prior SOTA | Δ SIA-H → SIA-W+H |
|---|---|---|---|---|---|---|
| LawBench (191-class legal classification) | Accuracy ↑ | 45.0% | 50.0% | 70.1% | +25.1 pp | +20.1 pp |
| AlphaEvolve TriMul (GPU kernel) | Runtime μs ↓ | 1,161 μs | 12,483 μs | 1,017 μs | −12.4% (improvement) | −11,466 μs (full recovery + gain) |
| MAGIC scRNA-seq denoising | mse_norm ↑ | 0.240 | 0.241 | 0.289 | +20.4% | +19.9% |
The cross-domain pattern is consistent: SIA-W+H materially outperforms SIA-H in every tested setting, and the gap magnitude tracks with how much of the task depends on sub-symbolic knowledge encoding. The table above makes one result visible that headline reading misses: SIA-H's +5.0 pp on LawBench is real, but SIA-W+H sits 20.1 pp further ahead. Harness-only is not a reasonable stopping point if weight training infrastructure is accessible — treating it as such would leave most of SIA's available headroom unrealized .
Fact-Checking SIA: MIT License, Missing GitHub URL, and the 350X Claim
Before building on SIA's results, three claims warrant independent verification. First, licensing: the paper carries a CC BY-SA 4.0 license and the codebase is reported MIT-licensed . As of May 31, 2026, no confirmed public GitHub repository URL appears in the arXiv:2605.27276 abstract page, the paper PDF, or any coverage reviewed for this article. The code may be published imminently, or it may not yet be publicly accessible. Watch the arXiv abstract page and Hexo Labs' GitHub organization directly.
Second, the "350X acceleration" claim. Hexo Labs' PR materials reference a 350X performance improvement on a proprietary benchmark described as designed by OpenAI . This figure does not appear in the paper. There is no independent replication, no public leaderboard entry, and no methodology described that would allow verification. Set this aside until a reproducible evaluation is published.
Third, academic partnerships. Hexo Labs lists Stanford University, University of Oxford, and UC Santa Barbara in PR materials . Verify author affiliations via arXiv author IDs and institutional faculty pages before citing these as formal research collaborations rather than individual author connections. The benchmarks themselves — LawBench, AlphaEvolve TriMul, MAGIC scRNA-seq — are independently established evaluation sets, which at minimum grounds the performance numbers in verifiable tasks even if the partnership claims require independent confirmation.
Portability and Limitations: Can You Replicate SIA Without gpt-oss-120b?
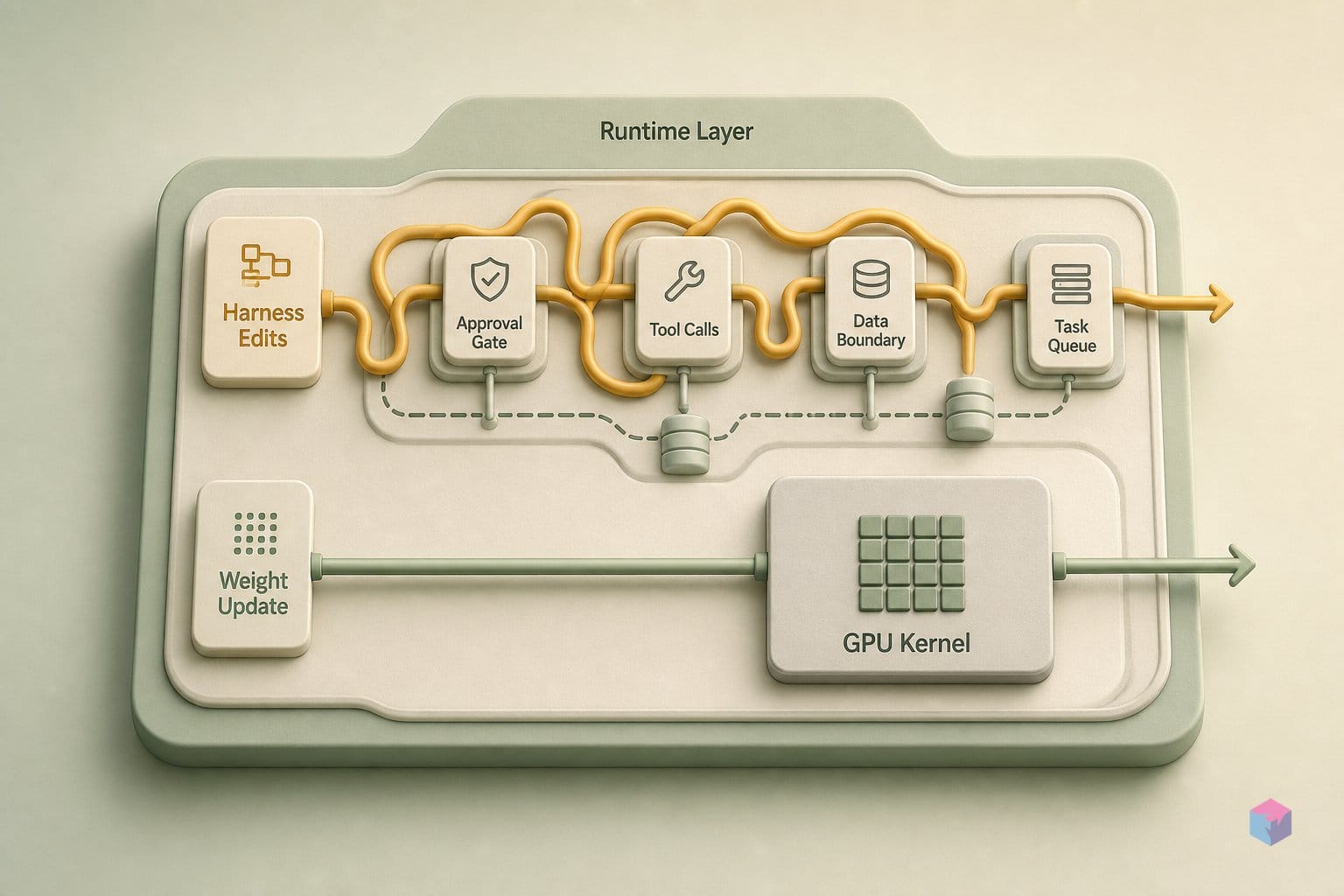
The harness-editing half of SIA is model-agnostic. Any model with a tool-dispatch interface — Claude Sonnet, GPT-4o, Mistral-based deployments — can substitute as Aₘ for the scaffold-editing loop. ℱ's harness rewriting does not depend on a specific underlying model checkpoint. This makes SIA-H immediately portable for practitioners who want automated prompt and tool-routing optimization without fine-tuning infrastructure . The GPU kernel result remains the warning: for tasks with sub-symbolic knowledge requirements, harness-only SIA is not just limited — it actively regressed performance. Portability of SIA-H is real; portability of SIA-H's performance ceiling is also real.
The weight-training path is harder to replicate. gpt-oss-120b is a 120B-parameter instruction-tuned model; the paper does not specify its access path, whether it's a public checkpoint, or whether it's an internal Hexo Labs artifact. LoRA rank-32 fine-tuning is a well-established technique supported across major model families via tools like the Hugging Face PEFT library, which makes the methodology itself portable once the base model question is resolved (video: Angel Poon). For a 120B model, expect multi-GPU requirements; rank-32 LoRA on models in the 7B–70B range is tractable on a single H100, but larger scales require correspondingly more infrastructure. Substituting an accessible 120B-class instruction-tuned open-weights model should make the weight-update methodology reproducible once the repository is confirmed public .
Key unknowns blocking full replication today:
- gpt-oss-120b access and licensing: Not clarified in the paper. May be an internal checkpoint; may be a renamed public model. No replication of SIA-W+H is possible until this is resolved.
- ℱ pre-training requirements: The paper does not state whether the Feedback-Agent requires domain-specific pre-training or can operate from a prompted base model. This determines how much bootstrapping a new deployment requires.
- Compute cost per self-improvement cycle: Per-iteration fine-tuning cost is not reported. Essential for any cost-benefit analysis of deploying SIA in production.
- Goodhart co-evolution risk: The authors explicitly identify this — both optimization levers target the same fixed verifier, creating a path toward fixed points that score well on the training distribution but are fragile to perturbation . Proposed mitigations (meta-RL over the selection policy, interleaved training-harness switching) are left as future work.
Frequently Asked Questions
What is SIA and who built it?
SIA (Self-Improving AI) is an open-source agent framework released by Hexo Labs on May 26, 2026 (arXiv:2605.27276) . It autonomously edits its own execution scaffold — system prompt, tool dispatch, retry logic, answer extraction — and fine-tunes model weights via LoRA, removing humans from the self-improvement loop entirely. The paper's authors include Prannay Hebbar, Yogendra Manawat, Samuel Verboomen, Alesia Ivanova, Selvam Palanimalai, Kunal Bhatia, and Vignesh Baskaran, with Hexo Labs describing itself as a research organization targeting superintelligence.
What is the difference between SIA-H and SIA-W+H?
SIA-H modifies only the harness — system prompt, tool dispatch, retry logic, and answer extraction — while keeping gpt-oss-120b weights frozen. SIA-W+H additionally applies LoRA rank-32 fine-tuning to the underlying 120B-parameter model. The combined mode outperforms harness-only across all three evaluated benchmarks. On AlphaEvolve TriMul (GPU kernel), the gap is extreme: SIA-H regressed from 1,161 μs to 12,483 μs while SIA-W+H improved to 1,017 μs — a 10.7× difference in favor of weight training, not harness editing.
Why did SIA-H make GPU kernel performance worse, not better?
H100-specific GPU kernel optimization requires encoding sub-symbolic numerical patterns — memory coalescing strategies, warp synchronization, tensor core scheduling — that cannot be expressed in natural language prompts. When SIA-H's Feedback-Agent rewrote the harness to address poor kernel performance, it introduced prompt-level reasoning that actively misled the model's code generation. SIA-H regressed AlphaEvolve TriMul from 1,161 μs to 12,483 μs . SIA-W+H recovered to 1,017 μs by internalizing those patterns via LoRA fine-tuning, improving 12.4% over prior SOTA. The regression demonstrates a hard ceiling — and an active floor hazard — for scaffold-only optimization on low-level systems tasks.
Is SIA's source code publicly available on GitHub?
The paper carries a CC BY-SA 4.0 license and the codebase is reported MIT-licensed, but as of May 31, 2026, no confirmed public GitHub repository URL appears in the arXiv abstract page for arXiv:2605.27276, in the paper PDF, or in coverage reviewed for this article. Watch the arXiv abstract page and Hexo Labs' GitHub organization for a confirmed code link before planning a replication effort. The licensing claim cannot be independently verified until a repository is accessible.
Can SIA's approach work with models other than gpt-oss-120b?
The harness-editing approach is model-agnostic — Claude, GPT-4o, or any model with a tool-dispatch interface can substitute as the Task-Specific Agent for SIA-H. LoRA rank-32 fine-tuning is a standard, well-supported technique portable to most model families. The main blocker for SIA-W+H replication is gpt-oss-120b's unclear access path. Once the repository is confirmed public and the base model's licensing is clarified, substituting a comparable open-weights 120B-class instruction-tuned model should make full replication feasible — though compute requirements at 120B scale will differ from smaller alternatives.
Decision Framework and What to Watch
SIA's empirical record across three domains gives practitioners a defensible heuristic for when each mode applies. If your task involves high-level reasoning, output formatting, or tool selection — and the model already has relevant domain knowledge — SIA-H's cheap, fast iteration cycle is a credible starting point. If your task involves low-level systems optimization, fine-grained multi-class classification, or statistical patterns not present in standard pre-training, SIA-H alone will not be sufficient and may degrade performance. SIA-W+H consistently outperforms across all tested settings; the trade-off is higher per-cycle compute cost that the paper does not yet quantify.
The dynamic RL algorithm selection is the component with the most transferable value for teams already running fine-tuning pipelines. The six-algorithm taxonomy — PPO with GAE, GRPO, Entropic Advantage Weighting, REINFORCE+KL, Best-of-N BC, DPO — covers most training scenarios that appear in LLM fine-tuning practice. The conceptual framework for mapping reward landscape characteristics to algorithm choice is immediately applicable to pipeline design, even without the full SIA codebase. This is the paper's most actionable contribution for practitioners who are not ready to deploy the full system.
Three concrete things to watch before committing to SIA for production use: first, the GitHub repository link on arXiv:2605.27276 — when it appears, it confirms the code is accessible and the MIT license claim is verifiable; second, clarification of gpt-oss-120b's access path, which determines whether the full SIA-W+H pipeline is directly replicable or requires model substitution; third, any independent replication of the LawBench 70.1% result, which would confirm the benchmark is not contaminated by training-set overlap. The 350X claim from PR materials should remain set aside until a public evaluation methodology and reproducible benchmark are provided.
Last updated: 2026-05-31. Based on arXiv:2605.27276 v2 (May 28, 2026) and coverage available as of the publication date. Repository access, model licensing details, and benchmark replications may change as Hexo Labs updates the release.




