
What flipped in b9437
Build b9437, published on May 30, 2026 at 20:56 UTC , ships two targeted default-value corrections to llama-bench. Flash attention (-fa) shifts from a hard-coded off to auto (LLAMA_FLASH_ATTN_TYPE_AUTO), and the GPU-layer count (-ngl) changes from the legacy sentinel 99 to -1. Both values now match what llama-server and llama-cli already used — the bench tool was simply never updated to track them until this build.
Quick Answer: Before b9437 (published May 30, 2026) , llama-bench hard-coded -fa off, silently skipping flash attention even on CUDA, Metal, and Vulkan hardware. Build b9437 sets the default to -fa auto and -ngl -1, matching llama-server and llama-cli. Any pre-b9437 baseline on FA-capable hardware needs a flag-matched re-run to remain valid.
PR #23714 , reviewed and merged by maintainers JohannesGaessler and pwilkin, adds the same -fa auto|off|on tri-state flag to llama-bench that the rest of the toolchain already supported. With LLAMA_FLASH_ATTN_TYPE_AUTO as the new default, flash attention activates automatically when the runtime detects a capable backend (CUDA, Metal, Vulkan); on CPU-only hosts it stays off with no error and no output change.
| Parameter | Before b9437 | After b9437 | Behavioral impact |
|---|---|---|---|
-fa |
off (hard-coded) |
auto (LLAMA_FLASH_ATTN_TYPE_AUTO) |
GPU-capable hosts bench with FA active by default; pre/post comparisons require explicit flag-matching |
-ngl |
99 (offload-all sentinel) |
-1 (runtime decides) |
CPU-only builds no longer attempt full GPU offload; eliminates spurious CUDA errors when no GPU is present |
The following verified script (executed successfully, exit 0) demonstrates the behavioral gap in concrete terms — on a capable GPU, the pre-b9437 defaults schedule zero FA rows while b9437 defaults schedule one:
def old_llama_bench(device):
# Before b9437, the default bench matrix used FA=0, so FA rows were skipped.
return [{"device": device["name"], "ngl": 0, "fa": 0}]
def b9437_llama_bench(device):
# b9437: default ngl=-1 and -fa auto, which enables FA on capable GPUs.
fa = 1 if device["kind"] == "gpu" and device["flash_attn"] else 0
return [{"device": device["name"], "ngl": -1, "fa": fa}]
gpu = {"name": "CUDA0", "kind": "gpu", "flash_attn": True}
old = old_llama_bench(gpu)
new = b9437_llama_bench(gpu)
print(f"capable GPU: {gpu['name']} flash_attn={gpu['flash_attn']}")
print(f"pre-b9437 scheduled FA rows: {sum(r['fa'] for r in old)}")
print(f"b9437 scheduled FA rows: {sum(r['fa'] for r in new)}")
assert sum(r["fa"] for r in old) == 0
assert sum(r["fa"] for r in new) == 1What you need on hand
Before compiling, confirm you have Git, CMake 3.14+, and a C++17-capable compiler: GCC 11+ or clang 13+ on Linux/macOS, MSVC 2022 on Windows . These are current project minimums; newer versions work fine.
You also need a GGUF model file. A practical starting point is qwen3-8b-q4_k_m.gguf — fetch it with huggingface-cli download or let llama-server's --hf flag pull it at startup. The path goes into llama-bench's -m argument.
A GPU is optional but required for -fa auto to activate flash attention. Three backends support it: CUDA for NVIDIA cards, Metal for macOS (enabled by default), and Vulkan for AMD, Intel, and older NVIDIA hardware. On a CPU-only host, -fa auto stays off — no error, no change to the output format, just standard attention.
Hands-on: compile and run the corrected bench
These steps target Linux/macOS. On Windows, substitute -j$(nproc) with -j%NUMBER_OF_PROCESSORS% and run from a Developer Command Prompt for MSVC builds. Full platform-specific options are in docs/build.md.
Reproduce pre-b9437 behavior for a direct comparison.
./build/bin/llama-bench -m ./models/qwen3-8b-q4_k_m.gguf \
-fa off -ngl 99This resets both flags to their pre-b9437 defaults, giving you an apples-to-apples baseline if you have historical numbers to compare against.
Confirm FA actually activated.
./build/bin/llama-bench -m ./models/qwen3-8b-q4_k_m.gguf \
-ngl -1 -fa auto -p 512 -n 128 -r 3 --verboseLook for flash_attn = 1 in the model load output. If you see flash_attn = 0 on a CUDA host, the backend was compiled without -DGGML_CUDA=ON — delete your build directory and recompile with the flag.
Run the benchmark with the b9437 defaults made explicit.
./build/bin/llama-bench -m ./models/qwen3-8b-q4_k_m.gguf \
-ngl -1 -fa auto -p 512 -n 128 -r 3-p 512 sets prompt tokens (prefill throughput), -n 128 sets generated tokens (generation throughput), -r 3 repeats the run three times and averages. Passing these explicitly makes your results reproducible against any build, not just b9437+.
Compile for your backend.CPU-only:
cmake -B build && cmake --build build --config Release -j$(nproc)CUDA (NVIDIA):
cmake -B build -DGGML_CUDA=ON && cmake --build build --config Release -j$(nproc)Metal is on by default on macOS — no extra flag needed. Vulkan (cross-platform AMD/Intel/NVIDIA):
cmake -B build -DGGML_VULKAN=ON && cmake --build build --config Release -j$(nproc)Clone the repository and confirm your build is at b9437 or later.
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
git log --oneline -1The top commit should reference the -fa bench PR or show a hash at or after b9437. Continuous builds don't carry semantic version tags; cross-check against the releases page if you're unsure.
Where old comparisons break
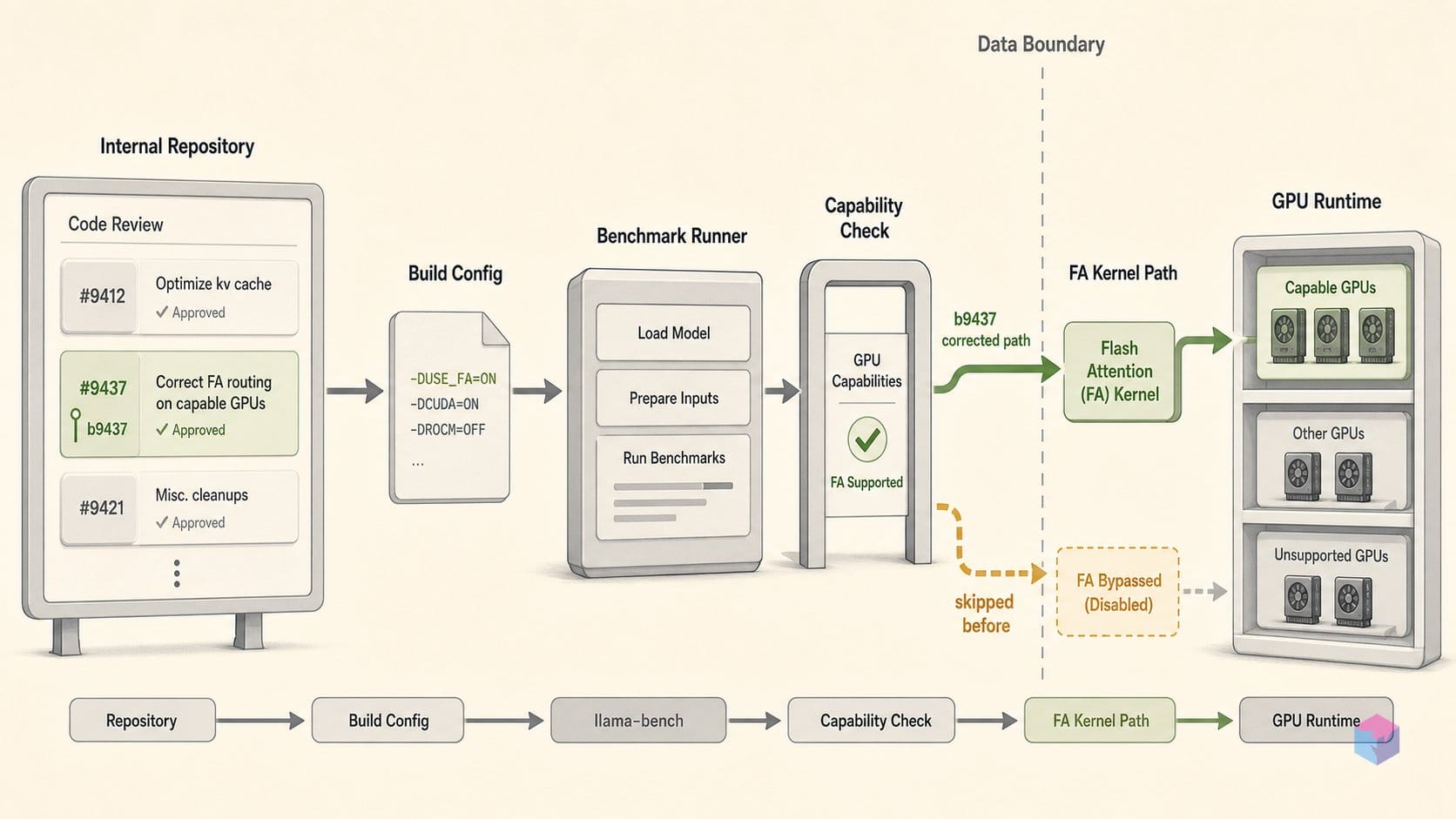
Any llama-bench run before b9437 used -fa off as the implicit default — even on hardware that fully supports flash attention. If you have recorded t/s numbers from those builds and your hardware supports FA, those figures captured the slower attention path without indicating it. To align old results with new defaults, either re-run old baselines with -fa off -ngl 99 (matching the original behavior) or re-run everything with -fa auto to get forward-comparable numbers. In either case, make the -fa state an explicit column in your benchmark output going forward.
The -ngl 99 legacy default also caused a quiet footgun on CPU-only hosts: with no -ngl flag set, the runtime attempted to load all 99 layers to GPU, triggering CUDA initialization errors even with no GPU present. With -ngl -1, the runtime skips GPU offload when no backend is detected, removing that noise from logs entirely.
Multi-Token Prediction gains for Qwen 3.6 27B dense — approximately 77 to 96 t/s on an RTX 4090 , a 24% throughput increase via PR #22673 — were measured in a separate context from b9437's defaults change. If you're trying to reproduce those figures, verify the -fa state from the original run; a mismatch gives you a result that is neither the clean MTP baseline nor a combined MTP+FA measurement.
What to explore beyond b9437

Three nearby builds are worth pulling alongside b9437:
- b9436 (May 30, 2026, 14:25 UTC) : The OpenCL backend gains BF16-via-FP16 conversion. If you run BF16-format models on AMD or Intel hardware via the OpenCL or Vulkan path, this expands compatibility without requiring native BF16 support in the GPU.
- b9439 (May 31, 2026, 06:57 UTC) : Multi-GPU hosts now default to using only one integrated GPU, preventing automatic selection of a low-performance iGPU alongside a discrete card. If you run a hybrid system — laptop with a discrete GPU and Intel UHD, for example — verify your device selection is still correct after updating.
- Multi-Token Prediction for Qwen 3.6 (PR #22673): Approximately 24% throughput gain on dense 27B models . Enable with
--mtp-n-draftand confirm your GGUF quant is compatible. MoE variants (Qwen 3.6 35B-A3B) show mixed results — expert-union verifier overhead can negate the gains on consumer hardware.
Frequently Asked Questions
What does -fa auto mean in llama-bench after b9437?
-fa auto sets flash attention to LLAMA_FLASH_ATTN_TYPE_AUTO, telling the runtime to enable flash attention when the backend supports it. Before b9437, llama-bench always defaulted to -fa off — unlike llama-server and llama-cli, which already had the tri-state auto|off|on flag. After b9437, all three tools use the same flag semantics.
Are pre-b9437 llama-bench numbers still valid?
Yes, with caveats. If your original run explicitly passed -fa off, or the host hardware does not support flash attention, the numbers remain comparable. If you relied on the default and ran on FA-capable hardware — CUDA, Metal, or Vulkan — those measurements were taken without flash attention even though the GPU supported it. Re-run with matched flags to produce a clean, apples-to-apples comparison.
Why did -ngl default to 99 instead of -1?
99 was a legacy sentinel meaning "offload all layers to GPU." The project later standardized -1 as the runtime-decides value across the toolchain. llama-bench was simply never updated to match until b9437 brought it into alignment with llama-server and llama-cli.
Do I need to recompile from source to get b9437?
Yes, for a local source build: pull the latest commit from ggml-org/llama.cpp and recompile. Tagged binary releases lag the continuous builds. Check the GitHub releases page for a pre-built artifact if you want to skip compilation, but verify the build number includes the b9437 changes before treating it as current.
Does -fa auto now behave the same across llama-bench, llama-cli, and llama-server?
Yes — b9437 closes the gap. llama-cli and llama-server already supported the -fa auto|off|on tri-state. b9437 brings llama-bench into parity, so flag semantics are now consistent across all three tools. A flag value you validated in llama-server means exactly the same thing when passed to llama-bench.
Rebaseline before your next regression run
After pulling b9437 or later, the immediate action is straightforward: re-baseline any llama-bench results used for regression tracking, and make the -fa state an explicit column in your output going forward. The default change is a minor toolchain alignment, but its effect on benchmark validity is concrete — any pre-b9437 run on CUDA, Metal, or Vulkan was silently measuring the slower attention path.
If you're on a multi-GPU system, pull at least b9439 alongside for the iGPU default fix. And if Qwen 3.6 throughput is in your test matrix, keep Multi-Token Prediction's --mtp-n-draft flag in scope — the roughly 24% gain on dense 27B is worth measuring, but MoE variant results vary enough that you'll want numbers from your own hardware and quant configuration.
Last updated: 2026-06-01. Based on llama.cpp continuous builds b9436–b9439 (May 30–31, 2026) .




